Аббревиатура AVX расшифровывается как Advanced Vector Extensions. Это наборы инструкций для процессоров Intel и AMD, идея создания которых появилась в марте 2008 года. Впервые такой набор был встроен в процессоры линейки Intel Haswell в 2013 году. Поддержка команд в Pentium и Celeron появилась лишь в 2020 году.
Прочитав эту статью, вы более подробно узнаете, что такое инструкции AVX и AVX2 для процессоров, а также — как узнать поддерживает ли процессор AVX.
AVX и AVX2 – что это такое
AVX/AVX2 — это улучшенные версии старых наборов команд SSE. Advanced Vector Extensions расширяют операционные пакеты со 128 до 512 бит, а также добавляют новые инструкции. Например, за один такт процессора без инструкций AVX будет сложена 1 пара чисел, а с ними — 10. Эти наборы расширяют спектр используемых чисел для оптимизации подсчёта данных.
Наличие у процессоров поддержки AVX весьма желательно. Эти инструкции предназначены, прежде всего, для выполнения сложных профессиональных операций. Без поддержки AVX всё-таки можно запускать большинство игр, редактировать фото, смотреть видео, общаться в интернете и др., хотя и не так комфортно.
Как узнать, поддерживает ли процессор AVX
Далее будут показаны несколько простых способов узнать это. Некоторые из методов потребуют установки специального ПО.
1. Таблица сравнения процессоров на сайте Chaynikam.info.
Для того чтобы узнать, поддерживает ли ваш процессор инструкции AVX, можно воспользоваться предлагаемым способом. Перейдите на этот сайт. В правом верхнем углу страницы расположена зелёная кнопка Добавить процессор. Нажмите её.
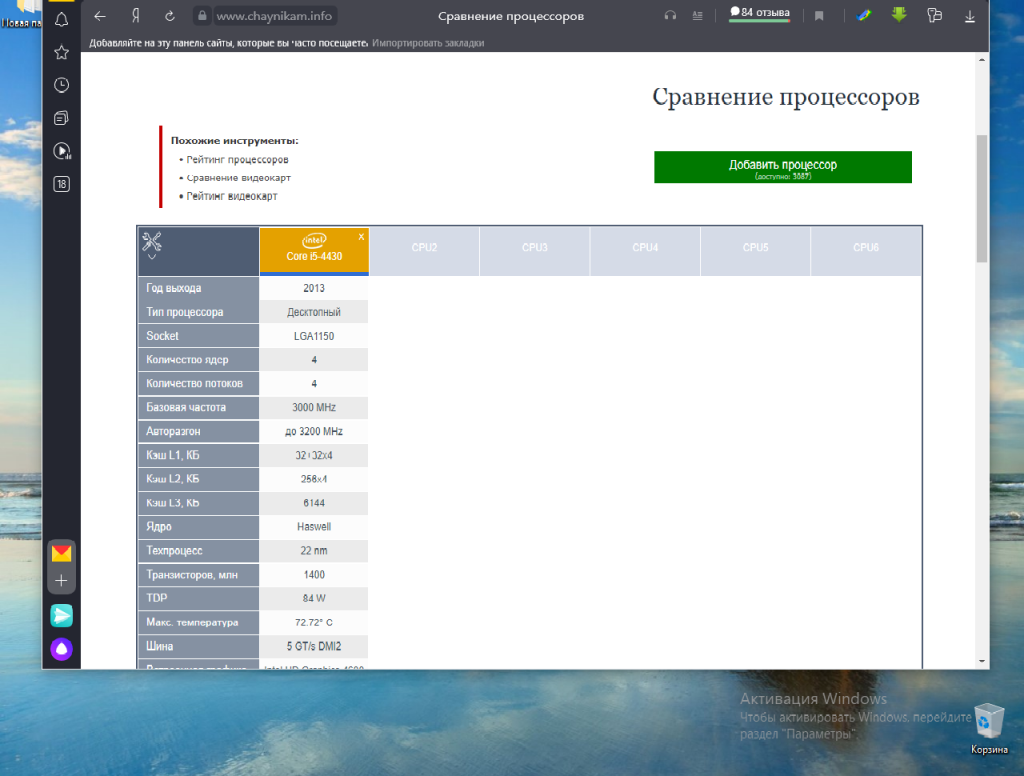
В открывшемся окне вам будет предложено указать параметры выбора нужного процессора. Все указывать не обязательно.
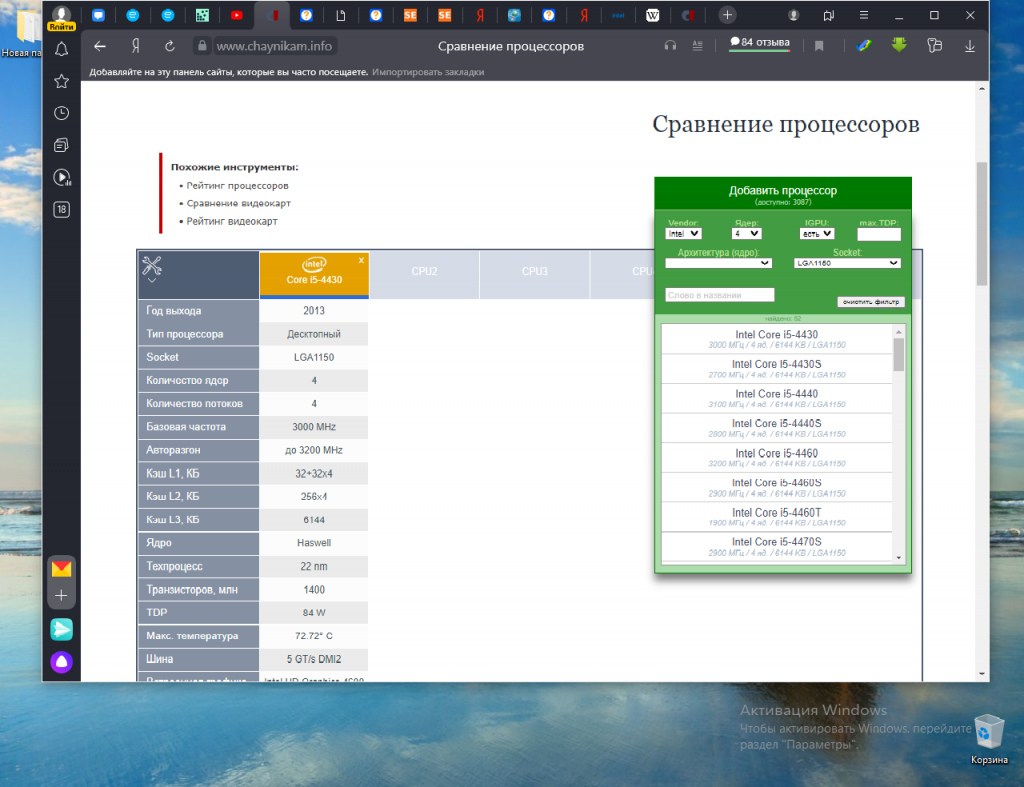
В результате выполнения поиска будет сформирована таблица с параметрами выбранного из списка процессора. Прокрутите таблицу вниз. В строке Поддержка инструкций и технологий будет показана подробная информация.
2. Утилита CPU-Z.
Один из самых простых и надёжных способов узнать поддерживает ли процессор AVX инструкции, использовать утилиту для просмотра информации о процессоре — CPU-Z. Скачать утилиту можно на официальном сайте. После завершения установки ярлык для запуска утилиты появится на рабочем столе. Запустите её.
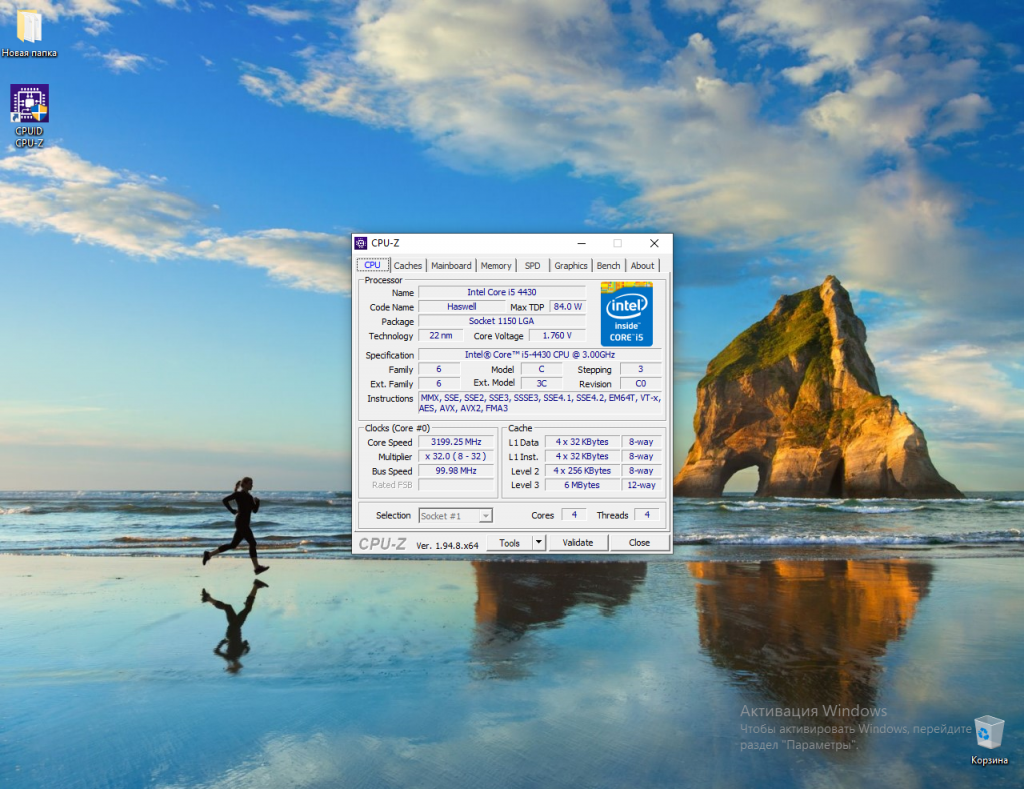
В строке Instructions показаны все инструкции и другие технологии, поддерживаемые вашим процессором.
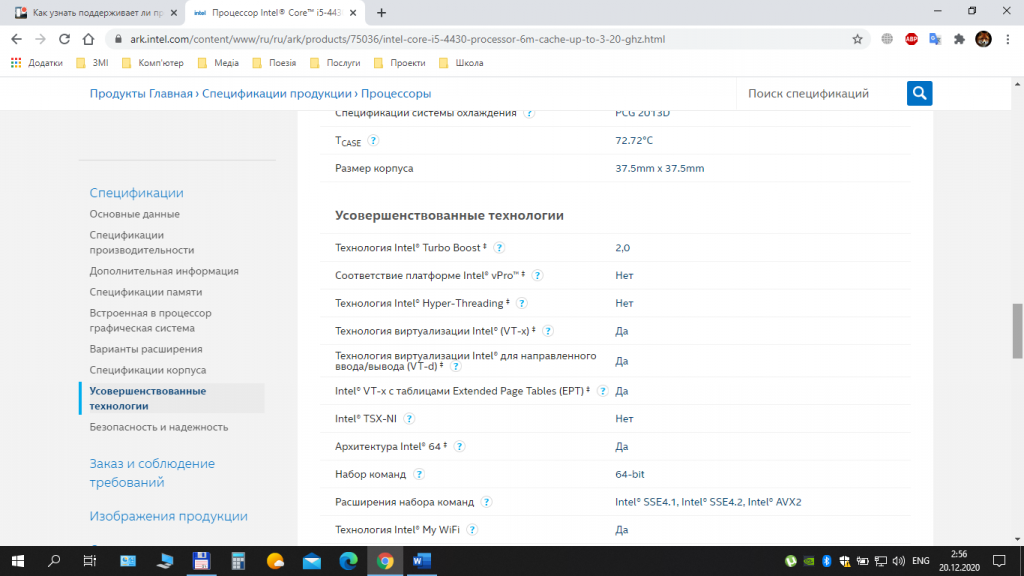
3. Поиск на сайте производителя.
Ещё один способ узнать, есть ли AVX на процессоре, воспользоваться официальным сайтом производителя процессоров. В строке поиска браузера наберите название процессора и выполните поиск. Если у вас процессор Intel, выберите соответствующую страницу в списке и перейдите на неё. На этой странице вам будет предоставлена подробная информация о процессоре.
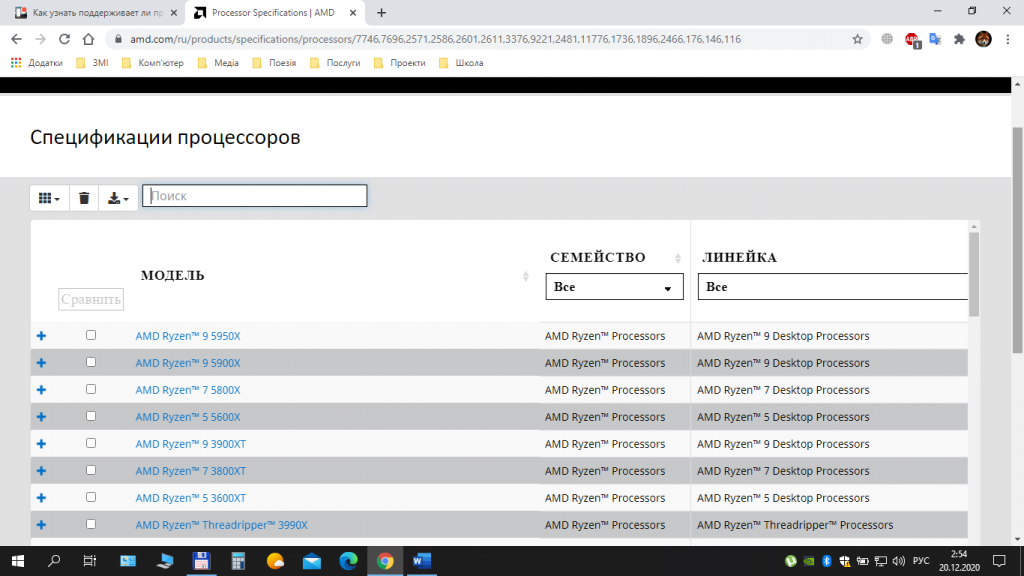
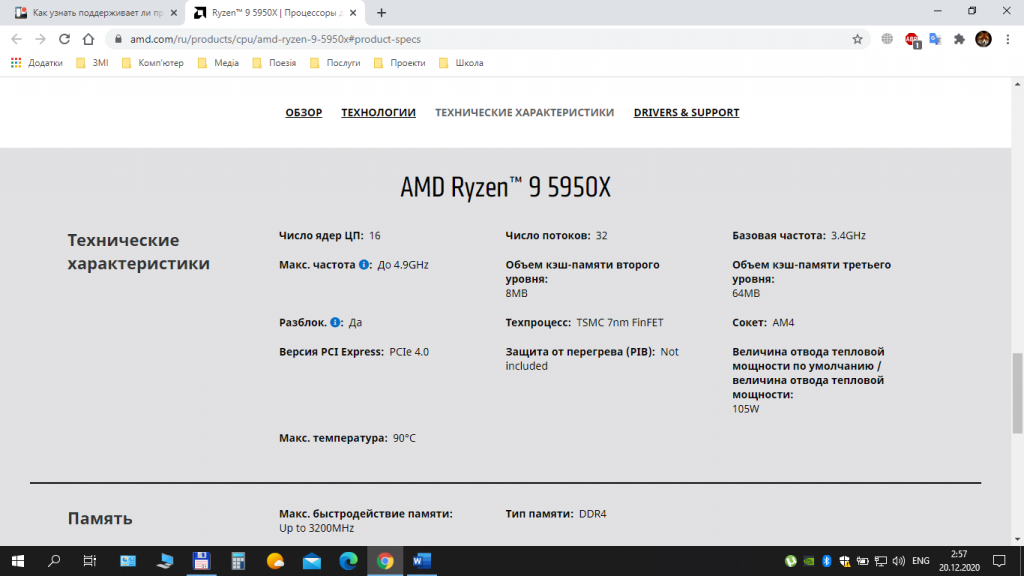
Если у вас процессор от компании AMD, то лучше всего будет воспользоваться сайтом AMD. Выберите пункт меню Процессоры, далее — пункт Характеристики изделия и затем, выбрав тип (например, Потребительские процессоры), выполните переход на страницу Спецификации процессоров. На этой странице выполните поиск вашего процессора по названию и посмотрите подробную информацию о нём.
Выводы
В этой статье мы довольно подробно рассказали о поддержке процессорами инструкций AVX, AVX2, а также показали несколько способов, позволяющих выяснить наличие такой поддержки конкретно вашим процессором. Надеемся, что дополнительная информация об используемом процессоре будет полезна для вас, а также поможет в выборе процессора в будущем.
Была ли эта статья полезной?
ДаНет
Оцените статью:
 (8 оценок, среднее: 5,00 из 5)
(8 оценок, среднее: 5,00 из 5)
![]() Загрузка…
Загрузка…
Об авторе

Над статьей работал не только её автор, но и другие люди из команды te4h, администратор (admin), редакторы или другие авторы. Ещё к этому автору могут попадать статьи, авторы которых написали мало статей и для них не было смысла создавать отдельные аккаунты.
From Wikipedia, the free encyclopedia
Advanced Vector Extensions (AVX) are SIMD extensions to the x86 instruction set architecture for microprocessors from Intel and Advanced Micro Devices (AMD). They were proposed by Intel in March 2008 and first supported by Intel with the Sandy Bridge[1] processor shipping in Q1 2011 and later by AMD with the Bulldozer[2] processor shipping in Q3 2011. AVX provides new features, new instructions, and a new coding scheme.
AVX2 (also known as Haswell New Instructions) expands most integer commands to 256 bits and introduces new instructions. They were first supported by Intel with the Haswell processor, which shipped in 2013.
AVX-512 expands AVX to 512-bit support using a new EVEX prefix encoding proposed by Intel in July 2013 and first supported by Intel with the Knights Landing co-processor, which shipped in 2016.[3][4] In conventional processors, AVX-512 was introduced with Skylake server and HEDT processors in 2017.
Advanced Vector Extensions[edit]
AVX uses sixteen YMM registers to perform a single instruction on multiple pieces of data (see SIMD). Each YMM register can hold and do simultaneous operations (math) on:
- eight 32-bit single-precision floating point numbers or
- four 64-bit double-precision floating point numbers.
The width of the SIMD registers is increased from 128 bits to 256 bits, and renamed from XMM0–XMM7 to YMM0–YMM7 (in x86-64 mode, from XMM0–XMM15 to YMM0–YMM15). The legacy SSE instructions can be still utilized via the VEX prefix to operate on the lower 128 bits of the YMM registers.
| 511 256 | 255 128 | 127 0 |
| ZMM0 | YMM0 | XMM0 |
| ZMM1 | YMM1 | XMM1 |
| ZMM2 | YMM2 | XMM2 |
| ZMM3 | YMM3 | XMM3 |
| ZMM4 | YMM4 | XMM4 |
| ZMM5 | YMM5 | XMM5 |
| ZMM6 | YMM6 | XMM6 |
| ZMM7 | YMM7 | XMM7 |
| ZMM8 | YMM8 | XMM8 |
| ZMM9 | YMM9 | XMM9 |
| ZMM10 | YMM10 | XMM10 |
| ZMM11 | YMM11 | XMM11 |
| ZMM12 | YMM12 | XMM12 |
| ZMM13 | YMM13 | XMM13 |
| ZMM14 | YMM14 | XMM14 |
| ZMM15 | YMM15 | XMM15 |
| ZMM16 | YMM16 | XMM16 |
| ZMM17 | YMM17 | XMM17 |
| ZMM18 | YMM18 | XMM18 |
| ZMM19 | YMM19 | XMM19 |
| ZMM20 | YMM20 | XMM20 |
| ZMM21 | YMM21 | XMM21 |
| ZMM22 | YMM22 | XMM22 |
| ZMM23 | YMM23 | XMM23 |
| ZMM24 | YMM24 | XMM24 |
| ZMM25 | YMM25 | XMM25 |
| ZMM26 | YMM26 | XMM26 |
| ZMM27 | YMM27 | XMM27 |
| ZMM28 | YMM28 | XMM28 |
| ZMM29 | YMM29 | XMM29 |
| ZMM30 | YMM30 | XMM30 |
| ZMM31 | YMM31 | XMM31 |
AVX introduces a three-operand SIMD instruction format called VEX coding scheme, where the destination register is distinct from the two source operands. For example, an SSE instruction using the conventional two-operand form a ← a + b can now use a non-destructive three-operand form c ← a + b, preserving both source operands. Originally, AVX’s three-operand format was limited to the instructions with SIMD operands (YMM), and did not include instructions with general purpose registers (e.g. EAX). It was later used for coding new instructions on general purpose registers in later extensions, such as BMI. VEX coding is also used for instructions operating on the k0-k7 mask registers that were introduced with AVX-512.
The alignment requirement of SIMD memory operands is relaxed.[5] Unlike their non-VEX coded counterparts, most VEX coded vector instructions no longer require their memory operands to be aligned to the vector size. Notably, the VMOVDQA instruction still requires its memory operand to be aligned.
The new VEX coding scheme introduces a new set of code prefixes that extends the opcode space, allows instructions to have more than two operands, and allows SIMD vector registers to be longer than 128 bits. The VEX prefix can also be used on the legacy SSE instructions giving them a three-operand form, and making them interact more efficiently with AVX instructions without the need for VZEROUPPER and VZEROALL.
The AVX instructions support both 128-bit and 256-bit SIMD. The 128-bit versions can be useful to improve old code without needing to widen the vectorization, and avoid the penalty of going from SSE to AVX, they are also faster on some early AMD implementations of AVX. This mode is sometimes known as AVX-128.[6]
New instructions[edit]
These AVX instructions are in addition to the ones that are 256-bit extensions of the legacy 128-bit SSE instructions; most are usable on both 128-bit and 256-bit operands.
| Instruction | Description |
|---|---|
VBROADCASTSS, VBROADCASTSD, VBROADCASTF128
|
Copy a 32-bit, 64-bit or 128-bit memory operand to all elements of a XMM or YMM vector register. |
VINSERTF128
|
Replaces either the lower half or the upper half of a 256-bit YMM register with the value of a 128-bit source operand. The other half of the destination is unchanged. |
VEXTRACTF128
|
Extracts either the lower half or the upper half of a 256-bit YMM register and copies the value to a 128-bit destination operand. |
VMASKMOVPS, VMASKMOVPD
|
Conditionally reads any number of elements from a SIMD vector memory operand into a destination register, leaving the remaining vector elements unread and setting the corresponding elements in the destination register to zero. Alternatively, conditionally writes any number of elements from a SIMD vector register operand to a vector memory operand, leaving the remaining elements of the memory operand unchanged. On the AMD Jaguar processor architecture, this instruction with a memory source operand takes more than 300 clock cycles when the mask is zero, in which case the instruction should do nothing. This appears to be a design flaw.[7] |
VPERMILPS, VPERMILPD
|
Permute In-Lane. Shuffle the 32-bit or 64-bit vector elements of one input operand. These are in-lane 256-bit instructions, meaning that they operate on all 256 bits with two separate 128-bit shuffles, so they can not shuffle across the 128-bit lanes.[8] |
VPERM2F128
|
Shuffle the four 128-bit vector elements of two 256-bit source operands into a 256-bit destination operand, with an immediate constant as selector. |
VTESTPS, VTESTPD
|
Packed bit test of the packed single-precision or double-precision floating-point sign bits, setting or clearing the ZF flag based on AND and CF flag based on ANDN. |
VZEROALL
|
Set all YMM registers to zero and tag them as unused. Used when switching between 128-bit use and 256-bit use. |
VZEROUPPER
|
Set the upper half of all YMM registers to zero. Used when switching between 128-bit use and 256-bit use. |
CPUs with AVX[edit]
- Intel
- Sandy Bridge processors, Q1 2011[9]
- Sandy Bridge E processors, Q4 2011[10]
- Ivy Bridge processors, Q1 2012
- Ivy Bridge E processors, Q3 2013
- Haswell processors, Q2 2013
- Haswell E processors, Q3 2014
- Broadwell processors, Q4 2014
- Skylake processors, Q3 2015
- Broadwell E processors, Q2 2016
- Kaby Lake processors, Q3 2016 (ULV mobile)/Q1 2017 (desktop/mobile)
- Skylake-X processors, Q2 2017
- Coffee Lake processors, Q4 2017
- Cannon Lake processors, Q2 2018
- Whiskey Lake processors, Q3 2018
- Cascade Lake processors, Q4 2018
- Ice Lake processors, Q3 2019
- Comet Lake processors (only Core and Xeon branded), Q3 2019
- Tiger Lake (Core, Pentium and Celeron branded[11]) processors, Q3 2020
- Rocket Lake processors, Q1 2021
- Alder Lake (Xeon, Core, Pentium and Celeron branded) processors, Q4 2021. Supported both in Golden Cove P-cores and Gracemont E-cores.
- Raptor Lake processors, Q4 2022
- Sapphire Rapids processors, Q1 2023
- Meteor Lake processors
- Arrow Lake processors
- Lunar Lake processors
Not all CPUs from the listed families support AVX. Generally, CPUs with the commercial denomination Core i3/i5/i7/i9 support them, whereas Pentium and Celeron CPUs before Tiger Lake[12] do not.
- AMD:
- Jaguar-based processors and newer
- Puma-based processors and newer
- «Heavy Equipment» processors
- Bulldozer-based processors, Q4 2011[13]
- Piledriver-based processors, Q4 2012[14]
- Steamroller-based processors, Q1 2014
- Excavator-based processors and newer, 2015
- Zen-based processors, Q1 2017
- Zen+-based processors, Q2 2018
- Zen 2-based processors, Q3 2019
- Zen 3 processors, Q4 2020
- Zen 4 processors, Q4 2022
Issues regarding compatibility between future Intel and AMD processors are discussed under XOP instruction set.
- VIA:
- Nano QuadCore
- Eden X4
- Zhaoxin:
- WuDaoKou-based processors (KX-5000 and KH-20000)
Compiler and assembler support[edit]
- Absoft supports with -mavx flag.
- The Free Pascal compiler supports AVX and AVX2 with the -CfAVX and -CfAVX2 switches from version 2.7.1.
- RAD studio (v11.0 Alexandria) supports AVX2 and AVX512.[15]
- The GNU Assembler (GAS) inline assembly functions support these instructions (accessible via GCC), as do Intel primitives and the Intel inline assembler (closely compatible to GAS, although more general in its handling of local references within inline code).
- GCC starting with version 4.6 (although there was a 4.3 branch with certain support) and the Intel Compiler Suite starting with version 11.1 support AVX.
- The Open64 compiler version 4.5.1 supports AVX with -mavx flag.
- PathScale supports via the -mavx flag.
- The Vector Pascal compiler supports AVX via the -cpuAVX32 flag.
- The Visual Studio 2010/2012 compiler supports AVX via intrinsic and /arch:AVX switch.
- Other assemblers such as MASM VS2010 version, YASM,[16] FASM, NASM and JWASM.
Operating system support[edit]
AVX adds new register-state through the 256-bit wide YMM register file, so explicit operating system support is required to properly save and restore AVX’s expanded registers between context switches. The following operating system versions support AVX:
- DragonFly BSD: support added in early 2013.
- FreeBSD: support added in a patch submitted on January 21, 2012,[17] which was included in the 9.1 stable release[18]
- Linux: supported since kernel version 2.6.30,[19] released on June 9, 2009.[20]
- macOS: support added in 10.6.8 (Snow Leopard) update[21][unreliable source?] released on June 23, 2011. In fact, macOS Ventura does not support processors without the AVX2 instruction set. [22]
- OpenBSD: support added on March 21, 2015.[23]
- Solaris: supported in Solaris 10 Update 10 and Solaris 11
- Windows: supported in Windows 7 SP1, Windows Server 2008 R2 SP1,[24] Windows 8, Windows 10
- Windows Server 2008 R2 SP1 with Hyper-V requires a hotfix to support AMD AVX (Opteron 6200 and 4200 series) processors, KB2568088
Advanced Vector Extensions 2[edit]
Advanced Vector Extensions 2 (AVX2), also known as Haswell New Instructions,[25] is an expansion of the AVX instruction set introduced in Intel’s Haswell microarchitecture. AVX2 makes the following additions:
- expansion of most vector integer SSE and AVX instructions to 256 bits
- Gather support, enabling vector elements to be loaded from non-contiguous memory locations
- DWORD- and QWORD-granularity any-to-any permutes
- vector shifts.
Sometimes three-operand fused multiply-accumulate (FMA3) extension is considered part of AVX2, as it was introduced by Intel in the same processor microarchitecture. This is a separate extension using its own CPUID flag and is described on its own page and not below.
New instructions[edit]
| Instruction | Description |
|---|---|
VBROADCASTSS, VBROADCASTSD
|
Copy a 32-bit or 64-bit register operand to all elements of a XMM or YMM vector register. These are register versions of the same instructions in AVX1. There is no 128-bit version however, but the same effect can be simply achieved using VINSERTF128. |
VPBROADCASTB, VPBROADCASTW, VPBROADCASTD, VPBROADCASTQ
|
Copy an 8, 16, 32 or 64-bit integer register or memory operand to all elements of a XMM or YMM vector register. |
VBROADCASTI128
|
Copy a 128-bit memory operand to all elements of a YMM vector register. |
VINSERTI128
|
Replaces either the lower half or the upper half of a 256-bit YMM register with the value of a 128-bit source operand. The other half of the destination is unchanged. |
VEXTRACTI128
|
Extracts either the lower half or the upper half of a 256-bit YMM register and copies the value to a 128-bit destination operand. |
VGATHERDPD, VGATHERQPD, VGATHERDPS, VGATHERQPS
|
Gathers single or double precision floating point values using either 32 or 64-bit indices and scale. |
VPGATHERDD, VPGATHERDQ, VPGATHERQD, VPGATHERQQ
|
Gathers 32 or 64-bit integer values using either 32 or 64-bit indices and scale. |
VPMASKMOVD, VPMASKMOVQ
|
Conditionally reads any number of elements from a SIMD vector memory operand into a destination register, leaving the remaining vector elements unread and setting the corresponding elements in the destination register to zero. Alternatively, conditionally writes any number of elements from a SIMD vector register operand to a vector memory operand, leaving the remaining elements of the memory operand unchanged. |
VPERMPS, VPERMD
|
Shuffle the eight 32-bit vector elements of one 256-bit source operand into a 256-bit destination operand, with a register or memory operand as selector. |
VPERMPD, VPERMQ
|
Shuffle the four 64-bit vector elements of one 256-bit source operand into a 256-bit destination operand, with a register or memory operand as selector. |
VPERM2I128
|
Shuffle (two of) the four 128-bit vector elements of two 256-bit source operands into a 256-bit destination operand, with an immediate constant as selector. |
VPBLENDD
|
Doubleword immediate version of the PBLEND instructions from SSE4. |
VPSLLVD, VPSLLVQ
|
Shift left logical. Allows variable shifts where each element is shifted according to the packed input. |
VPSRLVD, VPSRLVQ
|
Shift right logical. Allows variable shifts where each element is shifted according to the packed input. |
VPSRAVD
|
Shift right arithmetically. Allows variable shifts where each element is shifted according to the packed input. |
CPUs with AVX2[edit]
- Intel
- Haswell processors (only Core and Xeon branded), Q2 2013
- Haswell E processors, Q3 2014
- Broadwell processors, Q4 2014
- Broadwell E processors, Q3 2016
- Skylake processors, Q3 2015
- Kaby Lake processors, Q3 2016 (ULV mobile)/Q1 2017 (desktop/mobile)
- Skylake-X processors, Q2 2017
- Coffee Lake processors, Q4 2017
- Cannon Lake processors, Q2 2018
- Cascade Lake processors, Q2 2019
- Ice Lake processors, Q3 2019
- Comet Lake processors, Q3 2019
- Tiger Lake (Core, Pentium and Celeron branded[11]) processors, Q3 2020
- Rocket Lake processors, Q1 2021
- Alder Lake (Xeon, Core, Pentium and Celeron branded[11]) processors, Q4 2021. Supported both in Golden Cove P-cores and Gracemont E-cores.
- Raptor Lake processors, Q4 2022
- Sapphire Rapids processors, Q1 2023
- Meteor Lake processors
- Arrow Lake processors
- Lunar Lake processors
- AMD
- Excavator processor and newer, Q2 2015
- Zen processors, Q1 2017
- Zen+ processors, Q2 2018
- Zen 2 processors, Q3 2019
- Zen 3 processors, Q4 2020
- Zen 4 processors, Q4 2022
- VIA:
- Nano QuadCore
- Eden X4
AVX-512[edit]
AVX-512 are 512-bit extensions to the 256-bit Advanced Vector Extensions SIMD instructions for x86 instruction set architecture proposed by Intel in July 2013, and are supported with Intel’s Knights Landing processor.[3]
AVX-512 instructions are encoded with the new EVEX prefix. It allows 4 operands, 8 new 64-bit opmask registers, scalar memory mode with automatic broadcast, explicit rounding control, and compressed displacement memory addressing mode. The width of the register file is increased to 512 bits and total register count increased to 32 (registers ZMM0-ZMM31) in x86-64 mode.
AVX-512 consists of multiple instruction subsets, not all of which are meant to be supported by all processors implementing them. The instruction set consists of the following:
- AVX-512 Foundation (F) – adds several new instructions and expands most 32-bit and 64-bit floating point SSE-SSE4.1 and AVX/AVX2 instructions with EVEX coding scheme to support the 512-bit registers, operation masks, parameter broadcasting, and embedded rounding and exception control
- AVX-512 Conflict Detection Instructions (CD) – efficient conflict detection to allow more loops to be vectorized, supported by Knights Landing[3]
- AVX-512 Exponential and Reciprocal Instructions (ER) – exponential and reciprocal operations designed to help implement transcendental operations, supported by Knights Landing[3]
- AVX-512 Prefetch Instructions (PF) – new prefetch capabilities, supported by Knights Landing[3]
- AVX-512 Vector Length Extensions (VL) – extends most AVX-512 operations to also operate on XMM (128-bit) and YMM (256-bit) registers (including XMM16-XMM31 and YMM16-YMM31 in x86-64 mode)[26]
- AVX-512 Byte and Word Instructions (BW) – extends AVX-512 to cover 8-bit and 16-bit integer operations[26]
- AVX-512 Doubleword and Quadword Instructions (DQ) – enhanced 32-bit and 64-bit integer operations[26]
- AVX-512 Integer Fused Multiply Add (IFMA) – fused multiply add for 512-bit integers.[27]: 746
- AVX-512 Vector Byte Manipulation Instructions (VBMI) adds vector byte permutation instructions which are not present in AVX-512BW.
- AVX-512 Vector Neural Network Instructions Word variable precision (4VNNIW) – vector instructions for deep learning.
- AVX-512 Fused Multiply Accumulation Packed Single precision (4FMAPS) – vector instructions for deep learning.
- VPOPCNTDQ – count of bits set to 1.[28]
- VPCLMULQDQ – carry-less multiplication of quadwords.[28]
- AVX-512 Vector Neural Network Instructions (VNNI) – vector instructions for deep learning.[28]
- AVX-512 Galois Field New Instructions (GFNI) – vector instructions for calculating Galois field.[28]
- AVX-512 Vector AES instructions (VAES) – vector instructions for AES coding.[28]
- AVX-512 Vector Byte Manipulation Instructions 2 (VBMI2) – byte/word load, store and concatenation with shift.[28]
- AVX-512 Bit Algorithms (BITALG) – byte/word bit manipulation instructions expanding VPOPCNTDQ.[28]
- AVX-512 Bfloat16 Floating-Point Instructions (BF16) – vector instructions for AI acceleration.
- AVX-512 Half-Precision Floating-Point Instructions (FP16) – vector instructions for operating on floating-point and complex numbers with reduced precision.
Only the core extension AVX-512F (AVX-512 Foundation) is required by all implementations, though all current processors also support CD (conflict detection); computing coprocessors will additionally support ER, PF, 4VNNIW, 4FMAPS, and VPOPCNTDQ, while central processors will support VL, DQ, BW, IFMA, VBMI, VPOPCNTDQ, VPCLMULQDQ etc.
The updated SSE/AVX instructions in AVX-512F use the same mnemonics as AVX versions; they can operate on 512-bit ZMM registers, and will also support 128/256 bit XMM/YMM registers (with AVX-512VL) and byte, word, doubleword and quadword integer operands (with AVX-512BW/DQ and VBMI).[27]: 23
CPUs with AVX-512[edit]
| AVX-512 Subset | F | CD | ER | PF | 4FMAPS | 4VNNIW | VPOPCNTDQ | VL | DQ | BW | IFMA | VBMI | VBMI2 | BITALG | VNNI | BF16 | VPCLMULQDQ | GFNI | VAES | VP2INTERSECT | FP16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Intel Knights Landing (2016) | Yes | Yes | No | ||||||||||||||||||
| Intel Knights Mill (2017) | Yes | No | |||||||||||||||||||
| Intel Skylake-SP, Skylake-X (2017) | No | No | Yes | No | |||||||||||||||||
| Intel Cannon Lake (2018) | Yes | No | |||||||||||||||||||
| Intel Cascade Lake-SP (2019) | No | Yes | No | ||||||||||||||||||
| Intel Cooper Lake (2020) | No | Yes | No | ||||||||||||||||||
| Intel Ice Lake (2019) | Yes | No | Yes | No | |||||||||||||||||
| Intel Tiger Lake (2020) | Yes | No | |||||||||||||||||||
| Intel Rocket Lake (2021) | No | ||||||||||||||||||||
| Intel Alder Lake (2021) | Not officially supported, but can be enabled on some motherboards with some BIOS versionsNote 1 | ||||||||||||||||||||
| AMD Zen 4 (2022) | Yes | Yes | No | ||||||||||||||||||
| Intel Sapphire Rapids (2023) | No | Yes |
[29]
^Note 1 : AVX-512 is disabled by default in Alder Lake processors. On some motherboards with some BIOS versions, AVX-512 can be enabled in the BIOS, but this requires disabling E-cores.[30] However, Intel has begun fusing AVX-512 off on newer Alder Lake processors.[31]
Compilers supporting AVX-512[edit]
- GCC 4.9 and newer[32]
- Clang 3.9 and newer[33]
- ICC 15.0.1 and newer[34]
- Microsoft Visual Studio 2017 C++ Compiler[35]
AVX-VNNI, AVX-IFMA[edit]
AVX-VNNI is a VEX-coded variant of the AVX512-VNNI instruction set extension. Similarly, AVX-IFMA is a VEX-coded variant of AVX512-IFMA. These extensions provide the same sets of operations as their AVX-512 counterparts, but are limited to 256-bit vectors and do not support any additional features of EVEX encoding, such as broadcasting, opmask registers or accessing more than 16 vector registers. These extensions allow to support VNNI and IFMA operations even when full AVX-512 support is not implemented in the processor.
CPUs with AVX-VNNI[edit]
- Intel
- Alder Lake processors, Q4 2021
- Raptor Lake processors, Q4 2022
- Sapphire Rapids processors, Q1 2023
- Meteor Lake processors
- Emerald Rapids processors
- Arrow Lake processors
- Lunar Lake processors
CPUs with AVX-IFMA[edit]
- Intel
- Sierra Forest processors
- Grand Ridge processors
- Meteor Lake processors
AVX10[edit]
AVX10, announced in August 2023, is a new, «converged» AVX instruction set. It addresses several issues of AVX-512, in particular that it is split into too many parts[36] (20 feature flags) and that it makes 512-bit vectors mandatory to support. AVX10 presents a simplified CPUID interface to test for instruction support, consisting of the AVX10 version number (indicating the set of instructions supported, with later versions always being a superset of an earlier one) and the available maximum vector length (256 or 512 bits).[37] A combined notation is used to indicate the version and vector length: for example, AVX10.2/256 indicates that a CPU is capable of the second version of AVX10 with a maximum vector width of 256 bits.[38]
The first and «early» version of AVX10, notated AVX10.1, will not introduce any instructions or encoding features beyond what is already in AVX-512 (F, CD, VL, DQ, BW, IFMA, VBMI, VBMI2, BITALG, VNNI, GFNI, VPOPCNTDQ, VPCLMULQDQ, VAES, BF16, FP16). The second and «fully-featured» version, AVX10.2, introduces new features such as YMM embedded rounding and Suppress All Exception. For CPUs supporting AVX10 and 512-bit vectors, all legacy AVX-512 feature flags will remain set to facilitate applications supporting AVX-512 to continue using AVX-512 instructions.[38]
AVX10.1/512 will be available on Granite Rapids.[38]
APX[edit]
APX is a new extension. It is not focused on vector computation, but provides RISC-like extensions to the x86-64 architecture by doubling the number of general purpose registers to 32 and introducing three-operand instruction formats. AVX is only tangentially affected as APX introduces extended operands.[39][40]
Applications[edit]
- Suitable for floating point-intensive calculations in multimedia, scientific and financial applications (AVX2 adds support for integer operations).
- Increases parallelism and throughput in floating point SIMD calculations.
- Reduces register load due to the non-destructive instructions.
- Improves Linux RAID software performance (required AVX2, AVX is not sufficient)[41]
Software[edit]
- Blender uses AVX, AVX2 and AVX-512 in the Cycles render engine.[42]
- Bloombase uses AVX, AVX2 and AVX-512 in their Bloombase Cryptographic Module (BCM).
- Botan uses both AVX and AVX2 when available to accelerate some algorithms, like ChaCha.
- BSAFE C toolkits uses AVX and AVX2 where appropriate to accelerate various cryptographic algorithms.[43]
- Crypto++ uses both AVX and AVX2 when available to accelerate some algorithms, like Salsa and ChaCha.
- OpenSSL uses AVX- and AVX2-optimized cryptographic functions since version 1.0.2.[44] Support for AVX-512 was added in version 3.0.0.[45] Some of these optimizations are also present in various clones and forks, like LibreSSL.
- Prime95/MPrime, the software used for GIMPS, started using the AVX instructions since version 27.1, AVX2 since 28.6 and AVX-512 since 29.1.[46]
- dav1d AV1 decoder can use AVX2 and AVX-512 on supported CPUs.[47][48]
- SVT-AV1 AV1 encoder can use AVX2 and AVX-512 to accelerate video encoding.[49]
- dnetc, the software used by distributed.net, has an AVX2 core available for its RC5 project and will soon release one for its OGR-28 project.
- Einstein@Home uses AVX in some of their distributed applications that search for gravitational waves.[50]
- Folding@home uses AVX on calculation cores implemented with GROMACS library.
- Helios uses AVX and AVX2 hardware acceleration on 64-bit x86 hardware.[51]
- Horizon: Zero Dawn uses AVX in its Decima game engine.
- RPCS3, an open source PlayStation 3 emulator, uses AVX2 and AVX-512 instructions to emulate PS3 games.
- Network Device Interface, an IP video/audio protocol developed by NewTek for live broadcast production, uses AVX and AVX2 for increased performance.
- TensorFlow since version 1.6 and tensorflow above versions requires CPU supporting at least AVX.[52]
- x264, x265 and VTM video encoders can use AVX2 or AVX-512 to speed up encoding.
- Various CPU-based cryptocurrency miners (like pooler’s cpuminer for Bitcoin and Litecoin) use AVX and AVX2 for various cryptography-related routines, including SHA-256 and scrypt.
- libsodium uses AVX in the implementation of scalar multiplication for Curve25519 and Ed25519 algorithms, AVX2 for BLAKE2b, Salsa20, ChaCha20, and AVX2 and AVX-512 in implementation of Argon2 algorithm.
- libvpx open source reference implementation of VP8/VP9 encoder/decoder, uses AVX2 or AVX-512 when available.
- libjpeg-turbo uses AVX2 to accelerate image processing.
- FFTW can utilize AVX, AVX2 and AVX-512 when available.
- LLVMpipe, a software OpenGL renderer in Mesa using Gallium and LLVM infrastructure, uses AVX2 when available.
- glibc uses AVX2 (with FMA) and AVX-512 for optimized implementation of various mathematical (i.e.
expf,sinf,powf,atanf,atan2f) and string (memmove,memcpy, etc.) functions in libc. - Linux kernel can use AVX or AVX2, together with AES-NI as optimized implementation of AES-GCM cryptographic algorithm.
- Linux kernel uses AVX or AVX2 when available, in optimized implementation of multiple other cryptographic ciphers: Camellia, CAST5, CAST6, Serpent, Twofish, MORUS-1280, and other primitives: Poly1305, SHA-1, SHA-256, SHA-512, ChaCha20.
- POCL, a portable Computing Language, that provides implementation of OpenCL, makes use of AVX, AVX2 and AVX-512 when possible.
- .NET and .NET Framework can utilize AVX, AVX2 through the generic
System.Numerics.Vectorsnamespace. - .NET Core, starting from version 2.1 and more extensively after version 3.0 can directly use all AVX, AVX2 intrinsics through the
System.Runtime.Intrinsics.X86namespace. - EmEditor 19.0 and above uses AVX2 to speed up processing.[53]
- Native Instruments’ Massive X softsynth requires AVX.[54]
- Microsoft Teams uses AVX2 instructions to create a blurred or custom background behind video chat participants,[55] and for background noise suppression.[56]
- Pale Moon custom Windows builds greatly increase browsing speed due to the use of AVX2.
- simdjson, a JSON parsing library, uses AVX2 and AVX-512 to achieve improved decoding speed.[57][58]
- x86-simd-sort, a library with sorting algorithms for 16, 32 and 64-bit numeric data types, uses AVX2 and AVX-512. The library is used in NumPy and OpenJDK to accelerate sorting algorithms.[59]
- zlib-ng, an optimized version of zlib, contains AVX2 and AVX-512 versions of some data compression algorithms.
- Tesseract OCR engine uses AVX, AVX2 and AVX-512 to accelerate character recognition.[60]
Downclocking[edit]
Since AVX instructions are wider and generate more heat, some Intel processors have provisions to reduce the Turbo Boost frequency limit when such instructions are being executed. On Skylake and its derivatives, the throttling is divided into three levels:[61][62]
- L0 (100%): The normal turbo boost limit.
- L1 (~85%): The «AVX boost» limit. Soft-triggered by 256-bit «heavy» (floating-point unit: FP math and integer multiplication) instructions. Hard-triggered by «light» (all other) 512-bit instructions.
- L2 (~60%):[dubious – discuss] The «AVX-512 boost» limit. Soft-triggered by 512-bit heavy instructions.
The frequency transition can be soft or hard. Hard transition means the frequency is reduced as soon as such an instruction is spotted; soft transition means that the frequency is reduced only after reaching a threshold number of matching instructions. The limit is per-thread.[61]
In Ice Lake, only two levels persist:[63]
- L0 (100%): The normal turbo boost limit.
- L1 (~97%): Triggered by any 512-bit instructions, but only when single-core boost is active; not triggered when multiple cores are loaded.
Rocket Lake processors do not trigger frequency reduction upon executing any kind of vector instructions regardless of the vector size.[63] However, downclocking can still happen due to other reasons, such as reaching thermal and power limits.
Downclocking means that using AVX in a mixed workload with an Intel processor can incur a frequency penalty. Avoiding the use of wide and heavy instructions help minimize the impact in these cases. AVX-512VL allows for using 256-bit or 128-bit operands in AVX-512, making it a sensible default for mixed loads.[64]
On supported and unlocked variants of processors that down-clock, the ratios are adjustable and may be turned off (set to 0x) entirely via Intel’s Overclocking / Tuning utility or in BIOS if supported there.[65]
See also[edit]
- F16C instruction set extension
- Memory Protection Extensions
- Scalable Vector Extension for ARM — a new vector instruction set (supplementing VFP and NEON) similar to AVX-512, with some additional features.
References[edit]
- ^ Kanter, David (September 25, 2010). «Intel’s Sandy Bridge Microarchitecture». www.realworldtech.com. Retrieved February 17, 2018.
- ^ Hruska, Joel (October 24, 2011). «Analyzing Bulldozer: Why AMD’s chip is so disappointing — Page 4 of 5 — ExtremeTech». ExtremeTech. Retrieved February 17, 2018.
- ^ a b c d e James Reinders (July 23, 2013), AVX-512 Instructions, Intel, retrieved August 20, 2013
- ^ «Intel Xeon Phi Processor 7210 (16GB, 1.30 GHz, 64 core) Product Specifications». Intel ARK (Product Specs). Retrieved March 16, 2018.
- ^ «14.9». Intel 64 and IA-32 Architectures Software Developer’s Manual Volume 1: Basic Architecture (PDF) (-051US ed.). Intel Corporation. p. 349. Retrieved August 23, 2014.
Memory arguments for most instructions with VEX prefix operate normally without causing #GP(0) on any byte-granularity alignment (unlike Legacy SSE instructions).
- ^ «i386 and x86-64 Options — Using the GNU Compiler Collection (GCC)». Retrieved February 9, 2014.
- ^ «The microarchitecture of Intel, AMD and VIA CPUs: An optimization guide for assembly programmers and compiler makers» (PDF). Retrieved October 17, 2016.
- ^ «Chess programming AVX2». Archived from the original on July 10, 2017. Retrieved October 17, 2016.
- ^ «Intel Offers Peek at Nehalem and Larrabee». ExtremeTech. March 17, 2008.
- ^ «Intel Core i7-3960X Processor Extreme Edition». Retrieved January 17, 2012.
- ^ a b c «Intel® Celeron® 6305 Processor (4M Cache, 1.80 GHz, with IPU) Product Specifications». ark.intel.com. Retrieved November 10, 2020.
- ^ «Does a Processor with AVX2 or AVX-512 Support AVX Instructions?». ark.intel.com. Retrieved April 27, 2022.
- ^ Dave Christie (May 7, 2009), Striking a balance, AMD Developer blogs, archived from the original on November 9, 2013, retrieved January 17, 2012
- ^ New «Bulldozer» and «Piledriver» Instructions (PDF), AMD, October 2012
- ^ «What’s New — RAD Studio». docwiki.embarcadero.com. Retrieved September 17, 2021.
- ^ «YASM 0.7.0 Release Notes». yasm.tortall.net.
- ^ Add support for the extended FPU states on amd64, both for native 64bit and 32bit ABIs, svnweb.freebsd.org, January 21, 2012, retrieved January 22, 2012
- ^ «FreeBSD 9.1-RELEASE Announcement». Retrieved May 20, 2013.
- ^ x86: add linux kernel support for YMM state, retrieved July 13, 2009
- ^ Linux 2.6.30 — Linux Kernel Newbies, retrieved July 13, 2009
- ^ Twitter, retrieved June 23, 2010
- ^ «Devs are making progress getting macOS Ventura to run on unsupported, decade-old Macs». August 23, 2022.
- ^ Add support for saving/restoring FPU state using the XSAVE/XRSTOR., retrieved March 25, 2015
- ^ Floating-Point Support for 64-Bit Drivers, retrieved December 6, 2009
- ^ Haswell New Instruction Descriptions Now Available, Software.intel.com, retrieved January 17, 2012
- ^ a b c James Reinders (July 17, 2014). «Additional AVX-512 instructions». Intel. Retrieved August 3, 2014.
- ^ a b «Intel Architecture Instruction Set Extensions Programming Reference» (PDF). Intel. Retrieved January 29, 2014.
- ^ a b c d e f g «Intel® Architecture Instruction Set Extensions and Future Features Programming Reference». Intel. Retrieved October 16, 2017.
- ^ «Intel® Software Development Emulator | Intel® Software». software.intel.com. Retrieved June 11, 2016.
- ^ Cutress, Ian; Frumusanu, Andrei. «The Intel 12th Gen Core i9-12900K Review: Hybrid Performance Brings Hybrid Complexity». AnandTech. Retrieved November 5, 2021.
- ^ Alcorn, Paul (March 2, 2022). «Intel Nukes Alder Lake’s AVX-512 Support, Now Fuses It Off in Silicon». Tom’s Hardware. Retrieved October 3, 2022.
- ^ «GCC 4.9 Release Series — Changes, New Features, and Fixes – GNU Project — Free Software Foundation (FSF)». gcc.gnu.org. Retrieved April 3, 2017.
- ^ «LLVM 3.9 Release Notes — LLVM 3.9 documentation». releases.llvm.org. Retrieved April 3, 2017.
- ^ «Intel® Parallel Studio XE 2015 Composer Edition C++ Release Notes | Intel® Software». software.intel.com. Retrieved April 3, 2017.
- ^ «Microsoft Visual Studio 2017 Supports Intel® AVX-512». July 11, 2017.
- ^ Mann, Tobias (August 15, 2023). «Intel’s AVX10 promises benefits of AVX-512 without baggage». www.theregister.com. Retrieved August 20, 2023.
- ^ «The Converged Vector ISA: Intel® Advanced Vector Extensions 10 Technical Paper». Intel.
- ^ a b c «Intel® Advanced Vector Extensions 10 (Intel® AVX10) Architecture Specification». Intel.
- ^ «Intel® Advanced Performance Extensions (Intel® APX) Architecture Specification». Intel.
- ^ Robinson, Dan (July 26, 2023). «Intel discloses x86 and vector instructions for future chips». www.theregister.com. Retrieved August 20, 2023.
- ^ «Linux RAID». LWN. February 17, 2013. Archived from the original on April 15, 2013.
- ^ Jaroš, Milan; Strakoš, Petr; Říha, Lubomír (May 28, 2022). «Rendering in Blender using AVX-512 Vectorization» (PDF). Intel eXtreme Performance Users Group. Technical University of Ostrava. Retrieved October 28, 2022.
- ^ «Comparison of BSAFE cryptographic library implementations». July 25, 2023.
- ^ «Improving OpenSSL Performance». May 26, 2015. Retrieved February 28, 2017.
- ^ «OpenSSL 3.0.0 release notes». GitHub. September 7, 2021.
- ^ «Prime95 release notes». Retrieved July 10, 2022.
- ^ «dav1d: performance and completion of the first release». November 21, 2018. Retrieved November 22, 2018.
- ^ «dav1d 0.6.0 release notes». March 6, 2020.
- ^ «SVT-AV1 0.7.0 release notes». September 26, 2019.
- ^ «Einstein@Home Applications».
- ^ «FAQ, Helios». Helios. Retrieved July 5, 2021.
- ^ «Tensorflow 1.6». GitHub.
- ^ New in Version 19.0 – EmEditor (Text Editor)
- ^ «MASSIVE X Requires AVX Compatible Processor». Native Instruments. Retrieved November 29, 2019.
- ^ «Hardware requirements for Microsoft Teams». Microsoft. Retrieved April 17, 2020.
- ^ «Reduce background noise in Teams meetings». Microsoft Support. Retrieved January 5, 2021.
- ^ Langdale, Geoff; Lemire, Daniel (2019). «Parsing Gigabytes of JSON per Second». The VLDB Journal. 28 (6): 941–960. arXiv:1902.08318. doi:10.1007/s00778-019-00578-5. S2CID 67856679.
- ^ «simdjson 2.1.0 release notes». GitHub. June 30, 2022.
- ^ Larabel, Michael (October 6, 2023). «OpenJDK Merges Intel’s x86-simd-sort For Speeding Up Data Sorting 7~15x». Phoronix.
- ^ Larabel, Michael (July 7, 2022). «Tesseract OCR 5.2 Engine Finds Success With AVX-512F». Phoronix.
- ^ a b Lemire, Daniel (September 7, 2018). «AVX-512: when and how to use these new instructions». Daniel Lemire’s blog.
- ^ BeeOnRope. «SIMD instructions lowering CPU frequency». Stack Overflow.
- ^ a b Downs, Travis (August 19, 2020). «Ice Lake AVX-512 Downclocking». Performance Matters blog.
- ^ «x86 — AVX 512 vs AVX2 performance for simple array processing loops». Stack Overflow.
- ^ «Intel® Extreme Tuning Utility (Intel® XTU) Guide to Overclocking : Advanced Tuning». Intel. Retrieved July 18, 2021.
See image in linked section, where AVX2 ratio has been set to 0.
External links[edit]
- Intel Intrinsics Guide
- x86 Assembly Language Reference Manual
В новой линейке процессоров Ryzen 7000 компания AMD обещает полную поддержку инструкций AVX-512. Тех самых, которые недавно заблокировала в своих процессорах для массовых платформ компания Intel. Для чего нужны эти инструкции, какую реальную пользу они несут, и будет ли поддержка AVX-512 реальным преимуществом AMD перед конкурентом?
Что такое AVX-512
Инструкции семейства Advanced Vector Extensions (AVX) являются дальнейшим развитием инструкций семейства Streaming SIMD Extensions (SSE). Прародителем последних, в свою очередь, являются инструкции MultiMedia eXtensions (MMX), впервые появившиеся в 1997 году в процессорах Pentium MMX. За четверть века эволюции этого семейства инструкций их основное предназначение оставалось неизменным: ускорение работы программного обеспечения, работающего с мультимедийным контентом, к которому относится фото, видео или 3D-модели.
MMX использует 64-битные регистры, семейство SSE удваивает этот параметр до 128 бит. AVX первого и второго поколения работает с 256-битными регистрами, а последний в линейке — AVX-512 (как следует из названия, с 512-битными).

С каждой версией мультимедийных инструкций появляется все больше сценариев для их использования благодаря постоянному появлению новых функций. А расширение регистров, в свою очередь, дает возможность значительно ускорить работу этих сценариев. При грамотной оптимизации программного обеспечения для более «широких» инструкций можно добиться кратного повышения производительности по сравнению с использованием более «узких».
Почему Intel отказалась от AVX-512
Первой ранняя реализация 512-битных инструкций была применена в ускорителях вычислений Intel семейства Xeon Phi. Но по-настоящему массовое распространение уже стандартизированный AVX-512 получил в серверных процессорах Xeon на архитектуре Skylake. В десктоп новые инструкции впервые попали в 2017 году, вместе с HEDT-платформой Intel на базе чипсета X299 и процессоров Core i7-X 7000 серии, использующих архитектуру серверных моделей. Позже в линейку процессоров, которые поддерживают AVX-512, добавились Core-X 9000 и 10000 серии, работающие на той же платформе.

Несмотря на то, что массовые платформы тех лет тоже полагались на архитектуру Skylake, поддержки 512-битных инструкций в них не было. Дебют AVX-512 в массовых десктопных и мобильных платформах состоялся с 11 поколением процессоров Core архитектур Rocket Lake и Ice Lake в 2021 году.
При выходе процессоров 12 поколения на новой гибридной архитектуре Intel уточнила, что для задействования AVX-512 нужно будет отключить малые ядра, так как у них поддержки данных инструкций нет. Но позже компания решила вообще отказаться от AVX-512 на процессорах данного поколения в новых ревизиях процессоров. А чтобы ее не было и в старых, обязала производителей материнских плат выпустить обновления BIOS, отключающие данную технологию.
Почему? Причин на это несколько. Во-первых, при использовании новых инструкций и так не холодные процессоры Alder Lake потребляют намного больше энергии и еще сильнее разогреваются — температуры под нагрузкой увеличиваются на десяток-полтора градусов. При таком использовании приемлемые результаты охлаждения начинают показывать только дорогие кулеры и водяные СО. То же самое было и в предыдущем поколении Rocket Lake при задействовании AVX-512.

Во-вторых, в линейке этих процессоров есть младшие модели без малых ядер. По этой причине AVX-512 у них должен быть активен по умолчанию, в отличие от «танцев с бубнами» с отключением малых ядер в BIOS для работы технологии у старших моделей. Это представляет последние в невыгодном свете.
В-третьих, Intel считает наличие 512-битной версии AVX в данный момент необязательным в массовых платформах по причине их малой распространенности в пользовательском программном обеспечении, в отличие от серверного.
Вернет ли Intel AVX-512 в массовые платформы? Да, но точно не в этом году. В новом 13 поколении процессоров Core малые ядра архитектуру не сменят, и AVX-512 в них не появится. Скорее всего, 512-битные мультимедийные расширения вернутся в 14 поколении процессоров Core, малые ядра которого получат новую процессорную архитектуру, то есть — не раньше конца следующего года.
Почему AMD пришла к AVX-512 только сейчас
Серверные процессоры AMD, в отличие от продукции конкурента, до сих пор не поддерживают AVX-512. AMD вводит поддержку нового набора инструкций только в этом году на десктопных Ryzen 7000, сердцем которых стала архитектура Zen 4. Позже будут выпущены серверные и HEDT-процессоры на той же архитектуре, которые унаследуют поддержку инструкций от младших собратьев.

При этом возникают два вопроса: почему AMD не добавила поддержку AVX-512 в серверы раньше? И почему, в отличие от конкурента, ее десктопные процессоры получат поддержку инструкций раньше серверных и HEDT? Ответ прост: все дело в унификации.
Все процессоры AMD собираются из одних и тех же чиплетов — как десктопные, так и серверные. Именно поэтому сначала представляются десктопные процессоры на новой архитектуре с малым количеством чиплетов, а позже — серверные и HEDT с большим количеством тех же самых базовых «кирпичиков».
Intel разрабатывает разные кристаллы для десктопных и серверных процессоров, поэтому ненужные блоки в десктопные кристаллы она может просто не включать еще на стадии их проектирования, как это было сделано с процессорами на архитектуре Skylake.
Смысла же добавлять инструкции AVX-512 у AMD до этого года было немного. Пользовательское программное обеспечение до сих пор умеет задействовать их с видимой пользой лишь в достаточно редких случаях. Серверное — немного чаще, но тоже не всегда. При этом в серверах процессоры AMD и так зачастую быстрее продукции конкурента даже без новых инструкций — просто за счет большего количества ядер.
Однако, рано или поздно новые инструкции должны были попасть и в процессоры AMD. Ryzen 7000 серии помимо новой архитектуры получили и новый техпроцесс производства — 5 нм, который положительно скажется на энергопотреблении в работе с энергоемким AVX-512. К тому же, серверное ПО все активнее разрабатывается с учетом AVX-512, а чиплеты архитектуры Zen 4 в следующем году попадут и в серверные процессоры. Поэтому компания решила, что время и для ее реализации AVX-512 уже пришло.

Для чего нужен AVX-512
Как и все предшественники, AVX-512 предназначен ускорить работу приложений, использующих мультимедийные инструкции для работы определенных алгоритмов. Например, AVX и AVX2 используются для ускорения конвертации видео, эмуляторов игровых приставок, работы некоторых инструментов в фото- и видеоредакторах, интеллектуального размытия фона в видеочатах, и т.д.
С массовым распространением AVX-512 многие из этих алгоритмов в течение нескольких лет получат и его поддержку. За счет более широких регистров новых инструкций, при должной оптимизации ПО, его работу можно будет заметно ускорить. Уже сегодня есть некоторое программное обеспечение, которое получает значительное ускорение от AVX-512, но пока его крайне мало. Например, эмулятор Play Station 3 под названием RPCS3 при его задействовании получает дополнительные 30% производительности.

Заметного ускорения за счет новых инструкций уже сегодня можно добиться и при кодировании видео формата HEVC. Представители AMD говорят о том, что данные инструкции в первую очередь пригодятся для программного обеспечения, которое задействует глубокое обучение и искусственный интеллект, а также различные техники масштабирования изображений.

AVX-512 сегодня
При всех преимуществах AVX-512 стоит помнить, что в основной массе программного обеспечения поддержка новых инструкций всегда внедряется достаточно медленно. В том числе потому, что практически вся работа, которую позволяют ускорить инструкции, может быть сделана либо без них, либо на старых версиях вроде SSE4.2. Именно поэтому большая часть возможностей современного ПО полагается на мультимедийные инструкции старых версий. Взять в пример те же игры — до сих пор много случаев, когда на выходе игры разработчик заявляет об обязательных требованиях в виде процессора с AVX, а через некоторое время игра получает патч, который делает ее запуск возможным и на процессорах без него.

Почему так происходит? Дело в том, что для реального ускорения работы за счет мультимедийных инструкций нужно хорошо оптимизировать код программы под их определенную версию. Если этой оптимизации нет, то что с AVX, что с SSE4.2 та же игра покажет почти одинаковую производительность, и тогда требовать для запуска проекта процессора с AVX будет просто бессмысленно.
Такое до сих пор сплошь и рядом даже с AVX2, которому в этом году исполнилось 9 лет, не говоря уже о AVX-512, который пока не использует ни одна игра. Так что любителям компьютерных игр насчет отсутствия у их процессоров новых инструкций еще как минимум несколько лет беспокоиться не стоит.
Даже когда первые проекты получат поддержку новых инструкций, не стоит ждать от этих реализаций значительного буста производительности. Примером может служить выпущенная через два года после появления инструкций AVX игра GRID 2, которая имела два исполняемых файла, работающих с AVX и SSE. В итоге обе версии на одном и том же «железе» показывают практически идентичную производительность.

Долгий путь AVX-512 еще только начинается. Сейчас эти инструкции востребованы в основном в узкоспециализированном ПО. Через некоторое время они станут несколько более распространенными, но только через десяток лет станут использоваться повсеместно. Поэтому переживать о том, что ваш процессор их не поддерживает, пока смысла нет.
Расширение набора команд Advanced Vector Extensions (AVX) представляет собой технологию, которая позволяет процессорам обрабатывать параллельные задачи с использованием векторных операций. AVX было введено компанией Intel в 2008 году и является значительным улучшением в области вычислений с плавающей точкой и обработки многопоточных задач.
Однако не все процессоры поддерживают AVX инструкции. Для того чтобы воспользоваться всеми преимуществами данной технологии, необходимо иметь совместимый процессор. Некоторые из наиболее популярных процессоров, поддерживающих AVX инструкции, включают в себя Intel Core i7 и i9, а также процессоры AMD Ryzen 7 и Threadripper.
AVX инструкции особенно полезны для приложений, требующих высокой производительности и параллельной обработки данных. Такие программы включают в себя компьютерные игры, моделирование и анализ данных, а также видеообработку и рендеринг.
В целом, выбор процессора, поддерживающего AVX инструкции, зависит от конкретных требований и нагрузки вашего ПК. Если вы планируете использовать приложения и задачи, которые требуют высокой производительности и обработки данными, то рекомендуется выбрать процессор, поддерживающий расширение AVX.
Содержание
- Процессоры Intel с поддержкой avx инструкций
- Популярные модели
- Поколения процессоров
- Процессоры AMD с поддержкой avx инструкций
- Рыночные лидеры
- Новинки и обновления
Процессоры Intel с поддержкой avx инструкций
AVX (Advanced Vector Extensions) – это набор инструкций, разработанных компанией Intel, который позволяет параллельно выполнять операции над векторными данными. Это позволяет значительно увеличить производительность работы современных процессоров. В зависимости от версии, набор инструкций AVX может быть отмечен как AVX, AVX2 или AVX-512.
Множество процессоров Intel поддерживают avx инструкции. Это включает в себя такие популярные линейки процессоров, как Intel Core i3, i5, i7, а также серверные процессоры Intel Xeon. Эти процессоры обеспечивают широкий спектр возможностей для выполнения сложных вычислений, используя векторизацию данных, таких как обработка сигналов, 3D-графика, статистика и многое другое.
Версии процессоров Intel с поддержкой AVX инструкций могут отличаться по функциональности и производительности. Например, процессоры нового поколения могут обеспечивать более высокую пропускную способность и более эффективную обработку векторных данных, чем их предшественники.
Если вам требуется работа с вычислениями, которые могут быть векторизованы, то процессоры Intel с поддержкой AVX инструкций являются отличным выбором. Они позволят вам выполнить задачи быстрее и эффективнее, что особенно важно для приложений, требующих обработки больших объемов данных или вычислительно сложных операций.
Популярные модели
Ниже приведены некоторые популярные модели процессоров, поддерживающие AVX инструкции:
| Модель процессора | Поддержка AVX инструкций |
|---|---|
| Intel Core i7-9700K | Да |
| AMD Ryzen 7 3700X | Да |
| Intel Core i9-9900K | Да |
| AMD Ryzen 9 3900X | Да |
| Intel Core i5-9600K | Да |
Это лишь некоторые из многочисленных моделей, поддерживающих AVX инструкции. Каждая из этих моделей предлагает высокую производительность для выполнения вычислительно сложных задач, использующих AVX инструкции.
Поколения процессоров
Процессоры разных поколений имеют различные характеристики и функциональность. Важно знать поколение процессора, чтобы определить его возможности и поддержку различных инструкций.
Среди поколений процессоров, которые поддерживают AVX (Advanced Vector Extensions) инструкции, можно выделить следующие:
— Поколение Sandy Bridge (2-ое поколение процессоров Intel Core)
— Поколение Ivy Bridge (3-е поколение процессоров Intel Core)
— Поколение Haswell (4-ое поколение процессоров Intel Core)
— Поколение Broadwell (5-ое поколение процессоров Intel Core)
— Поколение Skylake (6-ое поколение процессоров Intel Core)
— Поколение Kaby Lake (7-ое поколение процессоров Intel Core)
Каждое поколение процессоров представляет собой улучшенную версию предыдущего поколения, с новыми возможностями и технологиями. Это позволяет повысить производительность и эффективность вычислительных задач.
AVX инструкции, введенные во втором поколении процессоров Intel Core, предоставляют расширенные возможности для работы с векторными и многомерными данными. Они существенно ускоряют выполнение таких операций, как матричные умножения, обработка изображений и видео, алгоритмы машинного обучения и другие задачи, требующие интенсивных вычислений.
Процессоры AMD с поддержкой avx инструкций
Среди процессоров AMD, поддерживающих avx инструкции, можно выделить следующие модели:
- AMD Ryzen 5000 Series
- AMD Ryzen 4000 Series
- AMD Ryzen 3000 Series
- AMD Ryzen Threadripper 3000 Series
- AMD Ryzen Threadripper 2000 Series
- AMD Ryzen Threadripper Pro Series
- AMD EPYC Milan
- AMD EPYC Rome
Процессоры AMD с поддержкой avx инструкций позволяют улучшить производительность при работе с ресурсоемкими приложениями, такими как редактирование видео, обработка изображений, научные расчеты и другие задачи, требующие высокой вычислительной мощности.
Важно отметить, что для использования avx инструкций необходима поддержка операционной системы и соответствующих программных приложений.
Рыночные лидеры
| Производитель | Линейка процессоров |
|---|---|
| Intel | Core i7, i9 |
| Xeon | |
| AMD | Ryzen |
Процессоры Intel Core i7, i9 и Xeon являются основным выбором для профессиональных рабочих станций и серверов. Они обладают высокой производительностью и широкими возможностями векторных вычислений.
Процессоры AMD Ryzen, в свою очередь, идеально подходят для настольных компьютеров и мобильных устройств. Они предлагают отличную производительность по доступной цене и также поддерживают AVX инструкции.
Обе компании — Intel и AMD — постоянно работают над улучшением своих процессоров и добавлением новых функциональных возможностей. Поэтому лидерство этих компаний на рынке процессоров поддерживающих AVX инструкции остается неоспоримым.
Новинки и обновления
Современные процессоры активно развивают свои возможности и постоянно выпускаются новые модели с улучшенными характеристиками. Некоторые из них поддерживают набор инструкций AVX (Advanced Vector Extensions), позволяющих выполнять одновременно несколько операций над векторами данных и ускоряющих работу с многопоточными приложениями.
Среди последних новинок стоит отметить:
| Модель процессора | Версия AVX |
|---|---|
| Intel Core i9-10900K | AVX-512 |
| AMD Ryzen 9 5950X | AVX2 |
| Intel Core i7-10700K | AVX-512 |
| AMD Ryzen 7 5800X | AVX2 |
Эти процессоры являются примером новейших разработок и позволяют эффективно использовать возможности AVX, обеспечивая высокую производительность при выполнении сложных вычислений.
Производитель чипов представил набор инструкций AVX10 для замены горячего и энергозатратного метода AVX512. Первым продуктом Intel с аппаратной поддержкой AVX10 станет Xeon следующего поколения Granite Rapids.
Intel AVX10 ISA будет доступен в двух версиях: с предварительным включением (AVX10.1) и с последующим включением (AVX10.2). Обе версии ISA поддерживают 512-битные вычисления FP/int, вырезанные из последних поколений чипов, таких как Alder Lake и Raptor Lake.
Advanced Performance Extensions (APX), которая увеличивает количество регистров общего назначения с 16 до 32. Согласно объяснению Intel, код, скомпилированный с помощью Intel APX, на 10% меньше нагружает ядра и на 20% компактнее, чем код, адаптированный под Intel 64. Это означает, что APX-код не только выполняется быстрее, но и имеет меньшее потребление, что делает его интересным вариантом для разработчиков, заботящихся о производительности. Поддержка аналогичного функционала на производительных и энергоэффективных ядрах увеличит IPC новых процессоров.
Компания подтвердила, что AVX10 ISA будет поддерживать клиентские, так и серверные продукты.
Больше новостей из мира игр, софта и железа можно узнать на моём канале.
9.9K
показов
2.7K
открытий
: Extensions to the x86 instruction set architecture for microprocessors from Intel and AMD
Advanced Vector Extensions (AVX) are extensions to the x86 instruction set architecture for microprocessors from Intel and Advanced Micro Devices (AMD). They were proposed by Intel in March 2008 and first supported by Intel with the Sandy Bridge[1] processor shipping in Q1 2011 and later by AMD with the Bulldozer[2] processor shipping in Q3 2011. AVX provides new features, new instructions and a new coding scheme.
AVX2 (also known as Haswell New Instructions) expands most integer commands to 256 bits and introduces new instructions. They were first supported by Intel with the Haswell processor, which shipped in 2013.
AVX-512 expands AVX to 512-bit support using a new EVEX prefix encoding proposed by Intel in July 2013 and first supported by Intel with the Knights Landing co-processor, which shipped in 2016.[3][4] In conventional processors, AVX-512 was introduced with Skylake server and HEDT processors in 2017.
Advanced Vector Extensions
AVX uses sixteen YMM registers to perform a single instruction on multiple pieces of data (see SIMD). Each YMM register can hold and do simultaneous operations (math) on:
- eight 32-bit single-precision floating point numbers or
- four 64-bit double-precision floating point numbers.
The width of the SIMD registers is increased from 128 bits to 256 bits, and renamed from XMM0–XMM7 to YMM0–YMM7 (in x86-64 mode, from XMM0–XMM15 to YMM0–YMM15). The legacy SSE instructions can be still utilized via the VEX prefix to operate on the lower 128 bits of the YMM registers.
| 511 256 | 255 128 | 127 0 |
| ZMM0 | YMM0 | XMM0 |
| ZMM1 | YMM1 | XMM1 |
| ZMM2 | YMM2 | XMM2 |
| ZMM3 | YMM3 | XMM3 |
| ZMM4 | YMM4 | XMM4 |
| ZMM5 | YMM5 | XMM5 |
| ZMM6 | YMM6 | XMM6 |
| ZMM7 | YMM7 | XMM7 |
| ZMM8 | YMM8 | XMM8 |
| ZMM9 | YMM9 | XMM9 |
| ZMM10 | YMM10 | XMM10 |
| ZMM11 | YMM11 | XMM11 |
| ZMM12 | YMM12 | XMM12 |
| ZMM13 | YMM13 | XMM13 |
| ZMM14 | YMM14 | XMM14 |
| ZMM15 | YMM15 | XMM15 |
| ZMM16 | YMM16 | XMM16 |
| ZMM17 | YMM17 | XMM17 |
| ZMM18 | YMM18 | XMM18 |
| ZMM19 | YMM19 | XMM19 |
| ZMM20 | YMM20 | XMM20 |
| ZMM21 | YMM21 | XMM21 |
| ZMM22 | YMM22 | XMM22 |
| ZMM23 | YMM23 | XMM23 |
| ZMM24 | YMM24 | XMM24 |
| ZMM25 | YMM25 | XMM25 |
| ZMM26 | YMM26 | XMM26 |
| ZMM27 | YMM27 | XMM27 |
| ZMM28 | YMM28 | XMM28 |
| ZMM29 | YMM29 | XMM29 |
| ZMM30 | YMM30 | XMM30 |
| ZMM31 | YMM31 | XMM31 |
AVX introduces a three-operand SIMD instruction format called VEX coding scheme, where the destination register is distinct from the two source operands. For example, an SSE instruction using the conventional two-operand form a ← a + b can now use a non-destructive three-operand form c ← a + b, preserving both source operands. Originally, AVX’s three-operand format was limited to the instructions with SIMD operands (YMM), and did not include instructions with general purpose registers (e.g. EAX). It was later used for coding new instructions on general purpose registers in later extensions, such as BMI. VEX coding is also used for instructions operating on the k0-k7 mask registers that were introduced with AVX-512.
The alignment requirement of SIMD memory operands is relaxed.[5] Unlike their non-VEX coded counterparts, most VEX coded vector instructions no longer require their memory operands to be aligned to the vector size. Notably, the VMOVDQA instruction still requires its memory operand to be aligned.
The new VEX coding scheme introduces a new set of code prefixes that extends the opcode space, allows instructions to have more than two operands, and allows SIMD vector registers to be longer than 128 bits. The VEX prefix can also be used on the legacy SSE instructions giving them a three-operand form, and making them interact more efficiently with AVX instructions without the need for VZEROUPPER and VZEROALL.
The AVX instructions support both 128-bit and 256-bit SIMD. The 128-bit versions can be useful to improve old code without needing to widen the vectorization, and avoid the penalty of going from SSE to AVX, they are also faster on some early AMD implementations of AVX. This mode is sometimes known as AVX-128.[6]
New instructions
These AVX instructions are in addition to the ones that are 256-bit extensions of the legacy 128-bit SSE instructions; most are usable on both 128-bit and 256-bit operands.
| Instruction | Description |
|---|---|
VBROADCASTSS, VBROADCASTSD, VBROADCASTF128
|
Copy a 32-bit, 64-bit or 128-bit memory operand to all elements of a XMM or YMM vector register. |
VINSERTF128
|
Replaces either the lower half or the upper half of a 256-bit YMM register with the value of a 128-bit source operand. The other half of the destination is unchanged. |
VEXTRACTF128
|
Extracts either the lower half or the upper half of a 256-bit YMM register and copies the value to a 128-bit destination operand. |
VMASKMOVPS, VMASKMOVPD
|
Conditionally reads any number of elements from a SIMD vector memory operand into a destination register, leaving the remaining vector elements unread and setting the corresponding elements in the destination register to zero. Alternatively, conditionally writes any number of elements from a SIMD vector register operand to a vector memory operand, leaving the remaining elements of the memory operand unchanged. On the AMD Jaguar processor architecture, this instruction with a memory source operand takes more than 300 clock cycles when the mask is zero, in which case the instruction should do nothing. This appears to be a design flaw.[7] |
VPERMILPS, VPERMILPD
|
Permute In-Lane. Shuffle the 32-bit or 64-bit vector elements of one input operand. These are in-lane 256-bit instructions, meaning that they operate on all 256 bits with two separate 128-bit shuffles, so they can not shuffle across the 128-bit lanes.[8] |
VPERM2F128
|
Shuffle the four 128-bit vector elements of two 256-bit source operands into a 256-bit destination operand, with an immediate constant as selector. |
VTESTPS, VTESTPD
|
Packed bit test of the packed single-precision or double-precision floating-point sign bits, setting or clearing the ZF flag based on AND and CF flag based on ANDN. |
VZEROALL
|
Set all YMM registers to zero and tag them as unused. Used when switching between 128-bit use and 256-bit use. |
VZEROUPPER
|
Set the upper half of all YMM registers to zero. Used when switching between 128-bit use and 256-bit use. |
CPUs with AVX
- Intel
- Sandy Bridge processors, Q1 2011[9]
- Sandy Bridge E processors, Q4 2011[10]
- Ivy Bridge processors, Q1 2012
- Ivy Bridge E processors, Q3 2013
- Haswell processors, Q2 2013
- Haswell E processors, Q3 2014
- Broadwell processors, Q4 2014
- Skylake processors, Q3 2015
- Broadwell E processors, Q2 2016
- Kaby Lake processors, Q3 2016 (ULV mobile)/Q1 2017 (desktop/mobile)
- Skylake-X processors, Q2 2017
- Coffee Lake processors, Q4 2017
- Cannon Lake processors, Q2 2018
- Whiskey Lake processors, Q3 2018
- Cascade Lake processors, Q4 2018
- Ice Lake processors, Q3 2019
- Comet Lake processors (only Core and Xeon branded), Q3 2019
- Tiger Lake (Core, Pentium and Celeron branded[11]) processors, Q3 2020
- Rocket Lake processors, Q1 2021
- Alder Lake (Xeon, Core, Pentium and Celeron branded) processors, Q4 2021. Supported both in Golden Cove P-cores and Gracemont E-cores.
- Raptor Lake processors, Q4 2022
- Sapphire Rapids processors, Q1 2023
- Meteor Lake processors
- Arrow Lake processors
- Lunar Lake processors
Not all CPUs from the listed families support AVX. Generally, CPUs with the commercial denomination Core i3/i5/i7/i9 support them, whereas Pentium and Celeron CPUs before Tiger Lake[12] do not.
- AMD:
- Jaguar-based processors and newer
- Puma-based processors and newer
- «Heavy Equipment» processors
- Bulldozer-based processors, Q4 2011[13]
- Piledriver-based processors, Q4 2012[14]
- Steamroller-based processors, Q1 2014
- Excavator-based processors and newer, 2015
- Zen-based processors, Q1 2017
- Zen+-based processors, Q2 2018
- Zen 2-based processors, Q3 2019
- Zen 3 processors, Q4 2020
- Zen 4 processors, Q4 2022
Issues regarding compatibility between future Intel and AMD processors are discussed under XOP instruction set.
- VIA:
- Nano QuadCore
- Eden X4
- Zhaoxin:
- WuDaoKou-based processors (KX-5000 and KH-20000)
Compiler and assembler support
- Absoft supports with -mavx flag.
- The Free Pascal compiler supports AVX and AVX2 with the -CfAVX and -CfAVX2 switches from version 2.7.1.
- RAD studio (v11.0 Alexandria) supports AVX2 and AVX512.[15]
- The GNU Assembler (GAS) inline assembly functions support these instructions (accessible via GCC), as do Intel primitives and the Intel inline assembler (closely compatible to GAS, although more general in its handling of local references within inline code).
- GCC starting with version 4.6 (although there was a 4.3 branch with certain support) and the Intel Compiler Suite starting with version 11.1 support AVX.
- The Open64 compiler version 4.5.1 supports AVX with -mavx flag.
- PathScale supports via the -mavx flag.
- The Vector Pascal compiler supports AVX via the -cpuAVX32 flag.
- The Visual Studio 2010/2012 compiler supports AVX via intrinsic and /arch:AVX switch.
- Other assemblers such as MASM VS2010 version, YASM,[16] FASM, NASM and JWASM.
Operating system support
AVX adds new register-state through the 256-bit wide YMM register file, so explicit operating system support is required to properly save and restore AVX’s expanded registers between context switches. The following operating system versions support AVX:
- DragonFly BSD: support added in early 2013.
- FreeBSD: support added in a patch submitted on January 21, 2012,[17] which was included in the 9.1 stable release[18]
- Linux: supported since kernel version 2.6.30,[19] released on June 9, 2009.[20]
- macOS: support added in 10.6.8 (Snow Leopard) update[21][unreliable source?] released on June 23, 2011. In fact, macOS Ventura does not support processors without the AVX2 instruction set. [22]
- OpenBSD: support added on March 21, 2015.[23]
- Solaris: supported in Solaris 10 Update 10 and Solaris 11
- Windows: supported in Windows 7 SP1, Windows Server 2008 R2 SP1,[24] Windows 8, Windows 10
- Windows Server 2008 R2 SP1 with Hyper-V requires a hotfix to support AMD AVX (Opteron 6200 and 4200 series) processors, KB2568088
Advanced Vector Extensions 2
Advanced Vector Extensions 2 (AVX2), also known as Haswell New Instructions,[25] is an expansion of the AVX instruction set introduced in Intel’s Haswell microarchitecture. AVX2 makes the following additions:
- expansion of most vector integer SSE and AVX instructions to 256 bits
- Gather support, enabling vector elements to be loaded from non-contiguous memory locations
- DWORD- and QWORD-granularity any-to-any permutes
- vector shifts.
Sometimes three-operand fused multiply-accumulate (FMA3) extension is considered part of AVX2, as it was introduced by Intel in the same processor microarchitecture. This is a separate extension using its own CPUID flag and is described on its own page and not below.
New instructions
| Instruction | Description |
|---|---|
VBROADCASTSS, VBROADCASTSD
|
Copy a 32-bit or 64-bit register operand to all elements of a XMM or YMM vector register. These are register versions of the same instructions in AVX1. There is no 128-bit version however, but the same effect can be simply achieved using VINSERTF128. |
VPBROADCASTB, VPBROADCASTW, VPBROADCASTD, VPBROADCASTQ
|
Copy an 8, 16, 32 or 64-bit integer register or memory operand to all elements of a XMM or YMM vector register. |
VBROADCASTI128
|
Copy a 128-bit memory operand to all elements of a YMM vector register. |
VINSERTI128
|
Replaces either the lower half or the upper half of a 256-bit YMM register with the value of a 128-bit source operand. The other half of the destination is unchanged. |
VEXTRACTI128
|
Extracts either the lower half or the upper half of a 256-bit YMM register and copies the value to a 128-bit destination operand. |
VGATHERDPD, VGATHERQPD, VGATHERDPS, VGATHERQPS
|
Gathers single or double precision floating point values using either 32 or 64-bit indices and scale. |
VPGATHERDD, VPGATHERDQ, VPGATHERQD, VPGATHERQQ
|
Gathers 32 or 64-bit integer values using either 32 or 64-bit indices and scale. |
VPMASKMOVD, VPMASKMOVQ
|
Conditionally reads any number of elements from a SIMD vector memory operand into a destination register, leaving the remaining vector elements unread and setting the corresponding elements in the destination register to zero. Alternatively, conditionally writes any number of elements from a SIMD vector register operand to a vector memory operand, leaving the remaining elements of the memory operand unchanged. |
VPERMPS, VPERMD
|
Shuffle the eight 32-bit vector elements of one 256-bit source operand into a 256-bit destination operand, with a register or memory operand as selector. |
VPERMPD, VPERMQ
|
Shuffle the four 64-bit vector elements of one 256-bit source operand into a 256-bit destination operand, with a register or memory operand as selector. |
VPERM2I128
|
Shuffle (two of) the four 128-bit vector elements of two 256-bit source operands into a 256-bit destination operand, with an immediate constant as selector. |
VPBLENDD
|
Doubleword immediate version of the PBLEND instructions from SSE4. |
VPSLLVD, VPSLLVQ
|
Shift left logical. Allows variable shifts where each element is shifted according to the packed input. |
VPSRLVD, VPSRLVQ
|
Shift right logical. Allows variable shifts where each element is shifted according to the packed input. |
VPSRAVD
|
Shift right arithmetically. Allows variable shifts where each element is shifted according to the packed input. |
CPUs with AVX2
- Intel
- Haswell processors (only Core and Xeon branded), Q2 2013
- Haswell E processors, Q3 2014
- Broadwell processors, Q4 2014
- Broadwell E processors, Q3 2016
- Skylake processors, Q3 2015
- Kaby Lake processors, Q3 2016 (ULV mobile)/Q1 2017 (desktop/mobile)
- Skylake-X processors, Q2 2017
- Coffee Lake processors, Q4 2017
- Cannon Lake processors, Q2 2018
- Cascade Lake processors, Q2 2019
- Ice Lake processors, Q3 2019
- Comet Lake processors, Q3 2019
- Tiger Lake (Core, Pentium and Celeron branded[11]) processors, Q3 2020
- Rocket Lake processors, Q1 2021
- Alder Lake (Xeon, Core, Pentium and Celeron branded[11]) processors, Q4 2021. Supported both in Golden Cove P-cores and Gracemont E-cores.
- Raptor Lake processors, Q4 2022
- Sapphire Rapids processors, Q1 2023
- Meteor Lake processors
- Arrow Lake processors
- Lunar Lake processors
- AMD
- Excavator processor and newer, Q2 2015
- Zen processors, Q1 2017
- Zen+ processors, Q2 2018
- Zen 2 processors, Q3 2019
- Zen 3 processors, Q4 2020
- Zen 4 processors, Q4 2022
- VIA:
- Nano QuadCore
- Eden X4
AVX-512
AVX-512 are 512-bit extensions to the 256-bit Advanced Vector Extensions SIMD instructions for x86 instruction set architecture proposed by Intel in July 2013, and are supported with Intel’s Knights Landing processor.[3]
AVX-512 instructions are encoded with the new EVEX prefix. It allows 4 operands, 8 new 64-bit opmask registers, scalar memory mode with automatic broadcast, explicit rounding control, and compressed displacement memory addressing mode. The width of the register file is increased to 512 bits and total register count increased to 32 (registers ZMM0-ZMM31) in x86-64 mode.
AVX-512 consists of multiple instruction subsets, not all of which are meant to be supported by all processors implementing them. The instruction set consists of the following:
- AVX-512 Foundation (F) – adds several new instructions and expands most 32-bit and 64-bit floating point SSE-SSE4.1 and AVX/AVX2 instructions with EVEX coding scheme to support the 512-bit registers, operation masks, parameter broadcasting, and embedded rounding and exception control
- AVX-512 Conflict Detection Instructions (CD) – efficient conflict detection to allow more loops to be vectorized, supported by Knights Landing[3]
- AVX-512 Exponential and Reciprocal Instructions (ER) – exponential and reciprocal operations designed to help implement transcendental operations, supported by Knights Landing[3]
- AVX-512 Prefetch Instructions (PF) – new prefetch capabilities, supported by Knights Landing[3]
- AVX-512 Vector Length Extensions (VL) – extends most AVX-512 operations to also operate on XMM (128-bit) and YMM (256-bit) registers (including XMM16-XMM31 and YMM16-YMM31 in x86-64 mode)[26]
- AVX-512 Byte and Word Instructions (BW) – extends AVX-512 to cover 8-bit and 16-bit integer operations[26]
- AVX-512 Doubleword and Quadword Instructions (DQ) – enhanced 32-bit and 64-bit integer operations[26]
- AVX-512 Integer Fused Multiply Add (IFMA) – fused multiply add for 512-bit integers.[27]:746
- AVX-512 Vector Byte Manipulation Instructions (VBMI) adds vector byte permutation instructions which are not present in AVX-512BW.
- AVX-512 Vector Neural Network Instructions Word variable precision (4VNNIW) – vector instructions for deep learning.
- AVX-512 Fused Multiply Accumulation Packed Single precision (4FMAPS) – vector instructions for deep learning.
- VPOPCNTDQ – count of bits set to 1.[28]
- VPCLMULQDQ – carry-less multiplication of quadwords.[28]
- AVX-512 Vector Neural Network Instructions (VNNI) – vector instructions for deep learning.[28]
- AVX-512 Galois Field New Instructions (GFNI) – vector instructions for calculating Galois field.[28]
- AVX-512 Vector AES instructions (VAES) – vector instructions for AES coding.[28]
- AVX-512 Vector Byte Manipulation Instructions 2 (VBMI2) – byte/word load, store and concatenation with shift.[28]
- AVX-512 Bit Algorithms (BITALG) – byte/word bit manipulation instructions expanding VPOPCNTDQ.[28]
- AVX-512 Bfloat16 Floating-Point Instructions (BF16) – vector instructions for AI acceleration.
- AVX-512 Half-Precision Floating-Point Instructions (FP16) – vector instructions for operating on floating-point and complex numbers with reduced precision.
Only the core extension AVX-512F (AVX-512 Foundation) is required by all implementations, though all current processors also support CD (conflict detection); computing coprocessors will additionally support ER, PF, 4VNNIW, 4FMAPS, and VPOPCNTDQ, while central processors will support VL, DQ, BW, IFMA, VBMI, VPOPCNTDQ, VPCLMULQDQ etc.
The updated SSE/AVX instructions in AVX-512F use the same mnemonics as AVX versions; they can operate on 512-bit ZMM registers, and will also support 128/256 bit XMM/YMM registers (with AVX-512VL) and byte, word, doubleword and quadword integer operands (with AVX-512BW/DQ and VBMI).[27]:23
CPUs with AVX-512
| AVX-512 Subset | F | CD | ER | PF | 4FMAPS | 4VNNIW | VPOPCNTDQ | VL | DQ | BW | IFMA | VBMI | VBMI2 | BITALG | VNNI | BF16 | VPCLMULQDQ | GFNI | VAES | VP2INTERSECT | FP16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Intel Knights Landing (2016) | Yes | Yes | No | ||||||||||||||||||
| Intel Knights Mill (2017) | Yes | No | |||||||||||||||||||
| Intel Skylake-SP, Skylake-X (2017) | No | No | Yes | No | |||||||||||||||||
| Intel Cannon Lake (2018) | Yes | No | |||||||||||||||||||
| Intel Cascade Lake-SP (2019) | No | Yes | No | ||||||||||||||||||
| Intel Cooper Lake (2020) | No | Yes | No | ||||||||||||||||||
| Intel Ice Lake (2019) | Yes | No | Yes | No | |||||||||||||||||
| Intel Tiger Lake (2020) | Yes | No | |||||||||||||||||||
| Intel Rocket Lake (2021) | No | ||||||||||||||||||||
| Intel Alder Lake (2021) | Not officially supported, but can be enabled on some motherboards with some BIOS versionsNote 1 | ||||||||||||||||||||
| AMD Zen 4 (2022) | Yes | Yes | No | ||||||||||||||||||
| Intel Sapphire Rapids (2023) | No | Yes |
[29]
^Note 1 : AVX-512 is disabled by default in Alder Lake processors. On some motherboards with some BIOS versions, AVX-512 can be enabled in the BIOS, but this requires disabling E-cores.[30] However, Intel has begun fusing AVX-512 off of new Alder Lake processors.[31]
Compilers supporting AVX-512
- GCC 4.9 and newer[32]
- Clang 3.9 and newer[33]
- ICC 15.0.1 and newer[34]
- Microsoft Visual Studio 2017 C++ Compiler[35]
AVX-VNNI, AVX-IFMA
AVX-VNNI is a VEX-coded variant of the AVX512-VNNI instruction set extension. Similarly, AVX-IFMA is a VEX-coded variant of AVX512-IFMA. These extensions provide the same sets of operations as their AVX-512 counterparts, but are limited to 256-bit vectors and do not support any additional features of EVEX encoding, such as broadcasting, opmask registers or accessing more than 16 vector registers. These extensions allow to support VNNI and IFMA operations even when full AVX-512 support is not implemented in the processor.
CPUs with AVX-VNNI
- Intel
- Alder Lake processors, Q4 2021
- Raptor Lake processors, Q4 2022
- Sapphire Rapids processors, Q1 2023
- Meteor Lake processors
- Emerald Rapids processors
- Arrow Lake processors
- Lunar Lake processors
CPUs with AVX-IFMA
- Intel
- Sierra Forest processors
- Grand Ridge processors
- Meteor Lake processors
Applications
- Suitable for floating point-intensive calculations in multimedia, scientific and financial applications (AVX2 adds support for integer operations).
- Increases parallelism and throughput in floating point SIMD calculations.
- Reduces register load due to the non-destructive instructions.
- Improves Linux RAID software performance (required AVX2, AVX is not sufficient)[36]
Software
- Blender uses AVX, AVX2 and AVX-512 in the Cycles render engine.[37]
- Bloombase uses AVX, AVX2 and AVX-512 in their Bloombase Cryptographic Module (BCM).
- Botan uses both AVX and AVX2 when available to accelerate some algorithms, like ChaCha.
- Crypto++ uses both AVX and AVX2 when available to accelerate some algorithms, like Salsa and ChaCha.
- OpenSSL uses AVX- and AVX2-optimized cryptographic functions since version 1.0.2.[38] Support for AVX-512 was added in version 3.0.0.[39] Some of this support is also present in various clones and forks, like LibreSSL.
- Prime95/MPrime, the software used for GIMPS, started using the AVX instructions since version 27.1, AVX2 since 28.6 and AVX-512 since 29.1.[40]
- dav1d AV1 decoder can use AVX2 and AVX-512 on supported CPUs.[41][42]
- SVT-AV1 AV1 encoder can use AVX2 and AVX-512 to accelerate video encoding.[43]
- dnetc, the software used by distributed.net, has an AVX2 core available for its RC5 project and will soon release one for its OGR-28 project.
- Einstein@Home uses AVX in some of their distributed applications that search for gravitational waves.[44]
- Folding@home uses AVX on calculation cores implemented with GROMACS library.
- Helios uses AVX and AVX2 hardware acceleration on 64-bit x86 hardware.[45]
- Horizon: Zero Dawn uses AVX in its Decima game engine.
- RPCS3, an open source PlayStation 3 emulator, uses AVX2 and AVX-512 instructions to emulate PS3 games.
- Network Device Interface, an IP video/audio protocol developed by NewTek for live broadcast production, uses AVX and AVX2 for increased performance.
- TensorFlow since version 1.6 and tensorflow above versions requires CPU supporting at least AVX.[46]
- x264, x265 and VTM video encoders can use AVX2 or AVX-512 to speed up encoding.
- Various CPU-based cryptocurrency miners (like pooler’s cpuminer for Bitcoin and Litecoin) use AVX and AVX2 for various cryptography-related routines, including SHA-256 and scrypt.
- libsodium uses AVX in the implementation of scalar multiplication for Curve25519 and Ed25519 algorithms, AVX2 for BLAKE2b, Salsa20, ChaCha20, and AVX2 and AVX-512 in implementation of Argon2 algorithm.
- libvpx open source reference implementation of VP8/VP9 encoder/decoder, uses AVX2 or AVX-512 when available.
- FFTW can utilize AVX, AVX2 and AVX-512 when available.
- LLVMpipe, a software OpenGL renderer in Mesa using Gallium and LLVM infrastructure, uses AVX2 when available.
- glibc uses AVX2 (with FMA) and AVX-512 for optimized implementation of various mathematical (i.e.
expf,sinf,powf,atanf,atan2f) and string (memmove,memcpy, etc.) functions in libc. - Linux kernel can use AVX or AVX2, together with AES-NI as optimized implementation of AES-GCM cryptographic algorithm.
- Linux kernel uses AVX or AVX2 when available, in optimized implementation of multiple other cryptographic ciphers: Camellia, CAST5, CAST6, Serpent, Twofish, MORUS-1280, and other primitives: Poly1305, SHA-1, SHA-256, SHA-512, ChaCha20.
- POCL, a portable Computing Language, that provides implementation of OpenCL, makes use of AVX, AVX2 and AVX-512 when possible.
- .NET and .NET Framework can utilize AVX, AVX2 through the generic
System.Numerics.Vectorsnamespace. - .NET Core, starting from version 2.1 and more extensively after version 3.0 can directly use all AVX, AVX2 intrinsics through the
System.Runtime.Intrinsics.X86namespace. - EmEditor 19.0 and above uses AVX2 to speed up processing.[47]
- Native Instruments’ Massive X softsynth requires AVX.[48]
- Microsoft Teams uses AVX2 instructions to create a blurred or custom background behind video chat participants,[49] and for background noise suppression.[50]
- Pale Moon custom Windows builds greatly increase browsing speed due to the use of AVX2.
- , a JSON parsing library, uses AVX2 and AVX-512 to achieve improved decoding speed.[51][52]
- Tesseract OCR engine uses AVX, AVX2 and AVX-512 to accelerate character recognition.[53]
Downclocking
Since AVX instructions are wider and generate more heat, some Intel processors have provisions to reduce the Turbo Boost frequency limit when such instructions are being executed. On Skylake and its derivatives, the throttling is divided into three levels:[54][55]
- L0 (100%): The normal turbo boost limit.
- L1 (~85%): The «AVX boost» limit. Soft-triggered by 256-bit «heavy» (floating-point unit: FP math and integer multiplication) instructions. Hard-triggered by «light» (all other) 512-bit instructions.
- L2 (~60%): The «AVX-512 boost» limit. Soft-triggered by 512-bit heavy instructions.
The frequency transition can be soft or hard. Hard transition means the frequency is reduced as soon as such an instruction is spotted; soft transition means that the frequency is reduced only after reaching a threshold number of matching instructions. The limit is per-thread.[54]
In Ice Lake, only two levels persist:[56]
- L0 (100%): The normal turbo boost limit.
- L1 (~97%): Triggered by any 512-bit instructions, but only when single-core boost is active; not triggered when multiple cores are loaded.
Rocket Lake processors do not trigger frequency reduction upon executing any kind of vector instructions regardless of the vector size.[56] However, downclocking can still happen due to other reasons, such as reaching thermal and power limits.
Downclocking means that using AVX in a mixed workload with an Intel processor can incur a frequency penalty despite it being faster in a «pure» context. Avoiding the use of wide and heavy instructions help minimize the impact in these cases. AVX-512VL allows for using 256-bit or 128-bit operands in AVX-512, making it a sensible default for mixed loads.[57]
On supported and unlocked variants of processors that down-clock, the ratios are adjustable and may be turned off (set to 0x) entirely via Intel’s Overclocking / Tuning utility or in BIOS if supported there.[58]
See also
- Memory Protection Extensions
- Scalable Vector Extension for ARM — a new vector instruction set (supplementing VFP and NEON) similar to AVX-512, with some additional features.
References
- ↑ Kanter, David (September 25, 2010). «Intel’s Sandy Bridge Microarchitecture» (in en-US). http://www.realworldtech.com/sandy-bridge/6/.
- ↑ Hruska, Joel (October 24, 2011). «Analyzing Bulldozer: Why AMD’s chip is so disappointing — Page 4 of 5 — ExtremeTech» (in en-US). ExtremeTech. https://www.extremetech.com/computing/100583-analyzing-bulldozers-scaling-single-thread-performance/4.
- ↑ 3.0 3.1 3.2 3.3 3.4 James Reinders (July 23, 2013), AVX-512 Instructions, Intel, http://software.intel.com/en-us/blogs/2013/avx-512-instructions, retrieved August 20, 2013
- ↑ «Intel Xeon Phi Processor 7210 (16GB, 1.30 GHz, 64 core) Product Specifications». Intel ARK (Product Specs). http://ark.intel.com/products/94033/Intel-Xeon-Phi-Processor-7210-16GB-1_30-GHz-64-core.
- ↑ «14.9». Intel 64 and IA-32 Architectures Software Developer’s Manual Volume 1: Basic Architecture (-051US ed.). Intel Corporation. p. 349. http://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-software-developer-vol-1-manual.pdf. Retrieved August 23, 2014. «Memory arguments for most instructions with VEX prefix operate normally without causing #GP(0) on any byte-granularity alignment (unlike Legacy SSE instructions).»
- ↑ «i386 and x86-64 Options — Using the GNU Compiler Collection (GCC)». https://gcc.gnu.org/onlinedocs/gcc-4.8.2/gcc/i386-and-x86-64-Options.html#i386-and-x86-64-Options.
- ↑ «The microarchitecture of Intel, AMD and VIA CPUs: An optimization guide for assembly programmers and compiler makers». http://www.agner.org/optimize/microarchitecture.pdf.
- ↑ «Chess programming AVX2». https://chessprogramming.wikispaces.com/AVX2.
- ↑ «Intel Offers Peek at Nehalem and Larrabee». ExtremeTech. March 17, 2008. http://www.extremetech.com/computing/80772-intel-offers-peek-at-nehalem-and-larrabee.
- ↑ «Intel Core i7-3960X Processor Extreme Edition». http://ark.intel.com/products/63696/Intel-Core-i7-3960X-Processor-Extreme-Edition-%2815M-Cache-3_30-GHz%29.
- ↑ 11.0 11.1 11.2 «Intel® Celeron® 6305 Processor (4M Cache, 1.80 GHz, with IPU) Product Specifications» (in en). https://ark.intel.com/content/www/us/en/ark/products/208646/intel-celeron-6305-processor-4m-cache-1-80-ghz-with-ipu.html.
- ↑ «Does a Processor with AVX2 or AVX-512 Support AVX Instructions?» (in en). https://www.intel.com/content/www/us/en/support/articles/000058796/processors.html.
- ↑ Dave Christie (May 7, 2009), Striking a balance, AMD Developer blogs, http://developer.amd.com/2009/05/06/striking-a-balance/, retrieved January 17, 2012
- ↑ New «Bulldozer» and «Piledriver» Instructions, AMD, October 2012, http://developer.amd.com/wordpress/media/2012/10/New-Bulldozer-and-Piledriver-Instructions.pdf
- ↑ «What’s New — RAD Studio». https://docwiki.embarcadero.com/RADStudio/Alexandria/en/What%27s_New#Inline_assembler_support_for_AVX_instructions_.28AVX-512.29.
- ↑ «YASM 0.7.0 Release Notes». http://yasm.tortall.net/releases/Release0.7.0.html.
- ↑ Add support for the extended FPU states on amd64, both for native 64bit and 32bit ABIs, svnweb.freebsd.org, January 21, 2012, http://svnweb.freebsd.org/base?view=revision&revision=230426, retrieved January 22, 2012
- ↑ «FreeBSD 9.1-RELEASE Announcement». http://www.freebsd.org/releases/9.1R/announce.html.
- ↑ x86: add linux kernel support for YMM state, https://git.kernel.org/linus/a30469e7921a6dd2067e9e836d7787cfa0105627, retrieved July 13, 2009
- ↑ Linux 2.6.30 — Linux Kernel Newbies, http://kernelnewbies.org/Linux_2_6_30, retrieved July 13, 2009
- ↑ Twitter, https://twitter.com/comex/status/85401002349576192, retrieved June 23, 2010
- ↑ «Devs are making progress getting macOS Ventura to run on unsupported, decade-old Macs». August 23, 2022. https://arstechnica.com/gadgets/2022/08/running-macos-ventura-on-old-macs-isnt-easy-but-some-devs-are-making-progress/.
- ↑ Add support for saving/restoring FPU state using the XSAVE/XRSTOR., http://marc.info/?l=openbsd-cvs&m=142697057503802&w=2, retrieved March 25, 2015
- ↑ Floating-Point Support for 64-Bit Drivers, http://msdn.microsoft.com/en-us/library/ff545910.aspx, retrieved December 6, 2009
- ↑ Haswell New Instruction Descriptions Now Available, Software.intel.com, http://software.intel.com/en-us/blogs/2011/06/13/haswell-new-instruction-descriptions-now-available/, retrieved January 17, 2012
- ↑ 26.0 26.1 26.2 James Reinders (July 17, 2014). «Additional AVX-512 instructions». Intel. https://software.intel.com/en-us/blogs/additional-avx-512-instructions.
- ↑ 27.0 27.1 «Intel Architecture Instruction Set Extensions Programming Reference» (PDF). Intel. https://software.intel.com/en-us/intel-architecture-instruction-set-extensions-programming-reference.
- ↑ 28.0 28.1 28.2 28.3 28.4 28.5 28.6 «Intel® Architecture Instruction Set Extensions and Future Features Programming Reference». Intel. https://software.intel.com/en-us/intel-architecture-instruction-set-extensions-programming-reference.
- ↑ «Intel® Software Development Emulator | Intel® Software». https://software.intel.com/en-us/articles/intel-software-development-emulator.
- ↑ Cutress, Ian; Frumusanu, Andrei. «The Intel 12th Gen Core i9-12900K Review: Hybrid Performance Brings Hybrid Complexity» (in en). https://www.anandtech.com/show/17047/the-intel-12th-gen-core-i912900k-review-hybrid-performance-brings-hybrid-complexity/2.
- ↑ Alcorn, Paul (2022-03-02). «Intel Nukes Alder Lake’s AVX-512 Support, Now Fuses It Off in Silicon» (in en). https://www.tomshardware.com/news/intel-nukes-alder-lake-avx-512-now-fuses-it-off-in-silicon.
- ↑ «GCC 4.9 Release Series — Changes, New Features, and Fixes – GNU Project — Free Software Foundation (FSF)» (in en). https://gcc.gnu.org/gcc-4.9/changes.html#x86.
- ↑ «LLVM 3.9 Release Notes — LLVM 3.9 documentation». http://releases.llvm.org/3.9.0/docs/ReleaseNotes.html#id10.
- ↑ «Intel® Parallel Studio XE 2015 Composer Edition C++ Release Notes | Intel® Software» (in en). https://software.intel.com/en-us/articles/intel-parallel-studio-xe-2015-composer-edition-c-release-notes.
- ↑ «Microsoft Visual Studio 2017 Supports Intel® AVX-512» (in en). July 11, 2017. https://blogs.msdn.microsoft.com/vcblog/2017/07/11/microsoft-visual-studio-2017-supports-intel-avx-512/.
- ↑ «Linux RAID». LWN. February 17, 2013. https://git.kernel.org/?p=linux/kernel/git/torvalds/linux-2.6.git;a=commitdiff;h=2c935842bdb46f5f557426feb4d2bdfdad1aa5f9.
- ↑ Jaroš, Milan; Strakoš, Petr; Říha, Lubomír (28 May 2022). «Rendering in Blender using AVX-512 Vectorization» (in en). Technical University of Ostrava. https://www.ixpug.org/documents/1520629330Jaros-IXPUG-CINECABlender5.pdf.
- ↑ «Improving OpenSSL Performance». May 26, 2015. https://software.intel.com/en-us/articles/improving-openssl-performance.
- ↑ «OpenSSL 3.0.0 release notes». September 7, 2021. https://github.com/openssl/openssl/blob/openssl-3.0.0/CHANGES.md.
- ↑ «Prime95 release notes». https://www.mersenne.org/download/whatsnew_308b15.txt.
- ↑ «dav1d: performance and completion of the first release». November 21, 2018. http://www.jbkempf.com/blog/post/2018/dav1d-toward-the-first-release.
- ↑ «dav1d 0.6.0 release notes». March 6, 2020. https://code.videolan.org/videolan/dav1d/-/tags/0.6.0.
- ↑ «SVT-AV1 0.7.0 release notes». September 26, 2019. https://gitlab.com/AOMediaCodec/SVT-AV1/-/blob/078d27e0bdc52cad2dc28e630fdd6391857e044e/CHANGELOG.md#070-2019-09-26.
- ↑ «Einstein@Home Applications». http://einsteinathome.org/apps.php.
- ↑ «FAQ, Helios» (in en-US). https://heliosmusic.io/faq/.
- ↑ «Tensorflow 1.6». https://github.com/tensorflow/tensorflow/releases/tag/v1.6.0.
- ↑ New in Version 19.0 – EmEditor (Text Editor)
- ↑ «MASSIVE X Requires AVX Compatible Processor» (in en-US). http://support.native-instruments.com/hc/en-us/articles/360001544678-MASSIVE-X-Requires-AVX-Compatible-Processor.
- ↑ «Hardware requirements for Microsoft Teams» (in en-US). https://docs.microsoft.com/en-us/microsoftteams/hardware-requirements-for-the-teams-app.
- ↑ «Reduce background noise in Teams meetings». https://support.microsoft.com/en-gb/office/reduce-background-noise-in-teams-meetings-1a9c6819-137d-4b3b-a1c8-4ab20b234c0d.
- ↑ Langdale, Geoff; Lemire, Daniel (2019). «Parsing Gigabytes of JSON per Second». The VLDB Journal 28 (6): 941–960. doi:10.1007/s00778-019-00578-5.
- ↑ «simdjson 2.1.0 release notes». June 30, 2022. https://github.com/simdjson/simdjson/releases/tag/v2.1.0.
- ↑ Larabel, Michael (July 7, 2022). «Tesseract OCR 5.2 Engine Finds Success With AVX-512F». https://www.phoronix.com/scan.php?page=news_item&px=Tesseract-OCR-5.2-Released.
- ↑ 54.0 54.1 Lemire, Daniel (September 7, 2018). «AVX-512: when and how to use these new instructions». https://lemire.me/blog/2018/09/07/avx-512-when-and-how-to-use-these-new-instructions/.
- ↑ «SIMD instructions lowering CPU frequency». https://stackoverflow.com/a/56861355.
- ↑ 56.0 56.1 Downs, Travis (August 19, 2020). «Ice Lake AVX-512 Downclocking». https://travisdowns.github.io/blog/2020/08/19/icl-avx512-freq.html.
- ↑ «x86 — AVX 512 vs AVX2 performance for simple array processing loops». https://stackoverflow.com/a/52543573.
- ↑ «Intel® Extreme Tuning Utility (Intel® XTU) Guide to Overclocking : Advanced Tuning» (in en). https://www.intel.com/content/www/us/en/gaming/resources/overclocking-xtu-guide.html#articleparagraph-14. «See image in linked section, where AVX2 ratio has been set to 0.»
External links
- Intel Intrinsics Guide
- x86 Assembly Language Reference Manual