This article is about instruction sets. For other aspects of architecture, see Computer architecture.
In computer science, an instruction set architecture (ISA) is an abstract model of a computer. A device that executes instructions described by that ISA, such as a central processing unit (CPU), is called an implementation.
In general, an ISA defines the supported instructions, data types, registers, the hardware support for managing main memory, fundamental features (such as the memory consistency, addressing modes, virtual memory), and the input/output model of a family of implementations of the ISA.
An ISA specifies the behavior of machine code running on implementations of that ISA in a fashion that does not depend on the characteristics of that implementation, providing binary compatibility between implementations. This enables multiple implementations of an ISA that differ in characteristics such as performance, physical size, and monetary cost (among other things), but that are capable of running the same machine code, so that a lower-performance, lower-cost machine can be replaced with a higher-cost, higher-performance machine without having to replace software. It also enables the evolution of the microarchitectures of the implementations of that ISA, so that a newer, higher-performance implementation of an ISA can run software that runs on previous generations of implementations.
If an operating system maintains a standard and compatible application binary interface (ABI) for a particular ISA, machine code will run on future implementations of that ISA and operating system. However, if an ISA supports running multiple operating systems, it does not guarantee that machine code for one operating system will run on another operating system, unless the first operating system supports running machine code built for the other operating system.
An ISA can be extended by adding instructions or other capabilities, or adding support for larger addresses and data values; an implementation of the extended ISA will still be able to execute machine code for versions of the ISA without those extensions. Machine code using those extensions will only run on implementations that support those extensions.
The binary compatibility that they provide makes ISAs one of the most fundamental abstractions in computing.
Overview[edit]
An instruction set architecture is distinguished from a microarchitecture, which is the set of processor design techniques used, in a particular processor, to implement the instruction set. Processors with different microarchitectures can share a common instruction set. For example, the Intel Pentium and the AMD Athlon implement nearly identical versions of the x86 instruction set, but they have radically different internal designs.
The concept of an architecture, distinct from the design of a specific machine, was developed by Fred Brooks at IBM during the design phase of System/360.
Prior to NPL [System/360], the company’s computer designers had been free to honor cost objectives not only by selecting technologies but also by fashioning functional and architectural refinements. The SPREAD compatibility objective, in contrast, postulated a single architecture for a series of five processors spanning a wide range of cost and performance. None of the five engineering design teams could count on being able to bring about adjustments in architectural specifications as a way of easing difficulties in achieving cost and performance objectives.[1]: p.137
Some virtual machines that support bytecode as their ISA such as Smalltalk, the Java virtual machine, and Microsoft’s Common Language Runtime, implement this by translating the bytecode for commonly used code paths into native machine code. In addition, these virtual machines execute less frequently used code paths by interpretation (see: Just-in-time compilation). Transmeta implemented the x86 instruction set atop VLIW processors in this fashion.
Classification of ISAs[edit]
An ISA may be classified in a number of different ways. A common classification is by architectural complexity. A complex instruction set computer (CISC) has many specialized instructions, some of which may only be rarely used in practical programs. A reduced instruction set computer (RISC) simplifies the processor by efficiently implementing only the instructions that are frequently used in programs, while the less common operations are implemented as subroutines, having their resulting additional processor execution time offset by infrequent use.[2]
Other types include very long instruction word (VLIW) architectures, and the closely related long instruction word (LIW) and[citation needed] explicitly parallel instruction computing (EPIC) architectures. These architectures seek to exploit instruction-level parallelism with less hardware than RISC and CISC by making the compiler responsible for instruction issue and scheduling.[3]
Architectures with even less complexity have been studied, such as the minimal instruction set computer (MISC) and one-instruction set computer (OISC). These are theoretically important types, but have not been commercialized.[4][5]
Instructions[edit]
Machine language is built up from discrete statements or instructions. On the processing architecture, a given instruction may specify:
- opcode (the instruction to be performed) e.g. add, copy, test
- any explicit operands:
-
- registers
- literal/constant values
- addressing modes used to access memory
More complex operations are built up by combining these simple instructions, which are executed sequentially, or as otherwise directed by control flow instructions.
Instruction types[edit]
Examples of operations common to many instruction sets include:
Data handling and memory operations[edit]
- Set a register to a fixed constant value.
- Copy data from a memory location or a register to a memory location or a register (a machine instruction is often called move; however, the term is misleading). They are used to store the contents of a register, the contents of another memory location or the result of a computation, or to retrieve stored data to perform a computation on it later. They are often called load and store operations.
- Read and write data from hardware devices.
Arithmetic and logic operations[edit]
- Add, subtract, multiply, or divide the values of two registers, placing the result in a register, possibly setting one or more condition codes in a status register.[6]
- increment, decrement in some ISAs, saving operand fetch in trivial cases.
- Perform bitwise operations, e.g., taking the conjunction and disjunction of corresponding bits in a pair of registers, taking the negation of each bit in a register.
- Compare two values in registers (for example, to see if one is less, or if they are equal).
- Floating-point instructions for arithmetic on floating-point numbers.[6]
Control flow operations[edit]
- Branch to another location in the program and execute instructions there.
- Conditionally branch to another location if a certain condition holds.
- Indirectly branch to another location.
- Call another block of code, while saving the location of the next instruction as a point to return to.
Coprocessor instructions[edit]
- Load/store data to and from a coprocessor or exchanging with CPU registers.
- Perform coprocessor operations.
Complex instructions[edit]
Processors may include «complex» instructions in their instruction set. A single «complex» instruction does something that may take many instructions on other computers. Such instructions are typified by instructions that take multiple steps, control multiple functional units, or otherwise appear on a larger scale than the bulk of simple instructions implemented by the given processor. Some examples of «complex» instructions include:
- transferring multiple registers to or from memory (especially the stack) at once
- moving large blocks of memory (e.g. string copy or DMA transfer)
- complicated integer and floating-point arithmetic (e.g. square root, or transcendental functions such as logarithm, sine, cosine, etc.)
- SIMD instructions, a single instruction performing an operation on many homogeneous values in parallel, possibly in dedicated SIMD registers
- performing an atomic test-and-set instruction or other read-modify-write atomic instruction
- instructions that perform ALU operations with an operand from memory rather than a register
Complex instructions are more common in CISC instruction sets than in RISC instruction sets, but RISC instruction sets may include them as well. RISC instruction sets generally do not include ALU operations with memory operands, or instructions to move large blocks of memory, but most RISC instruction sets include SIMD or vector instructions that perform the same arithmetic operation on multiple pieces of data at the same time. SIMD instructions have the ability of manipulating large vectors and matrices in minimal time. SIMD instructions allow easy parallelization of algorithms commonly involved in sound, image, and video processing. Various SIMD implementations have been brought to market under trade names such as MMX, 3DNow!, and AltiVec.
Instruction encoding[edit]

On traditional architectures, an instruction includes an opcode that specifies the operation to perform, such as add contents of memory to register—and zero or more operand specifiers, which may specify registers, memory locations, or literal data. The operand specifiers may have addressing modes determining their meaning or may be in fixed fields. In very long instruction word (VLIW) architectures, which include many microcode architectures, multiple simultaneous opcodes and operands are specified in a single instruction.
Some exotic instruction sets do not have an opcode field, such as transport triggered architectures (TTA), only operand(s).
Most stack machines have «0-operand» instruction sets in which arithmetic and logical operations lack any operand specifier fields; only instructions that push operands onto the evaluation stack or that pop operands from the stack into variables have operand specifiers. The instruction set carries out most ALU actions with postfix (reverse Polish notation) operations that work only on the expression stack, not on data registers or arbitrary main memory cells. This can be very convenient for compiling high-level languages, because most arithmetic expressions can be easily translated into postfix notation.[7]
Conditional instructions often have a predicate field—a few bits that encode the specific condition to cause an operation to be performed rather than not performed. For example, a conditional branch instruction will transfer control if the condition is true, so that execution proceeds to a different part of the program, and not transfer control if the condition is false, so that execution continues sequentially. Some instruction sets also have conditional moves, so that the move will be executed, and the data stored in the target location, if the condition is true, and not executed, and the target location not modified, if the condition is false. Similarly, IBM z/Architecture has a conditional store instruction. A few instruction sets include a predicate field in every instruction; this is called branch predication.
Number of operands[edit]
Instruction sets may be categorized by the maximum number of operands explicitly specified in instructions.
(In the examples that follow, a, b, and c are (direct or calculated) addresses referring to memory cells, while reg1 and so on refer to machine registers.)
C = A+B
- 0-operand (zero-address machines), so called stack machines: All arithmetic operations take place using the top one or two positions on the stack:[8]
push a,push b,add,pop c.C = A+Bneeds four instructions.[9] For stack machines, the terms «0-operand» and «zero-address» apply to arithmetic instructions, but not to all instructions, as 1-operand push and pop instructions are used to access memory.
- 1-operand (one-address machines), so called accumulator machines, include early computers and many small microcontrollers: most instructions specify a single right operand (that is, constant, a register, or a memory location), with the implicit accumulator as the left operand (and the destination if there is one):
load a,add b,store c.C = A+Bneeds three instructions.[9]
- 2-operand — many CISC and RISC machines fall under this category:
- CISC —
move Ato C; thenadd Bto C.C = A+Bneeds two instructions. This effectively ‘stores’ the result without an explicit store instruction.
- CISC — Often machines are limited to one memory operand per instruction:
load a,reg1;add b,reg1;store reg1,c; This requires a load/store pair for any memory movement regardless of whether theaddresult is an augmentation stored to a different place, as inC = A+B, or the same memory location:A = A+B.C = A+Bneeds three instructions.
- RISC — Requiring explicit memory loads, the instructions would be:
load a,reg1;load b,reg2;add reg1,reg2;store reg2,c.C = A+Bneeds four instructions.
- CISC —
- 3-operand, allowing better reuse of data:[10]
- CISC — It becomes either a single instruction:
add a,b,cC = A+Bneeds one instruction.
- CISC — Or, on machines limited to two memory operands per instruction,
move a,reg1;add reg1,b,c;C = A+Bneeds two instructions.
- RISC — arithmetic instructions use registers only, so explicit 2-operand load/store instructions are needed:
load a,reg1;load b,reg2;add reg1+reg2->reg3;store reg3,c;C = A+Bneeds four instructions.- Unlike 2-operand or 1-operand, this leaves all three values a, b, and c in registers available for further reuse.[10]
- CISC — It becomes either a single instruction:
- more operands—some CISC machines permit a variety of addressing modes that allow more than 3 operands (registers or memory accesses), such as the VAX «POLY» polynomial evaluation instruction.
Due to the large number of bits needed to encode the three registers of a 3-operand instruction, RISC architectures that have 16-bit instructions are invariably 2-operand designs, such as the Atmel AVR, TI MSP430, and some versions of ARM Thumb. RISC architectures that have 32-bit instructions are usually 3-operand designs, such as the ARM, AVR32, MIPS, Power ISA, and SPARC architectures.
Each instruction specifies some number of operands (registers, memory locations, or immediate values) explicitly. Some instructions give one or both operands implicitly, such as by being stored on top of the stack or in an implicit register. If some of the operands are given implicitly, fewer operands need be specified in the instruction. When a «destination operand» explicitly specifies the destination, an additional operand must be supplied. Consequently, the number of operands encoded in an instruction may differ from the mathematically necessary number of arguments for a logical or arithmetic operation (the arity). Operands are either encoded in the «opcode» representation of the instruction, or else are given as values or addresses following the opcode.
Register pressure[edit]
Register pressure measures the availability of free registers at any point in time during the program execution. Register pressure is high when a large number of the available registers are in use; thus, the higher the register pressure, the more often the register contents must be spilled into memory. Increasing the number of registers in an architecture decreases register pressure but increases the cost.[11]
While embedded instruction sets such as Thumb suffer from extremely high register pressure because they have small register sets, general-purpose RISC ISAs like MIPS and Alpha enjoy low register pressure. CISC ISAs like x86-64 offer low register pressure despite having smaller register sets. This is due to the many addressing modes and optimizations (such as sub-register addressing, memory operands in ALU instructions, absolute addressing, PC-relative addressing, and register-to-register spills) that CISC ISAs offer.[12]
Instruction length[edit]
The size or length of an instruction varies widely, from as little as four bits in some microcontrollers to many hundreds of bits in some VLIW systems. Processors used in personal computers, mainframes, and supercomputers have minimum instruction sizes between 8 and 64 bits. The longest possible instruction on x86 is 15 bytes (120 bits).[13] Within an instruction set, different instructions may have different lengths. In some architectures, notably most reduced instruction set computers (RISC), instructions are a fixed length, typically corresponding with that architecture’s word size. In other architectures, instructions have variable length, typically integral multiples of a byte or a halfword. Some, such as the ARM with Thumb-extension have mixed variable encoding, that is two fixed, usually 32-bit and 16-bit encodings, where instructions cannot be mixed freely but must be switched between on a branch (or exception boundary in ARMv8).
Fixed-length instructions are less complicated to handle than variable-length instructions for several reasons (not having to check whether an instruction straddles a cache line or virtual memory page boundary,[10] for instance), and are therefore somewhat easier to optimize for speed.
Code density[edit]
In early 1960s computers, main memory was expensive and very limited, even on mainframes. Minimizing the size of a program to make sure it would fit in the limited memory was often central. Thus the size of the instructions needed to perform a particular task, the code density, was an important characteristic of any instruction set. It remained important on the initially-tiny memories of minicomputers and then microprocessors. Density remains important today, for smartphone applications, applications downloaded into browsers over slow Internet connections, and in ROMs for embedded applications. A more general advantage of increased density is improved effectiveness of caches and instruction prefetch.
Computers with high code density often have complex instructions for procedure entry, parameterized returns, loops, etc. (therefore retroactively named Complex Instruction Set Computers, CISC). However, more typical, or frequent, «CISC» instructions merely combine a basic ALU operation, such as «add», with the access of one or more operands in memory (using addressing modes such as direct, indirect, indexed, etc.). Certain architectures may allow two or three operands (including the result) directly in memory or may be able to perform functions such as automatic pointer increment, etc. Software-implemented instruction sets may have even more complex and powerful instructions.
Reduced instruction-set computers, RISC, were first widely implemented during a period of rapidly growing memory subsystems. They sacrifice code density to simplify implementation circuitry, and try to increase performance via higher clock frequencies and more registers. A single RISC instruction typically performs only a single operation, such as an «add» of registers or a «load» from a memory location into a register. A RISC instruction set normally has a fixed instruction length, whereas a typical CISC instruction set has instructions of widely varying length. However, as RISC computers normally require more and often longer instructions to implement a given task, they inherently make less optimal use of bus bandwidth and cache memories.
Certain embedded RISC ISAs like Thumb and AVR32 typically exhibit very high density owing to a technique called code compression. This technique packs two 16-bit instructions into one 32-bit word, which is then unpacked at the decode stage and executed as two instructions.[14]
Minimal instruction set computers (MISC) are commonly a form of stack machine, where there are few separate instructions (8–32), so that multiple instructions can be fit into a single machine word. These types of cores often take little silicon to implement, so they can be easily realized in an FPGA or in a multi-core form. The code density of MISC is similar to the code density of RISC; the increased instruction density is offset by requiring more of the primitive instructions to do a task.[15][failed verification]
There has been research into executable compression as a mechanism for improving code density. The mathematics of Kolmogorov complexity describes the challenges and limits of this.
In practice, code density is also dependent on the compiler. Most optimizing compilers have options that control whether to optimize code generation for execution speed or for code density. For instance GCC has the option -Os to optimize for small machine code size, and -O3 to optimize for execution speed at the cost of larger machine code.
Representation[edit]
The instructions constituting a program are rarely specified using their internal, numeric form (machine code); they may be specified by programmers using an assembly language or, more commonly, may be generated from high-level programming languages by compilers.[16]
Design[edit]
The design of instruction sets is a complex issue. There were two stages in history for the microprocessor. The first was the CISC (Complex Instruction Set Computer), which had many different instructions. In the 1970s, however, places like IBM did research and found that many instructions in the set could be eliminated. The result was the RISC (Reduced Instruction Set Computer), an architecture that uses a smaller set of instructions. A simpler instruction set may offer the potential for higher speeds, reduced processor size, and reduced power consumption. However, a more complex set may optimize common operations, improve memory and cache efficiency, or simplify programming.
Some instruction set designers reserve one or more opcodes for some kind of system call or software interrupt. For example, MOS Technology 6502 uses 00H, Zilog Z80 uses the eight codes C7,CF,D7,DF,E7,EF,F7,FFH[17] while Motorola 68000 use codes in the range A000..AFFFH.
Fast virtual machines are much easier to implement if an instruction set meets the Popek and Goldberg virtualization requirements.[clarification needed]
The NOP slide used in immunity-aware programming is much easier to implement if the «unprogrammed» state of the memory is interpreted as a NOP.[dubious – discuss]
On systems with multiple processors, non-blocking synchronization algorithms are much easier to implement[citation needed] if the instruction set includes support for something such as «fetch-and-add», «load-link/store-conditional» (LL/SC), or «atomic compare-and-swap».
Instruction set implementation[edit]
A given instruction set can be implemented in a variety of ways. All ways of implementing a particular instruction set provide the same programming model, and all implementations of that instruction set are able to run the same executables. The various ways of implementing an instruction set give different tradeoffs between cost, performance, power consumption, size, etc.
When designing the microarchitecture of a processor, engineers use blocks of «hard-wired» electronic circuitry (often designed separately) such as adders, multiplexers, counters, registers, ALUs, etc. Some kind of register transfer language is then often used to describe the decoding and sequencing of each instruction of an ISA using this physical microarchitecture.
There are two basic ways to build a control unit to implement this description (although many designs use middle ways or compromises):
- Some computer designs «hardwire» the complete instruction set decoding and sequencing (just like the rest of the microarchitecture).
- Other designs employ microcode routines or tables (or both) to do this, using ROMs or writable RAMs (writable control store), PLAs, or both.
Some microcoded CPU designs with a writable control store use it to allow the instruction set to be changed (for example, the Rekursiv processor and the Imsys Cjip).[18]
CPUs designed for reconfigurable computing may use field-programmable gate arrays (FPGAs).
An ISA can also be emulated in software by an interpreter. Naturally, due to the interpretation overhead, this is slower than directly running programs on the emulated hardware, unless the hardware running the emulator is an order of magnitude faster. Today, it is common practice for vendors of new ISAs or microarchitectures to make software emulators available to software developers before the hardware implementation is ready.
Often the details of the implementation have a strong influence on the particular instructions selected for the instruction set. For example, many implementations of the instruction pipeline only allow a single memory load or memory store per instruction, leading to a load–store architecture (RISC). For another example, some early ways of implementing the instruction pipeline led to a delay slot.
The demands of high-speed digital signal processing have pushed in the opposite direction—forcing instructions to be implemented in a particular way. For example, to perform digital filters fast enough, the MAC instruction in a typical digital signal processor (DSP) must use a kind of Harvard architecture that can fetch an instruction and two data words simultaneously, and it requires a single-cycle multiply–accumulate multiplier.
See also[edit]
- Comparison of instruction set architectures
- Computer architecture
- Processor design
- Compressed instruction set
- Emulator
- Simulation
- Instruction set simulator
- OVPsim full systems simulator providing ability to create/model/emulate any instruction set using C and standard APIs
- Register transfer language (RTL)
- Micro-operation
References[edit]
- ^ Pugh, Emerson W.; Johnson, Lyle R.; Palmer, John H. (1991). IBM’s 360 and Early 370 Systems. MIT Press. ISBN 0-262-16123-0.
- ^ Crystal Chen; Greg Novick; Kirk Shimano (December 16, 2006). «RISC Architecture: RISC vs. CISC». cs.stanford.edu. Retrieved February 21, 2015.
- ^ Schlansker, Michael S.; Rau, B. Ramakrishna (February 2000). «EPIC: Explicitly Parallel Instruction Computing». Computer. 33 (2). doi:10.1109/2.820037.
- ^ Shaout, Adnan; Eldos, Taisir (Summer 2003). «On the Classification of Computer Architecture». International Journal of Science and Technology. 14: 3. Retrieved March 2, 2023.
- ^ Gilreath, William F.; Laplante, Phillip A. (December 6, 2012). Computer Architecture: A Minimalist Perspective. Springer Science+Business Media. ISBN 978-1-4615-0237-1.
- ^ a b Hennessy & Patterson 2003, p. 108.
- ^ Durand, Paul. «Instruction Set Architecture (ISA)». Introduction to Computer Science CS 0.
- ^ Hennessy & Patterson 2003, p. 92.
- ^ a b Hennessy & Patterson 2003, p. 93.
- ^ a b c
Cocke, John; Markstein, Victoria (January 1990). «The evolution of RISC technology at IBM» (PDF). IBM Journal of Research and Development. 34 (1): 4–11. doi:10.1147/rd.341.0004. Retrieved 2022-10-05. - ^ Page, Daniel (2009). «11. Compilers». A Practical Introduction to Computer Architecture. Springer. p. 464. Bibcode:2009pica.book…..P. ISBN 978-1-84882-255-9.
- ^ Venkat, Ashish; Tullsen, Dean M. (2014). Harnessing ISA Diversity: Design of a Heterogeneous-ISA Chip Multiprocessor. 41st Annual International Symposium on Computer Architecture.
- ^ «Intel® 64 and IA-32 Architectures Software Developer’s Manual». Intel Corporation. Retrieved 5 October 2022.
- ^ Weaver, Vincent M.; McKee, Sally A. (2009). Code density concerns for new architectures. IEEE International Conference on Computer Design. CiteSeerX 10.1.1.398.1967. doi:10.1109/ICCD.2009.5413117.
- ^ «RISC vs. CISC». cs.stanford.edu. Retrieved 2021-12-18.
- ^ Hennessy & Patterson 2003, p. 120.
- ^ Ganssle, Jack (February 26, 2001). «Proactive Debugging». embedded.com.
- ^ «Great Microprocessors of the Past and Present (V 13.4.0)». cpushack.net. Retrieved 2014-07-25.
Further reading[edit]
- Bowen, Jonathan P. (July–August 1985). «Standard Microprocessor Programming Cards». Microprocessors and Microsystems. 9 (6): 274–290. doi:10.1016/0141-9331(85)90116-4.
- Hennessy, John L.; Patterson, David A. (2003). Computer Architecture: A Quantitative Approach (Third ed.). Morgan Kaufmann Publishers. ISBN 1-55860-724-2. Retrieved 2023-03-04.
External links[edit]
![]()
 Media related to Instruction set architectures at Wikimedia Commons
Media related to Instruction set architectures at Wikimedia Commons- Programming Textfiles: Bowen’s Instruction Summary Cards
- Mark Smotherman’s Historical Computer Designs Page
Для
получения результата вычислений
компьютер выполняет машинную программу,
т.е. последовательность
команд, в
виде которой записан алгоритм обработки.
Команда
компьютера представляет собой двоичный
код, определяющий как выполняемую
операцию, так и необходимые для этого
данные, или операнды.
Большинство команд содержит адрес, т.е.
номер регистра или ячейки памяти, где
сохраняется результат выполнения
операции. Помимо этого, для выполнения
программы нужно также знать адрес
следующей исполняемой команды.
Обычно
различают следующие группы команд:
-
команды
арифметических операций над числами
с фиксированной точкой, -
команды
логических операций, -
команды
арифметических операций над числами
с плавающей точкой, -
команды
операций ввода-вывода, -
команды
управления (управления циклами, условные
и безусловные переходы и т.п.) и т.д.
Каждый
тип компьютера обладает собственной
системой
команд, т.е.
в нем существует аппаратура или память
микропрограмм, призванная вырабатывать
управляющие сигналы для реализации
командных операций. Естественно, что
для выполнения конкретной программы
необходим компьютер, способный выполнять
команды, составляющие эту программу.
При разработке новых компьютеров
стремятся сохранить их преемственность;
для этого компьютеры выполняют «программно
совместимыми». Программная совместимость
означает, прежде всего, наличие одинаковых
систем команд. Однако во многих случаях
систему команд «расширяют», т.е. добавляют
дополнительные операции, сохраняя при
этом формат команд. Это значит, что новая
машина может выполнять все программы,
составленные для прежних компьютеров,
но программы, в которых используются
дополнительные команды, не могут
выполняться компьютерами старых моделей.
Такую совместимость называют обратной.
Команда,
или инструкция (под инструкцией часто
понимают конструкцию языка более
высокого уровня, но в переводной
литературе этот термин используют в
качестве синонима термину команда)
представляет собой слово, содержащее
код выполняемой операции и адреса
операндов. Код команды включает несколько
полей (поле – последовательность бит,
содержащая определенный тип информации).
Обычно команда состоит из операционной
и адресной частей. В операционной части
размещается код операции, а в адресной
части – адреса операндов, т.е. информация
о местонахождении обрабатываемых данных
и получаемого результата.
Формат
команды – это структура полей ее кода
с указанием номеров разрядов, определяющих
границы полей. В «больших» машинах,
например, IBM
370 или ЕС ЭВМ, код операции в команде
занимал 8 разрядов, а число различных
операций составляло не более 256. Остальные
разряды, а команды представляли собой
слово размером 16, 32 или 48 разрядов,
отводились под адреса операндов.
В
различных машинах число адресных полей
в команде может составлять от одного
до четырех. Структура четырехадресной
команды приведена на рисунке 5.1.
КОп
А1 А2 А3 А4




Рисунок
5.1 Структура четырехадресной команды
В
такой команде первое поле кода операции
(КОп) служит для кодирования выполняемой
операции. Это поле «расшифровывается»
логическими схемами или посредством
микропрограммы и формируются управляющие
сигналы для выполнения соответствующих
этой операции действий. Затем располагаются
четыре адресных поля: А1 – содержит
адрес первого операнда, А2 – адрес
второго операнда, А3 – адрес ячейки
памяти, отведенной для записи результата
операции, А4 – адрес ячейки, где находится
следующая команда. Но такая четырехадресная
команда занимает слишком много места
в памяти компьютера, поэтому они в
настоящее время не находят применения.
Сегодня
наибольшее распространение имеют одно-,
двух- и трехадресные команды, структуры
которых приведены на рисунке 5.2.
Трехадресные
команды характерны для компьютеров с
сокращенным набором команд. В трехадресной
команде первый и второй адреса указывают
месторасположение операндов, в третий
адрес – ячейку памяти, куда заносится
результат операции.
КОп
А1 А2 А3



КОп
А1 А2


КОп
А1 А2

Рисунок
5.2 Структуры одно-, двух- и трехадресных
команд
В
таких машинах для определения адреса
следующей выполняемой команды служит
счетчик команд (IP),
к содержимому которого после выполнения
любой команды добавляется ее длина в
байтах. Для перехода к выполнению
команды, которая занимает не следующую
по порядку ячейку памяти, в машине
предусматривают специальные команды
переходов. Трехадресные команды
используются в так называемых RISC
компьютерах (машинах с сокращенным
набором команд); в них операнды размещают
в регистрах общего назначения (РОН),
число которых может достигать 256. Загрузка
этих регистров из памяти осуществляется
специальной схемой, называемой
контроллером или процессором загрузки.
Наиболее
распространены в настоящее время
двухадресные компьютеры. Это машины,
команды в которых содержат не более
двух адресов. Можно представить, что
оба операнда находятся в регистрах, а
результат выполнения операции мы также
будем записывать в регистр. Тогда такую
команду принято называть командой
RR-типа
(регистр-регистр). Если один операнд
находится в регистре, а второй в ячейке
памяти, адрес которой индексируется,
то такая команда относится к RX-типу.
Команда, второй операнд которой находится
в ячейке памяти без индексации, а первый
в регистре, носит название RS-типа.
В
команде может находиться не адрес
операнда, а сам операнд (этот операнд
называют непосредственным адресом, и
он представляет константу), такую команду
относят к SI-типу.
Наконец, оба операнда могут находиться
в памяти, для их вызова используют
команду SS-типа.
Такие команды использовались в машинах
IBM/370
и ЕС ЭВМ.
В
персональном компьютере IBM
PC
команды также двухадресные, но первый
операнд всегда находится в одном из
восьми регистров, а второй может
находиться в регистре, памяти или
непосредственно в самой команде. Помимо
кода операции и адресов операндов
команда этого компьютера содержит бит,
указывающий направление передачи
результата (d),
бит ширины операнда (w),
а также поле указания режима (md)
и поле регистр/память (r/m).
В
одноадресной машине команда содержит
только один адрес, а поскольку обычно
в арифметической операции используется
два операнда, то второй уже находится
в одном из регистров процессора. Результат
операции всегда сохраняется в выходном
регистре процессора, который называют
аккумулятором. Очевидно, что для сложения
двух чисел нужно выполнить три одноадресных
команды: поместить первый операнд из
памяти в регистр процессора, передать
второй операнд из памяти и сложить его
с первым, а затем сохранить результат
в памяти. Однако на практике при выполнении
программы никогда не приходится
использовать все три команды. В регистре
процессора сохраняется один из операндов,
полученный при выполнении предыдущей
операции (т.е. первая команда не нужна),
а результат сложения будет использован
следующей командой (т.е. не нужно его
сохранять в памяти).
Приведенные
на рисунке 5.2 форматы команд весьма
схематичны. В действительности в адресных
полях находятся не сами адреса, а
информация, позволяющая их определить.
Способ определения исполнительного
адреса Аи
(т.е. адреса ячейки памяти, где находится
операнд или команда) по адресу в коде
команды Ак
будем называть способом адресации.
Для
указания способа адресации в некоторых
системах команд используется специальное
поле; это позволяет выполнять одну и ту
же команду с любым предусмотренным
способом адресации, но значительно
увеличивает длину команды.
Способы
адресации
Обычно
в команде имеются поля, указывающие
адрес операнда Ак.
В этом
случае адресацию называют явной.
Однако иногда адресное поле в команде
отсутствует, а информацию об адресе
операнда несет сам код операции. Такую
адресацию называют неявной.
Ее используют при работе над содержимым
аккумулятора или над флагами. [Флагами
называют признаки результата, которые
при выполнении каждой операции заносятся
в специальный регистр. Примерами могут
служить флаги переполнения, четности
и т.п. Общее число флагов зависит от
конкретного процессора.] Однако наиболее
часто используется явная адресация.
Время
обращения в память сказывается на общей
производительности компьютера, поэтому,
чем меньше таких обращений, тем лучше
с позиций быстродействия. Если нужно
произвести действие с постоянным
операндом, значение которого известно
в момент трансляции программы, то нет
необходимости хранить его в отдельной
ячейке памяти; его можно поместить в
адресном поле самой команды. Такой
способ задания операнда принято называть
непосредственной
адресацией. Она применяется для задания
констант, длина которых меньше адресного
поля команды.
Операнды
могут находиться и в регистровой, и в
оперативной памяти; время обращения
зависит от их местоположения. Если
операнд находится в регистровой памяти,
то время обращения к нему невелико.
Именно с целью сокращения времени на
обращение к операндам и используют
регистровую
адресацию. Регистровая адресация в
машине IBM
PC
реализуется при md
= 1. Адрес одного из восьми регистров, в
котором размещается операнд, определяется
полем r/m.
Операнд может занимать весь регистр
или только его половину в зависимости
от значения «w».
Наиболее
часто используется прямая
адресация. Операнд находится в ОП, а в
команде указывается его исполнительный
адрес (адресный код команды Ак
совпадает с исполнительным адресом
Аи).
В компьютерах IBM
PC
в этом поле команды находится не полный
адрес, а только так называемое смещение,
т.е. 16-битная часть исполнительного
адреса. В одном из адресных регистров
находится адрес сегмента; исполнительный
адрес определяется сложением номера
(адреса) сегмента и смещения. Этим удалось
избежать самого крупного недостатка
прямой адресации, а именно, необходимости
слишком длинного адресного поля при
большой емкости памяти.
При
косвенной
адресации в адресном поле команды
указывается адрес регистра или ячейки
памяти, где находится адрес операнда;
этот адрес называют указателем.
В случае, когда указатель располагается
в регистре, адресацию называют косвенной
регистровой,
рисунок 5.3.
Адрес
указателя в команде компьютера остается
неизменным, но, меняя сами указатели,
можно осуществлять переадресацию
данных, что упрощает обработку массивов
и списковых структур.
КОп
Адрес указателя

ОП
указатель
операнд









Рисунок
5.3 Косвенная адресация
Часто
адрес ячейки памяти образуется из
нескольких составляющих частей, например,
базового адреса (или базы B),
индекса (X)
и смещения (D).
В этих случаях различают базовую,
индексную и базово-индексную адресацию.
Если адрес, указанный в команде, состоит
из двух частей – АB
и АСМ,
то полный адрес ячейки памяти определяется
суммированием содержимого регистра
АB,
где хранится «база», и смещения АСМ,
рисунок 5.4.
КОп АB
АСМ




База





 РП
РП



∑
Операнд

ОП



Рисунок
5.4 Формирование адреса памяти при базовой
адресации
Базовая
адресация широко используется при
создании программ, состоящих из
перемещаемых модулей. Базовый (начальный)
адрес загружается в регистр, а остальные
адреса данного модуля определяются
сложением базы и смещения. Это значит,
что любая программа может работать с
данными, располагаемыми в любой области
памяти; для этого нужно изменить только
базу.
Аналогично
выполняется и индексная
адресация.
Однако после выполнения обращения к
ячейке памяти с адресом A
= (AX)
+ A
СМ
производится увеличение индекса X,
записанного в индексном регистре, на
единицу. Так «автоматически» определяется
адрес следующего подлежащего обработке
элемента в массиве. Использование
индексной адресации упрощает создание
циклических программ.
Часто
используют комбинированную базово-индексную
адресацию. В этом случае адрес ячейки
памяти определяется суммой содержимого
регистров базы и индекса, а также
смещения, содержащегося в команде,
рисунок 5.5. Иногда используют не сложение,
а «сцепление» кодов базы, индекса и
смещения. Это значит, что исполнительный
адрес A
= AB,AX,AСМ.
Для
определения адреса следующей команды
в IBM
PC
может быть использована относительная
адресация.
В этом
случае адрес очередной команды
представляет собой сумму текущего
значения счетчика команд (IP)
и смещения из предыдущей команды.
Все
виды адресации в компьютере IBM
PC
определяют место расположения и способ
нахождения адреса второго операнда;
первый операнд всегда находится в одном
из регистров. Для компьютеров IBM
PC
многочисленные способы адресации
отчасти достались «по наследству» от
ранних моделей микропроцессоров, когда
разрядность была ограничена.
КОп АB АX
AСМ












Индекс
База



 РП
РП







Операнд
ОП





Рисунок
5.5 Формирование адреса памяти при базовой
индексной адресации
Выбору
реализуемой компьютером системы команд
должно уделяться самое серьезное
внимание. Каждая аппаратно реализуемая
операция, входящая в систему команд,
выполняется быстрее, чем аналогичная
операция, не входящая в систему команд
и, следовательно, реализуемая в виде
подпрограммы. На первый взгляд из этого
следует, что увеличение аппаратно
реализуемых операций, т.е. расширение
системы команд, может привести к повышению
быстродействия машины. Это положение
положено в основу концепции архитектуры
компьютера с расширенным набором команд
– CISC
архитектур. Однако в силу ряда причин
расширение системы команд может приводить
и к обратным результатам. Именно это
обстоятельство и послужило толчком для
разработки машин с сокращенным набором
команд – RISC
архитектур. Эти архитектуры рассмотрены
ниже.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Набор команд — это группа команд для ЦП на машинном языке. … Все процессоры имеют наборы команд, которые позволяют процессору команды переключать соответствующие транзисторы. Некоторые инструкции представляют собой простые команды чтения, записи и перемещения, которые направляют данные на другое оборудование.
Содержание
- 1 Что подразумевается под набором инструкций?
- 2 Где находится набор инструкций в процессоре?
- 3 Какие бывают типы наборов инструкций?
- 4 Что такое компьютер ISA?
- 5 Что такое инструкция с примером?
- 6 Каковы три типа банковских инструкций?
- 7 Что такое 32-битный набор инструкций?
- 8 Что означает RISC?
- 9 Как инструкция выполняется процессором?
- 10 Какие 5 типов командных операций?
- 11 Сколько существует видов обучения?
- 12 Как написать набор инструкций?
- 13 Что такое полная форма ISA?
- 14 Какие 5 этапов конвейерной обработки?
- 15 Что такое RISC против CISC?
Что подразумевается под набором инструкций?
Набор инструкций или архитектура набора инструкций (ISA) — это список всех команд (инструкций) со всеми их вариациями, которые может выполнять процессор. Инструкции включают: арифметические операции, такие как сложение и вычитание.
Где находится набор инструкций в процессоре?
Набор инструкций встроен в ЦП … на самом деле это результат того, как построена схема, на самом деле нет места, где хранятся инструкции. Когда компьютер запускается, на ПЗУ есть небольшая программа, которая знает, как инициализировать все компоненты и загрузить ОС.
Какие бывают типы наборов инструкций?
7 типов наборов инструкций
- Компьютер с сокращенным набором команд (RISC)
- Компьютер со сложной системой команд (CISC)
- Компьютеры с минимальным набором команд (MISC)
- Очень длинное командное слово (VLIW)
- Явно параллельное вычисление инструкций (EPIC)
- Компьютер с одним набором команд (OISC)
- Компьютер с нулевым набором команд (ZISC)
Что такое компьютер ISA?
Архитектура набора команд (ISA) — это протокол, который определяет, как вычислительная машина выглядит для программиста или компилятора машинного языка. ISA описывает (1) модель памяти, (2) формат команд, типы и режимы и (3) регистры операндов, типы и адресацию данных.
Что такое инструкция с примером?
Определение обучения — это акт обучения, указания шагов, которым необходимо следовать, или приказа. Примером инструкции является то, что кто-то дает другому человеку подробные указания в библиотеку.
Каковы три типа банковских инструкций?
Три категории инструкций:
- Арифметические манипуляции: сложение, подпрограмма, мульти, деление и т. Д.
- Логика и битовые манипуляции: and, or, nor, xor и т. Д.
- Сдвиг и вращение (вправо или влево): sll, srl, sra, rol, ror и т. Д.
Что такое 32-битный набор инструкций?
Программа, написанная на машинном языке, представляет собой серию 32-битных чисел, представляющих инструкции. Как и другие двоичные числа, эти инструкции могут храниться в памяти. Это называется концепцией хранимой программы, и это ключевая причина того, почему компьютеры такие мощные.
Что означает RISC?
RISC, или компьютер с сокращенным набором команд. представляет собой тип микропроцессорной архитектуры, в которой используется небольшой, высоко оптимизированный набор инструкций, а не более специализированный набор инструкций, часто встречающийся в других типах архитектур.
Как инструкция выполняется процессором?
Этап выполнения: блок управления ЦП передает декодированную информацию в виде последовательности управляющих сигналов соответствующим функциональным блокам ЦП для выполнения действий, требуемых инструкцией, таких как чтение значений из регистров, передача их в АЛУ для выполнения математические или логические функции на них, …
Какие 5 типов командных операций?
Типы операций
- Обмен данными.
- Арифметика.
- Логично.
- Конверсия.
- Ввод / вывод.
- Системный контроль.
- Передача управления.
Сколько существует видов обучения?
Инструкция бывает разной длины в зависимости от количества содержащихся в ней адресов. Обычно организация ЦП бывает трех типов в зависимости от количества полей адреса: Организация с единым накопителем. Организация общего реестра.
Как написать набор инструкций?
Контрольный список для написания инструкций
- Используйте короткие предложения и короткие абзацы.
- Расставьте свои точки в логическом порядке.
- Сделайте свои заявления конкретными.
- Используйте повелительный настрой.
- Ставьте самое важное в каждое предложение в начале.
- В каждом предложении говорите одно.
26 июл. 2019 г.
Что такое полная форма ISA?
Промышленная стандартная архитектура (ISA) — это 16-разрядная внутренняя шина IBM PC / AT и аналогичных компьютеров, основанных на Intel 80286 и его ближайших преемниках в 1980-х годах.
Какие 5 этапов конвейерной обработки?
Ниже приведены 5 этапов конвейера RISC с соответствующими операциями:
- Этап 1 (Получение инструкции) …
- Этап 2 (декодирование инструкций) …
- Этап 3 (Выполнение инструкции) …
- Этап 4 (доступ к памяти) …
- Этап 5 (обратная запись)
5 апр. 2019 г.
Что такое RISC против CISC?
Машины на основе RISC выполняют одну инструкцию за такт. Машины CISC могут иметь специальные инструкции, а также инструкции, выполнение которых занимает более одного цикла. … Архитектура CISC может выполнять одну, хотя и более сложную инструкцию, которая выполняет одни и те же операции, все сразу, непосредственно с памятью.

Дмитрий Михайлович Беляев
Эксперт по предмету «Информатика»
Предложить статью
Система команд процессора
В современных компьютерах основным устройством является процессор. Когда мы говорим слово «процессор», то, как правило, подразумеваем центральный процессор компьютера. Однако, кроме центрального процессора существуют специализированные процессоры, которые разработаны под отдельный спектр задач. Например, графический процессор видеокарты решает исключительно задачи ускорения трехмерной графики. У всех процессоров есть одно общее свойство: они умеют выполнять команды специального машинного языка. Машинный язык – это язык, который интерпретируется непосредственно процессором.
Не стоит путать машинный язык с высокоуровневыми языками программирования. Языки программирования не интерпретируются непосредственно процессором. Они гораздо ближе к человеческому естественному языку, а для их интерпретации нужны специальные «посредники», переводящие языки программирования на машинный язык.
Машинные языки разных процессоров отличаются, поскольку отличаются сами конструкции процессоров и их задачи. Поэтому к любому процессору прилагается документация, где подробно описана система команд машинного языка данной модели процессора.
В систему команд входят:
- разрешенные типы данных;
- инструкции;
- системы регистров;
- методы адресации;
- модели памяти;
- способы обработки прерываний;
- методы ввода и вывода.
Как правило, в систему команд любого процессора входят следующие основные команды:
- команды передачи данных, которые копируют информацию из одного места в другое;
- арифметические операции сложения и вычитания;
- сдвиги двоичного кода влево и вправо (они используются при реализации умножения и деления);
- логические операции сравнения, а так же операции И, ИЛИ, НЕ;
- команды ввода-вывода, предназначенные для обмена информации с внешними устройствами;
- команды управления, которые предназначены для организации перехода в любое нужное место программы в процессе ее выполнения.
Структура команды и обращение к данным
«Система команд и способы обращения к данным» 👇
Любая команда состоит из двух частей – операционной и адресной. Операционная часть показывает одно действие из списка допустимых, которое нужно выполнить с данными. Каждая операция имеет свой уникальный код. Адресная часть показывает, где хранятся эти данные и куда записать результат операции.
Основу адресной части составляет операнд. Операнд – это сущность, над которой производится операция. Например, если мы применяем операцию «сложения» к двум числам $2$ и $3$, то $2$ и $3$ будут называться операндами. В зависимости от числа операндов, команды бывают:
- одноадресными (например, увеличить или уменьшить значение операнда на $1$);
- двухадресными (например, сложить два операнда и записать результат на место второго операнда, вычесть из первого операнда второй, сравнить значения двух операндов);
- трехадресными (например, сложить два операнда, а результат записать в третий операнд);
- безадресные (команда останова программы, возврат из программы).
При этом адресная часть тоже может быть устроена по-разному. В адресной части могут находиться:
- сам операнд в явном виде;
- адрес операнда в виде номера байта, начиная с которого расположен операнд;
- адрес адреса операнда и т.д.
Замечание 1
Даже одна и та же команда сложения может быть организована и как одноадресная, и как двухадресная и как трехадресная. На первый взгляд, более естественно выглядит именно трехадресный вариант. Однако, это не совсем верно. Дело в том, что трехадресная команда должна содержать адреса трех ячеек. При больших объемах памяти эти три адреса будут занимать много места, и команда будет непомерно длинной. Поэтому трехадресные команды использовались в ранних ЭВМ, но позже были заменены на двухадресные и одноадресные.
Например, одноадресная команда сложения будет выглядеть примерно так:
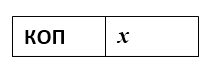
Рисунок 1.
Здесь КОП – это код операции, а $x$ — адрес одной ячейки. Для реализации этой команды нужно чтобы в архитектуре процессора было специальное устройство – сумматор. Содержимое ячейки с адресом $x$ складывается с содержимым сумматора. Результат сложения остается в сумматоре и может быть использован для дальнейших вычислений.
Двухадресная команда сложения выглядит вот так:

Рисунок 2.
В этом случае число из ячейки $x$ будет прибавлено к числу из ячейки y, а результат будет записан в ячейку $y$.
А у трехадресной команды сложения будет три операнда:
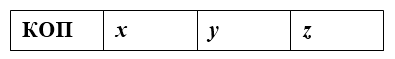
Рисунок 3.
Команда извлечет значения из ячеек с адресами $x$ и $y$, сложит их и запишет в ячейку с адресом $z$.
Выполнение команды разбивается на следующие этапы:
- В счетчике команд хранится адрес ячейки, в которой хранится следующая команда. Содержимое счетчика при этом увеличивается на длину команды.
- Выбранная команда передается в управляющее устройство (УУ) на регистр команд.
- УУ расшифровывает адрес команды.
- УУ дает сигнал, после которого операнды считываются из памяти и записываются в специальные регистры операндов аримфметико-логического устройства (АЛУ).
- УУ расшифровывает код операции и дает АЛУ сигнал выполнить операцию.
- Результат операции либо остается в процессоре, либо записывается в память, если это предусмотрено командой.
- Этапы $1-6$ повторяются для следующей команды. Повторение продолжается до достижения команды «стоп».
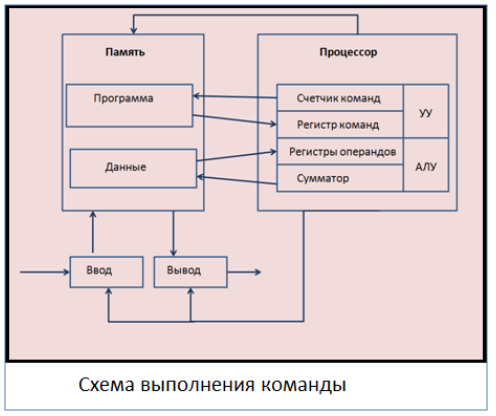
Рисунок 4.
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме
Тема 2.2 Система команд
План:
1 Типы команд
2 Расширение памяти программ и данных
3 Отладка и настройка микроконтроллерных систем
1 Типы команд
Система команд предоставляет большие возможности обработки данных, обеспечивает реализацию логических и арифметических операций, а также управление в режиме реального времени. Реализована побитовая, потетрадная (4 бита), побайтовая (8 бит) и 16-разрядная обработка данных. Синтаксис большинства ассемблерных команд состоит из мнемонического обозначения функции, вслед за которым идут операнды, указывающие методы адресации и типы данных. Рассмотрим типы команд базового микроконтроллера:
Рекомендуемые материалы
— арифметические инструкции;
— логические инструкции;
— инструкции передачи данных во внутренней памяти данных;
— инструкции передачи данных, использующие внешнюю память данных;
— инструкции передачи данных, использующие память программ;
— булевы инструкции;
— инструкции безусловных переходов;
— инструкции условных переходов;
В командах реализуются следующие режимы адресации:
— Dir — прямая (регистры специальных функций или память данных);
— Ind — косвенная (допустима только относительно регистров R0 и R1; в символической записи обозначается @R0 или @R1 соответственно) ;
— Reg — регистровая;
— Imm — непосредственная (в символической записи начинается с #);
— byte — прямоадресуемый байт;
— bit — прямоадресуемый бит (в регистрах специальных функций или битовой памяти);
— битовый аккумулятор — бит переноса в PSW.
В командах, допускающих прямую, но не регистровую адресацию, может указываться регистр общего назначения, однако при трансляции команды его номер будет в этом случае представлен не трех, а 8-разрядным кодом, соответствующим прямому адресу этого регистра в памяти данных. Некоторые Ассемблеры, в том числе используемый в данном лабораторном практикуме, требуют для таких команд указывать в явном виде номер регистра как прямой адрес ячейки памяти данных.
В инструкции MUL AB производится перемножение содержимого аккумулятора и регистра B. Старшие разряды произведения помещаются в аккумулятор, а младшие — в регистр B.
В инструкции DIV AB содержимое аккумулятора делится на содержимое регистра B. Частное помещается в аккумулятор, а остаток — в регистр B. Операнды рассматриваются как целые числа без знака:
— & -конъюнкция;
— v — дизъюнкция;
— E -«ИСКЛЮЧАЮЩЕЕ-ИЛИ»;
— ^ — логическое»НЕ»;
— ЦСЛ — циклический сдвиг влево;
— ЦСП — циклический сдвиг вправо;
— В операциях сдвига через бит С участвует 9-ти разрядный регистр (8-ми разрядный аккумулятор и бит переноса С) ;
— <=> — обмен местами операндов;
— в инструкции xchd a,@ri осуществляется обмен только младших тетрад операндов;
— для безусловных переходов adr показывает, что в команде кодируется абсолютный адрес памяти программ, по которому осуществляется переход;
— для условных переходов rel показывает, что в команде кодируется относительный адрес памяти программ, по которому осуществляется переход при выполнении указанного условия;
— во всех командах перехода при записи программы на ассемблере адрес перехода может быть задан меткой.
Некоторые Ассемблеры для инструкции вызова подпрограммы и инструкции безусловного перехода требуют от программиста явного указания длины генерируемого адреса перехода, то есть записи в программе инструкций ACALL, LCALL, AJMP, LJMP, SJMP и не воспринимают инструкции CALL, JMP. Другие Ассемблеры самостоятельно генерируют инструкции, имеющие необходимую длину поля адреса в зависимости от месторасположения адреса перехода и поэтому допускают использование лишь инструкций CALL.
2 Расширение памяти программ и данных
Однокристальные микроЭВМ имеют гарвардскую архитектуру, одной из отличительных черт которой является наличие физически и логически отделенных друг от друга памяти программ и памяти данных. Память данных, в свою очередь, включает в себя блок регистров общего назначения, область стека, область прямо адресуемых битов («битовая память»), блок специальных регистров и собственно память данных, организованную в виде традиционного ОЗУ. Различные модификации микроЭВМ семейства МК51 отличаются объемом и распределением памяти между внешними и внутренними блоками.
Память данных. Память данных МК — 51, расположенная на кристалле (внутренняя память данных), имеет объем 256 байт. Она может быть расширена до 64К байт за счет подключения блоков внешней памяти данных. Внутренняя память данных состоит из двух областей: 128 байт оперативной памяти (ОЗУ) с адресами 00h-7Fh и области регистров специальных функций, занимающей адреса 80h-FFh. Помимо возможности использования ОЗУ в качестве массива оперативной памяти, отдельные её области имеют самостоятельное значение. Часть ОЗУ используется в качестве регистров общего назначения, часть имеет прямо адресуемый доступ к отдельным битам, образуя так называемую битовую память. В ОЗУ располагается также и область стека. Младшие 32 байта внутреннего ОЗУ данных сгруппированы в 4 банка по 8 регистров общего назначения в каждом (БАНК0 — БАНК3). Определение рабочего в данный момент банка, то есть банка регистров, к которому обращается программа при использовании имен R0-R7, осуществляется установкой битов RS0, RS1 в регистре слова состояния PSW. Начальное состояние (RS0=RS1=0) этих разрядов после прохождения сигнала RESET определяет БАНК0 в качестве рабочего. Наличие нескольких банков регистров сокращает длину команд, а также уменьшает время, необходимое для сохранения и восстановления регистров при работе с подпрограммами и обработчиками прерываний, что характерно для задач, решаемых однокристальными микроЭВМ.
Область ОЗУ данных с адресами 20h-2Fh образует область ячеек, к которым возможна побитная адресация. Система команд МК51 содержит значительное количество инструкций, позволяющих работать с отдельными битами, используя при этом прямую адресацию. Область в 128 бит, составляющая рассматриваемую область внутреннего ОЗУ данных и имеющая адреса 00h-7Fh, предназначена для работы с такими инструкциями. Таким образом, к ячейке с адресом, например, 21h можно обратиться как к байту, используя её прямой адрес 21h, а можно обратиться к её отдельным битам в командах, работающих с битовой информацией. При этом младший бит этого байта имеет адрес 08h, а старший — 0Fh.
Область регистров специальных функций содержит защелки портов, регистры таймеров/счетчиков, регистры управления и т.п. Эти регистры допускают только прямую адресацию. Регистры, адрес которых кратен 8-ми, то есть заканчивается на 000b, допускают как байтовую, так и побитовую адресацию. Положение области стека во внутреннем ОЗУ не фиксировано, а определяется значением указателя стека SP. Начальное значение SP после системного сброса- 07h. SP указывает на верхнюю занятую ячейку стека. При обращении к стеку на запись сначала значение SP увеличивается на 1, а затем производится запись во внутреннюю память программ по адресу, хранящемуся в SP. Считывание из стека производится по адресу, хранящемуся в SP, после чего значение SP уменьшается на 1. Все ячейки внутреннего ОЗУ данных могут адресоваться с использованием прямой и косвенной адресации. Внутреннее ОЗУ, содержащее регистры специальных функций, адресуется с использованием только прямой адресации. К внешней памяти данных можно обращаться только с использованием специальных команд MOVX, которые осуществляют запись и считывание из неё информации и не влияют на внутреннюю память данных МК.
Таким образом, в системе могут одновременно присутствовать внутренняя память данных с адресами 00h-0Fh и внешняя память данных с адресами 0000h-FFFFh.
Память программ. В зависимости от модификации, различные типы БИС МК51 имеют разное распределение внутренней и внешней памяти программ, оставляя неизменным общий её объем в 64К байт. Память программ адресуется при помощи 16-разрядной адресной шины с использованием счетчика команд (PC) или инструкций, которые вырабатывают 16-разрядные адреса. Она имеет байтовую организацию и доступна только по чтению.
Обращение к внутренней или внешней памяти программ происходит автоматически с использованием аппаратных средств микроЭВМ. При этом, в зависимости от состояния управляющего входа DEMA , вся память трактуется либо как только внешняя (при DEMA=0), либо как внутренняя, занимающая младшие адреса адресного пространства, и внешняя, занимающая адреса от старшего адреса внутренней памяти до максимально допустимого FFFFh (при DEMA=1). С точки зрения программиста имеется только один массив памяти объемом 64К байт.
3 Отладка и настройка микроконтроллерных систем
Отладка аппаратных средств. На этапе автономной отладки аппаратных средств основными орудиями разработчика являются традиционные измерительные приборы — генераторы, осциллографы, мультиметры, пробники, а также специализированные приборы — логические анализаторы, осциллографы смешанных сигналов, генераторы тестовых последовательностей и сигналов заданной формы, которые обладают широкими возможностями контроля состояния различных узлов системы в заданные моменты времени.
Отладка программного обеспечения.
Схемный эмулятор ICE (In-Circuit Emulator) представляет собой программно-аппаратный комплекс, который в процессе отладки замещает в реализуемой системе микропроцессор или микроконтроллер. В результате такой замены функционирование отлаживаемой системы становится наблюдаемым и контролируемым. Разработчик получает возможность визуально контролировать работу системы на экране персонального компьютера и управлять ее работой путем установки определенных управляющих сигналов, модификации содержимого регистров и памяти. Благодаря наличию таких возможностей схемный эмулятор является наиболее универсальным и эффективным отладочным средством, используемым на этапе комплексной отладки системы.
Схемный эмулятор позволяет вводить в систему тестовую или рабочую программу и контролировать ее выполнение, обеспечивая остановы в контрольных точках. Условиями останова могут быть различные комбинации значений адреса, данных и управляющих сигналов, поступающих на выводы эмулирующего микропроцессора или микроконтроллера. Эти комбинации задаются пользователем с клавиатуры управляющего компьютера. После останова пользователь может получить на экране полную информацию о текущем состоянии любых регистров и ячеек памяти системы. С помощью памяти трассы можно просмотреть состояния системной шины для определенного количества предыдущих циклов выполнения программы. Дизассемблер дает возможность анализировать выполнение программы в соответствии с ее исходным текстом на языке Ассемблера.
Схемные эмуляторы, реализующие большую часть вышеперечисленных функций, называют отладочными комплексами или системами развития (development system).
Схемные симуляторы (In-Circuit Simulator). Для проектирования и отладки систем на базе ряда микроконтроллеров семейства 68НС705, 68НС908 компания Motorola предлагает серии недорогих схемных симуляторов M68ICS05, M68ICS08.
В комплект поставляемых схемных симуляторов входят аппаратные средства — плата симулятора/программатора с необходимой комплектацией, комплект программного обеспечения и технической документации. Программное обеспечение представляет собой многооконную интегрированную среду разработки, функционирующую в среде Windows. Интегрированная среда включает редактор текста, кросс-транслятор с языка Ассемблера и отладчик, управляющий платой внутрисхемного симулятора.
Плата схемного симулятора подключается к персональному компьютеру через последовательный интерфейс типа RS-232 (скорость обмена 19,2 или 115,2 Кбит/с). Плата содержит микроконтроллер, который включается в отлаживаемую систему вместо ее микроконтроллера, симулируя его работу. Соединение с системой производится через кабель с вилкой, соответствующей типу корпуса микроконтроллера, на который рассчитан данный схемный симулятор.
Схемные симуляторы M68ICS05 обеспечивают выполнение всех этапов разработки и отладки прикладных задач на основе микроконтроллеров 68НС705:
— ввод программы на языке Ассемблера и ее трансляцию в двоичный код;
— выполнение программы по шагам;
— выполнение программы в режиме псевдопрогона (на пониженной частоте);
— останов выполнения программы в контрольных точках;
— останов выполнения программы по состоянию регистров микроконтрол-лера;
— отображение на экране дисплея и модификация всех программно-доступных ресурсов микроконтроллера (в момент останова);
— подключение в исследуемую систему вместо целевого микроконтрол-лера;
— программирование внутренней памяти микроконтроллера.
Вывод:
Приведен краткий анализ состава команд микроконтроллера МК – 51, рассмотрены вопросы расширения адресного пространства. Показаны аппаратные и программные средства отладки микропроцессорных систем.
Рекомендация для Вас — Изменение типа диаграммы.
Контрольные вопросы:
1 Каков размер обрабатываемых данных в микроконтроллере МК — 51?
2 Перечислите типы команд микроконтроллере МК – 51.
3 Каков размер памяти данных и команд?
4 Для чего применяют схемные эмуляторы?
5 Каковы функциональные возможности симуляторов?
 Общие сведения о системе команд.
Общие сведения о системе команд.
Фиксированный набор команд конкретного микропроцессора называют системой команд. Функциональные способности процессора определяются совокупностью базовых команд с различными кодами операций. Общее число команд (кодов операции) в системе всегда больше числа базовых команд. Например, к базовой команде относится команда
MOV dst, scr,
которая обеспечивает функцию пересылки данных из источника
scr
в приемник
dst.
Таких команд в системе может быть очень много. Система команд представляется в виде таблицы. Таблица может иметь различную структуру, однако обычно содержит следующие сведения о команде:
● мнемоническое обозначение команды, представляющее собой сокращенную запись названия команды. Для этого используются три–четыре латинские буквы названия операции, выполняемой командой. Мнемоника является удобной формой представления кода операции команды. Кроме того, она используется при описании команды на языке ассемблера. Программа ассемблера преобразует мнемоническое обозначение кодов операции в соответствующие двоичные эквиваленты;
● шестнадцатеричные коды команд;
● влияние выполненной команды на флаги регистра слова состояния программы;
● число байтов в команде и число машинных циклов и такте, затрачиваемых на выполнение команды;
● словесное и (или) символьное описание выполняемой командой операции. Часто для удобства систему команд разбивают на отдельные группы по функциональному признаку. Например систему команд микропроцессора:
● КР580ВМ80, содержащую 78 базовых команд, разбивают на пять групп: пересылки, логической обработки, арифметической обработки, передачи управления и управления процессором,
● К1810
B
М86, содержащую 113 базовых команд, разбивают на шесть групп: пересылки, логической обработки, арифметической обработки, обработки строк, передачи управления и управления процессором. Ниже на примере процессоров КР580ВМ80 приведено краткое описание функциональных особенностей команд каждой группы.
Система команд 8–разрядных процессоров.
Рассмотрим систему команд 8–разрядного процессора 8080, в которую входит 78 базовых команд, содержащих 111 кодов операций.
Команды имеют длину от 1 до 3 байт. Код операции всегда размещен в первом байте команды. Второй байт команды отводится под непосредственный операнд или адрес порта, второй и третий байты являются адресом ячейки памяти. Команды допускают явное задание только одного адреса памяти, т. е. относятся к классу одноадресных команд.
При описаний–команд используются следующие обозначения:
●
src
,
dst
— 8–разрядные источник и приемник. Источником или приемником может быть один из 8–разрядных регистров А, В, С,
D, E,
Н или ячейка памяти М, доступ к которой обеспечивает регистровая пара
HL
, содержащая адрес пересылаемого байта. В коде операции источник
src
и приемник
dst
указаны в виде трехразрядного кода
SSS
и
DDD
;
●
RP
— двухразрядный код регистровых пар ВС,
DE, HL,
А + РП (регистр признаков) или указателя стека
SP;
●
data, data16
— 8– и 16–разрядный операнд;
●
addr
,
port
— 16–разрядный адрес памяти и 8–разрядный адрес порта;
● (
addr
), (
SP
) — содержимое ячейки памяти по указанным адресам;
● (
SP
)+, –(
SP
) — операции постинкремента и предекремента со стеком, описание которых приведено в параграфе 2.6.
Система команд разбивается на пять функциональных групп. Рассмотрим особенности команд каждой группы.
Команды пересылки.
Группа содержит наиболее часто встречающиеся в программах команды пересылки данных, источниками и приемниками которых могут быть внутренние регистры процессора, основная память и внешние устройства. Команды не оказывают воздействий на флаги регистра состояния. Мнемоника команды отражает особенности выполняемой операции и способ переадресации. Например, мнемоника
MOV, MVI
указывает на перемещение (
Move
) операндов;
LDA
,
LDAX
,
LXI
,
LHLD
— на загрузку (
Load
);
STA,
STAX
,
SHLD
— на сохранение (
Save
).
Для операций с байтами используется мнемоника
MOV
,
MVI
,
LDA, STA, LDAX, STAX;
для операций со словами —
LXI, LHLD, SHLD.
Прямая адресация при загрузке и сохранении содержимого аккумулятора отражается мнемоникой
LDA
и
STA,
косвенная — мнемоникой
LDAX
и
STAX.
Примечание:
ВР — двухразрядный код регистровых пар ВС,
D
Е, Н
L
, А + РП (регистр признаков) или указателя стека
S
Р. 
Команды этой группы сведены в табл. 2.8.1 и позволяют осуществить:
● операцию пересылки данных между источником (
src
) и приемником (
dst
), которая записывается в виде
dst
<—
src
(команда 1). Источниками и приемниками являются внутренние регистры общего назначения (А, В, С,
D
, Е, Н) и ячейка памяти
M
. Допускается любая комбинация и за исключением М <—
M
, т. е. перезагрузка ячейки памяти М не разрешается;
● загрузку регистров общего назначения и ячейки М вторым байтом В2 (команда 2) и регистровых пар ВС,
D
Е,
HL
(в том числе указателя стека
S
Р) вторым В2 и третьим ВЗ байтами (команда 3), причем всегда ВЗ загружается в старшие регистры (В,
D
, Н) пары, В2 — в младшие регистры (С, Е ,
L
);
● пересылку данных между аккумулятором А и основной памятью (команды 4–7), между аккумулятором и внешним устройством (команды 8, 9). При пересылке между аккумулятором А и памятью адреса ячеек памяти располагаются в регистровых парах ВС,
D
Е или в третьем и втором байтах ВЗВ2 команды;
● пересылку данных между парой регистров
HL
и памятью (команды 10, 11). При этом операнд из регистра
L
пересылается в ячейку с адресом ВЗВ2, образованным из третьего и второго байта команды, а из регистра Н — по адресу на единицу больше. При обратной пересылке сначала из ячейки с адресом ВЗВ2 в регистр
L
загружается первый операнд, затем из ячейки с адресом ВЗВ2 + 1 в регистр Н — второй;
● пересылку
данных между парами регистров, включая пару из аккумулятора А и регистра признаков РП, и стеком (команды 12, 13). При записи в стек содержимое указателя стека уменьшается на единицу, и по адресу
S
Р – 1 загружается первый операнд из регистра В,
D
,
Н или А, затем содержимое указателя стека снова уменьшается на единицу, и по адресу
S
Р – 2 загружается второй операнд из регистра С, Е,
L
или РП. При выводе из стека сначала загружается регистр С, Е,
L
или РП операндом, хранящимся в ячейке с адресом
S
Р указателя стека. Затем содержимое увеличивается на единицу, из ячейки с адресом
S
Р + 1 второй операнд загружается в регистр В,
D
,
Н или А, и содержимое указателя стека вновь увеличивается на единицу и принимает значение
S
Р + 2.
Следует отметить, что при загрузке регистровой пары А, РП (ее код
R
Р = 11) из стека изменяется состояние триггеров регистра признаков РП. Это единственная команда (из всех команд пересылки данных), которая влияет на признаки;
● пересылку
содержимого пары регистров Н
L
в указатель стека
S
Р и программный счетчик РС (команды 14, 15);
● обмен
данными между парами регистров Н
L
и
D
Е, парой регистров Н
L
и стеком (команды 16, 17). При обмене содержимое регистровой пары Н
L
помещается в пару
D
Е или стек, а содержимое регистровой пары
D
Е или стека — в пару Н
L
. Операция обмена обозначается символом «↔».
Арифметические команды.
Вычислительные возможности микропроцессора ограничены простыми командами сложения и вычитания 8–разрядных операндов. Операции умножения и деления реализуются программным способом. 
Набор команд (табл. 2.8.2) позволяет выполнить:
●
сложение и вычитание 8–разрядных операндов с учетом и без учета переноса (команды 1–8), при этом один из операндов всегда находится в аккумуляторе, а второй — в одном из регистров общего назначения (ячейке памяти М) или является вторым байтом команды. Команды, учитывающие значение сигнала переноса С регистра прививков, используются при сложении и вычитании многобайтных чисел. Для этой же цели можно использовать команду 9 сложения содержимого пары регистров Н
L
с 16–разрядным адресуемым регистром;
●
арифметическое сравнение содержимого аккумулятора А с содержимым одного из регистров общего назначения
Rn
(ячейкой памяти М) или вторым байтом В2 (команды 10–11). При этом выполняется вычитание А –
Rn
или А – В2. Результат сравнения определяется по сигналам триггеров регистра признаков: если
Z
=
1, то А =
Rn
или А = В2; если
S
=1, то А >
Rn
или А > В2. Содержимое аккумулятора не изменяется;
● увеличение
и уменьшение на 1 (инкремент и декремент) содержимого регистров и регистровых пар. При программировании часто возникает необходимость увеличения или уменьшения на единицу значения операнда. Для этого можно использовать операции сложения А + В2 или вычитания А – В2, записав в программе В2 = 1. Однако в системе команд предусмотрены специальные команды (12–15) инкремента и декремента 8– и 16–разрядных операндов;
● десятичную коррекцию
содержимого аккумулятора после выполнения арифметических операций в двоично–десятичном коде 8421 (команда 16). При этом содержимое аккумулятора представляется в виде двух полубайтов, каждый из которых соответствует десятичной цифре. Коррекция производится блоком десятичной коррекции по правилам. 
Команды логических операций (табл. 2.8.3). Команды этой группы позволяют реализовать:
●
двуместные логические операции умножения (И), сложения (ИЛИ) и исключающее ИЛИ над 8–разрядными операндами (команды 1–6). Логические операции являются поразрядными и выполняются независимо для каждого из восьми бит операндов. Неадресуемый операнд находится в аккумуляторе, туда же поступает результат операции. Вторым операндом является содержимое одного из регистров общего назначения (ячейки памяти М) или второй байт команды;
● инвертирование
содержимого аккумулятора А (команда 7);
●
флаговые команды (8, 9) инвертирования и установки бита С триггера переноса регистра признаков;
●
два вида циклических сдвигов содержимого аккумулятора влево и вправо (команды 10–13). Первый вид сдвигов (сдвиги без переноса) реализуется путем замыкания в кольцо всех триггеров аккумулятора, при втором виде сдвигов (сдвиги с переносом, или расширенные сдвиги) в кольцо дополнительно вводится триггер переноса С регистра признаков. Отсутствующие в системе команд логические и арифметические сдвиги в обе стороны можно реализовать предварительной установкой бита С в 0 или 1 совместно с расширенным сдвигом.
Команды передачи управления.
При передаче управления нарушается последовательный ход выборки содержимого ячеек памяти и процессор адресуется в другую область памяти. Следует выделить три вида команд передачи управления: команды перехода по заданному адресу (
JMP
), вызова подпрограммы (
CALL
) и возврата из подпрограммы
(RET).
К ним относятся безусловные и условные команды. Условные команды осуществляют переход, вызов подпрограммы и возврат из подпрограммы в зависимости от состояния флага, задаваемого значением сигнала одного из четырех триггеров
Z,
С,
S,
Р регистра признаков (или состояния). 
В процессоре 8080 используются оба состояния (1 и 0) четырех флагов
(Z,
С, Р,
S),
позволяющих получить 8 вариантов каждой команды (табл. 2.8.4). Обозначение признака (условия) указывается в мнемонике условных команд
J**,
С**,
R**
вместо звездочек (**). Например, признаку
NC,
для которого условия перехода считаются выполненными при С = 0, соответствует команда
JNC.
В операциях как условного, так и безусловного перехода и вызова подпрограмм используется полный прямой 16–разрядный адрес, обеспечивающий передачу управления в любую точку 64К–байтовой области пространства памяти.
Рассмотрим особенности команд, представленных в табл. 2.8.5. 
С помощью трехбайтной команды
JMP
реализуется безусловная передача управления. При этом второй и третий байты команды (адрес
addr
продолжения программы) заносятся в счетчик команд РС (содержимое ВЗ в старшие разряды, В2 — в младшие).
Команды условной передачи управления
J
** реализуют разветвление вычислительного процесса в зависимости от условия. При выполнении условия (ДА) в счетчик РС заносится второй и третий байты команды, в противном случае (НЕТ) содержимое счетчика увеличивается на 3 единицы. Продолжение программы осуществляется по адресу, находящемуся в счетчике команд, т. е. со следующей команды.
Команды безусловного (СА
LL
) и условного (С**) вызовов используются для обращения к подпрограммам, хранящимся в другой части основной памяти. Эти команды всегда предусматривают возможность возврата в прерванную основную программу путем сохранения в стеке содержимого программного счетчика РС, для чего используется предекрементный способ адресации. После этой операции:
● при безусловном вызове или выполнении условия второй и третий байты команды заносятся в программный счетчик РС;
● при невыполнении условия содержимое программного счетчика увеличивается на 3 единицы.
Продолжение программы осуществляется по адресу, находящемуся в счетчике команд РС.
В наборе имеются команды, позволяющие реализовать безусловную (
RET
) и условную (
R
**) передачу управления для возврата в прерванную программу. При выполнении этих команд адрес возврата переписывается из стека в программный счетчик РС, для чего используется постинкрементный способ адресации. При невыполнении условия возврата (для команды с условием) осуществляется переход к очередной команде путем увеличения на единицу содержимого программного счетчика РС.
Команды возврата являются однобайтными, так как в указателе стека
S
Р хранится адрес ячейки стека с адресом возврата в прерванную программу. 
Команда РСН
L
, загружает в программный счетчик РС адрес, хранящийся в регистровой паре
HL
.
Команды общего управления.
Команды этой группы (табл. 2.8.6) используются для задания режима работы микропроцессора. Команда
RST
используется для повторного пуска микропроцессора и при обслуживании прерываний. При ее выполнении:
● содержимое программного счетчика переносится в стек по адресам
S
Р – 1,
S
Р – 2, формируемым в указателе стека, что обеспечивает возврат к основной программе;
● в программный счетчик засылается 16–разрядный адрес начала одной из 8 программ обслуживания прерывания.
Команда разрешения прерывания
EI
устанавливает триггер
INTE
разрешения прерываний в единичное состояние, при этом микропроцессор реагирует на запросы прерываний. Команда запрещения прерываний
DI
устанавливает триггер
INTE
в нулевое состояние. Пустая команда
NOP
используется в циклах программируемой задержки. Команда останова
HLT
вызывает прекращение выполнения программы.