22.07.2017
Теория венчурного капитала и ее развитие. Чем отличаются риск и неопределенность? Кодирование информации — Харьков: Это кодирование является префиксным, что позволяет легко его декодировать результативный поток, т.
- Способы устранения информационной асимметрии. Прочитаем несколько символов в строку s и найдем в словаре строку t — самый длинный префикс s.
- Алгоритм Хаффмана В основе алгоритма Хаффмана лежит идея кодирования битовыми группами. Обратимые методы сжатия можно применять к любым типам данных, но они дают меньшую степень сжатия по сравнению с необратимыми методами сжатия.
- Особенности применения контрактного производства как способа повышения уровня конкурентоспособности современной фирмы. При преподавании данной дисциплины используются как классические методы обучения — лекции, контрольно-обучающие семинары , так и различные формы семинаров продвинутого уровня:
- Учет эффекта временного горизонта в предпринимательской практике.
Закономерности спроса на дифференцированные товары, их последствия для практики ценообразования. Величина сжатия определяется избыточностью обрабатываемого массива бит. Ничего сложного — запускаем архиватор, к примеру, WinZip, и получаем в результате, допустим, файл размером килобайт.
Методы сжатия информации: рутины и инструкции. Рутины и инструкции как методы сжатия. Все методы сжатия Сжатие без потери информации. Эти методы сжатия как и для.
ИНСТРУКЦИЯ ГЕНЕРАЛЬНОЙ УБОРКИ РЕНТГЕНКАБИНЕТА
Формирование конкурентных преимуществ в отечественной фармацевтической отрасли. Приведите примеры успешной деятельности российских предпринимателей. Кодирование Хаффмена для этого алфавита задается следующей таблицей: Кружочки на рисунке, обозначающие группы символов, называются вершинами или узлами nodes , а сама конструкция из этих узлов — двоичным деревом B-tree. Именно этот печальный факт не позволяет применять его в полиграфии, где качество ставится во главу угла. Последовательно объединяем два символа с наименьшими вероятностями появления в новый составной символ, вероятность появления которого полагаем равной сумме вероятностей составляющих его символов. В настоящий момент на рынке программных продуктов и серверах программного обеспечения можно встретить достаточно большое число архивирующих и сжимающих утилит, большинство из которых доступны для некоммерческого использования. Экспериментальным путем установлено, что программа LHArc использует 4-килобайтный буфер, LHA и PkZip — 8-ми, а ARJ — килобайтный.
Лекция №4. Сжатие информации
Принципы сжатия информации
Цель сжатия данных — обеспечить компактное представление данных, вырабатываемых источником, для их более экономного сохранения и передачи по каналам связи.
Пусть у нас имеется файл размером 1 (один) мегабайт. Нам необходимо получить из него файл меньшего размера. Ничего сложного — запускаем архиватор, к примеру, WinZip, и получаем в результате, допустим, файл размером 600 килобайт. Куда же делись остальные 424 килобайта?
Сжатие информации является одним из способов ее кодирования. Вообще коды делятся на три большие группы — коды сжатия (эффективные коды), помехоустойчивые коды и криптографические коды. Коды, предназначенные для сжатия информации, делятся, в свою очередь, на коды без потерь и коды с потерями. Кодирование без потерь подразумевает абсолютно точное восстановление данных после декодирования и может применяться для сжатия любой информации. Кодирование с потерями имеет обычно гораздо более высокую степень сжатия, чем кодирование без потерь, но допускает некоторые отклонения декодированных данных от исходных.
Виды сжатия
Все методы сжатия информации можно условно разделить на два больших непересекающихся класса: сжатие с потерей информации и сжатие без потери информации.
Сжатие без потери информации.
Эти методы сжатия нас интересуют в первую очередь, поскольку именно их применяют при передаче текстовых документов и программ, при выдаче выполненной работы заказчику или при создании резервных копий информации, хранящейся на копьютере.
Методы сжатия этого класса не могут допустить утрату информации, поэтому они основаны только на устранении ее избыточности, а информация имеет избыточность почти всегда (правда, если до этого кто-то ее уже не уплотнил). Если бы избыточности не было, нечего было бы и сжимать.
Вот простой пример. В русском языке 33 буквы, десять цифр и еще примерно полтора десятка знаков препинания и прочих специальных символов. Для текста, который записан только прописными русскими буквами (как в телеграммах и радиограммах) вполне хватило бы шестидесяти разных значений. Тем не менее, каждый символ обычно кодируется байтом, который содержит 8 битов и может выражать 256 различных кодов. Это первое основание для избыточности. Для нашего «телеграфного» текста вполне хватило бы шести битов на символ.
Вот другой пример. В международной кодировке символов ASCII для кодирования любого символа отводится одинаковое количество битов (8), в то время как всем давно и хорошо известно, что наиболее часто встречающиеся символы имеет смысл кодировать меньшим количеством знаков. Так, например, в «азбуке Морзе» буквы «Е» и «Т», которые встречаются часто, кодируются одним знаком (соответственно это точка и тире). А такие редкие буквы, как «Ю» (• • — -) и «Ц» (- • — •), кодируются четырьмя знаками. Неэффективная кодировка — второе основание для избыточности. Программы, выполняющие сжатие информации, могут вводить свою кодировку (разную для разных файлов) и приписывать к сжатому файлу некую таблицу (словарь), из которой распаковывающая программа узнает, как в данном файле закодированы те или иные символы или их группы. Алгоритмы, основанные на перекодировании информации, называют алгоритмами Хафмана.
Наличие повторяющихся фрагментов — третье основание для избыточности. В текстах это встречается редко, но в таблицах и в графике повторение кодов — обычное явление. Так, например, если число 0 повторяется двадцать раз подряд, то нет смысла ставить двадцать нулевых байтов. Вместо них ставят один ноль и коэффициент 20. Такие алгоритмы, основанные на выявлении повторов, называют методами RLE (Run Length Encoding).
Большими повторяющимися последовательностями одинаковых байтов особенно отличаются графические иллюстрации, но не фотографические (там много шумов и соседние точки существенно различаются по параметрам), а такие, которые художники рисуют «гладким» цветом, как в мультипликационных фильмах.
Сжатие с потерей информации.
Сжатие с потерей информации означает, что после распаковки уплотненного архива мы получим документ, который несколько отличается от того, который был в самом начале. Понятно, что чем больше степень сжатия, тем больше величина потери и наоборот.
Разумеется, такие алгоритмы неприменимы для текстовых документов, таблиц баз данных и особенно для программ. Незначительные искажения в простом неформатированном тексте еще как-то можно пережить, но искажение хотя бы одного бита в программе сделает ее абсолютно неработоспособной.
В то же время, существуют материалы, в которых стоит пожертвовать несколькими процентами информации, чтобы получить сжатие в десятки раз. К ним относятся фотографические иллюстрации, видеоматериалы и музыкальные композиции. Потеря информации при сжатии и последующей распаковке в таких материалах воспринимается как появление некоторого дополнительного «шума». Но поскольку при создании этих материалов определенный «шум» все равно присутствует, его небольшое увеличение не всегда выглядит критичным, а выигрыш в размерах файлов дает огромный (в 10-15 раз на музыке, в 20-30 раз на фото- и видеоматериалах).
К алгоритмам сжатия с потерей информации относятся такие известные алгоритмы как JPEG и MPEG. Алгоритм JPEG используется при сжатии фотоизображений. Графические файлы, сжатые этим методом, имеют расширение JPG. Алгоритмы MPEG используют при сжатии видео и музыки. Эти файлы могут иметь различные расширения, в зависимости от конкретной программы, но наиболее известными являются .MPG для видео и .МРЗ для музыки.
Алгоритмы сжатия с потерей информации применяют только для потребительских задач. Это значит, например, что если фотография передается для просмотра, а музыка для воспроизведения, то подобные алгоритмы применять можно. Если же они передаются для дальнейшей обработки, например для редактирования, то никакая потеря информации в исходном материале недопустима.
Величиной допустимой потери при сжатии обычно можно управлять. Это позволяет экспериментовать и добиваться оптимального соотношения размер/качество. На фотографических иллюстрациях, предназначенных для воспроизведения на экране, потеря 5% информации обычно некритична, а в некоторых случаях можно допустить и 20-25%.
Алгоритмы сжатия без потери информации
Код Шеннона-Фэно
Для дальнейших рассуждений будет удобно представить наш исходный файл с текстом как источник символов, которые по одному появляются на его выходе. Мы не знаем заранее, какой символ будет следующим, но мы знаем, что с вероятностью p1 появится буква «а», с вероятностью p2 -буква «б» и т.д.
В простейшем случае мы будем считать все символы текста независимыми друг от друга, т.е. вероятность появления очередного символа не зависит от значения предыдущего символа. Конечно, для осмысленного текста это не так, но сейчас мы рассматриваем очень упрощенную ситуацию. В этом случае справедливо утверждение «символ несет в себе тем больше информации, чем меньше вероятность его появления».
Давайте представим себе текст, алфавит которого состоит всего из 16 букв: А, Б, В, Г, Д, Е, Ж, З, И, К, Л, М, Н, О, П, Р. Каждый из этих знаков можно закодировать с помощью всего 4 бит: от 0000 до 1111. Теперь представим себе, что вероятности появления этих символов распределены следующим образом:
|
А |
Б |
В |
Г |
Д |
Е |
Ж |
З |
И |
К |
Л |
М |
Н |
О |
П |
Р |
|
0,2 |
0,15 |
0,15 |
0,1 |
0,08 |
0,08 |
0,06 |
0,04 |
0,03 |
0,022 |
0,018 |
0,016 |
0,014 |
0,014 |
0,013 |
0,013 |
Сумма этих вероятностей составляет, естественно, единицу. Разобьем эти символы на две группы таким образом, чтобы суммарная вероятность символов каждой группы составляла ~0.5 (рис). В нашем примере это будут группы символов А-В и Г-Р. Кружочки на рисунке, обозначающие группы символов, называются вершинами или узлами (nodes), а сама конструкция из этих узлов — двоичным деревом (B-tree). Присвоим каждому узлу свой код, обозначив один узел цифрой 0, а другой — цифрой 1.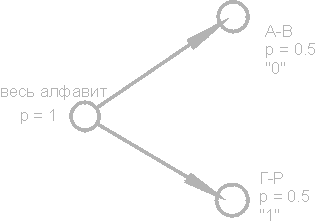
Снова разобьем первую группу (А-В) на две подгруппы таким образом, чтобы их суммарные вероятности были как можно ближе друг к другу. Добавим к коду первой подгруппы цифру 0, а к коду второй — цифру 1. 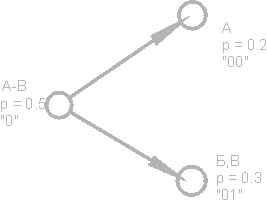
Будем повторять эту операцию до тех пор, пока на каждой вершине нашего «дерева» не останется по одному символу. Полное дерево для нашего алфавита будет иметь 31 узел.
Коды символов (крайние правые узлы дерева) имеют коды неодинаковой длины. Так, буква А, имеющая для нашего воображаемого текста вероятность p=0.2, кодируется всего двумя битами, а буква Р (на рисунке не показана), имеющая вероятность p=0.013, кодируется аж шестибитовой комбинацией.
Итак, принцип очевиден — часто встречающиеся символы кодируются меньшим числом бит, редко встречающиеся — большим. В результате среднестатистическое количество бит на символ будет равно
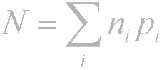
где ni — количество бит, кодирующих i-й символ, pi — вероятность появления i-го символа.
Код Хаффмана.
Алгоритм Хаффмана изящно реализует общую идею статистического кодирования с использованием префиксных множеств и работает следующим образом:
1. Выписываем в ряд все символы алфавита в порядке возрастания или убывания вероятности их появления в тексте.
2. Последовательно объединяем два символа с наименьшими вероятностями появления в новый составной символ, вероятность появления которого полагаем равной сумме вероятностей составляющих его символов. В конце концов построим дерево, каждый узел которого имеет суммарную вероятность всех узлов, находящихся ниже него.
3. Прослеживаем путь к каждому листу дерева, помечая направление к каждому узлу (например, направо — 1, налево — 0) . Полученная последовательность дает кодовое слово, соответствующее каждому символу (рис.).
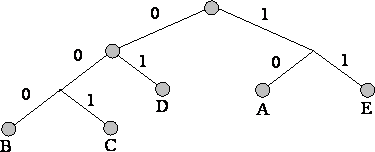
Построим кодовое дерево для сообщения со следующим алфавитом:
A B C D E
10 5 8 13 10
B C A E D
5 8 10 10 13
A E BC D
10 10 13 13
BC D AE
13 13 20
AE BCD
20 26
AEBCD
46
Недостатки методов
Самой большой сложностью с кодами, как следует из предыдущего обсуждения, является необходимость иметь таблицы вероятностей для каждого типа сжимаемых данных. Это не представляет проблемы, если известно, что сжимается английский или русский текст; мы просто предоставляем кодеру и декодеру подходящее для английского или русского текста кодовое дерево. В общем же случае, когда вероятность символов для входных данных неизвестна, статические коды Хаффмана работают неэффективно.
Решением этой проблемы является статистический анализ кодируемых данных, выполняемый в ходе первого прохода по данным, и составление на его основе кодового дерева. Собственно кодирование при этом выполняется вторым проходом.
Еще один недостаток кодов — это то, что минимальная длина кодового слова для них не может быть меньше единицы, тогда как энтропия сообщения вполне может составлять и 0,1, и 0,01 бит/букву. В этом случае код становится существенно избыточным. Проблема решается применением алгоритма к блокам символов, но тогда усложняется процедура кодирования/декодирования и значительно расширяется кодовое дерево, которое нужно в конечном итоге сохранять вместе с кодом.
Данные коды никак не учитывают взаимосвязей между символами, которые присутствуют практически в любом тексте. Например, если в тексте на английском языке нам встречается буква q, то мы с уверенностью сможем сказать, что после нее будет идти буква u.
RLE
Групповое кодирование — Run Length Encoding (RLE) — один из самых старых и самых простых алгоритмов архивации. Сжатие в RLE происходит за счет замены цепочек одинаковых байт на пары «счетчик, значение». («красный, красный, …, красный» записывается как «N красных»).
Одна из реализаций алгоритма такова: ищут наименнее часто встречающийся байт, называют его префиксом и делают замены цепочек одинаковых символов на тройки «префикс, счетчик, значение». Если же этот байт встретичается в исходном файле один или два раза подряд, то его заменяют на пару «префикс, 1» или «префикс, 2». Остается одна неиспользованная пара «префикс, 0», которую можно использовать как признак конца упакованных данных.
При кодировании exe-файлов можно искать и упаковывать последовательности вида AxAyAzAwAt…, которые часто встречаются в ресурсах (строки в кодировке Unicode)
К положительным сторонам алгоритма, можно отнести то, что он не требует дополнительной памяти при работе, и быстро выполняется. Алгоритм применяется в форматах РСХ, TIFF, ВМР. Интересная особенность группового кодирования в PCX заключается в том, что степень архивации для некоторых изображений может быть существенно повышена всего лишь за счет изменения порядка цветов в палитре изображения.
LZW
LZW-код (Lempel-Ziv & Welch) является на сегодняшний день одним из самых распространенных кодов сжатия без потерь. Именно с помощью LZW-кода осуществляется сжатие в таких графических форматах, как TIFF и GIF, с помощью модификаций LZW осуществляют свои функции очень многие универсальные архиваторы. Работа алгоритма основана на поиске во входном файле повторяющихся последовательностей символов, которые кодируются комбинациями длиной от 8 до 12 бит. Таким образом, наибольшую эффективность данный алгоритм имеет на текстовых файлах и на графических файлах, в которых имеются большие одноцветные участки или повторяющиеся последовательности пикселов.
Отсутствие потерь информации при LZW-кодировании обусловило широкое распространение основанного на нем формата TIFF. Этот формат не накладывает каких-либо ограничений на размер и глубину цвета изображения и широко распространен, например, в полиграфии. Другой основанный на LZW формат — GIF — более примитивен — он позволяет хранить изображения с глубиной цвета не более 8 бит/пиксел. В начале GIF — файла находится палитра — таблица, устанавливающая соответствие между индексом цвета — числом в диапазоне от 0 до 255 и истинным, 24-битным значением цвета.
Алгоритмы сжатия с потерей информации
JPEG
Алгоритм JPEG был разработан группой фирм под названием Joint Photographic Experts Group. Целью проекта являлось создание высокоэффективного стандарта сжатия как черно-белых, так и цветных изображений, эта цель и была достигнута разработчиками. В настоящее время JPEG находит широчайшее применение там, где требуется высокая степень сжатия — например, в Internet.
В отличие от LZW-алгоритма JPEG-кодирование является кодированием с потерями. Сам алгоритм кодирования базируется на очень сложной математике, но в общих чертах его можно описать так: изображение разбивается на квадраты 8*8 пикселов, а затем каждый квадрат преобразуется в последовательную цепочку из 64 пикселов. Далее каждая такая цепочка подвергается так называемому DCT-преобразованию, являющемуся одной из разновидностей дискретного преобразования Фурье. Оно заключается в том, что входную последовательность пикселов можно представить в виде суммы синусоидальных и косинусоидальных составляющих с кратными частотами (так называемых гармоник). В этом случае нам необходимо знать лишь амплитуды этих составляющих для того, чтобы восстановить входную последовательность с достаточной степенью точности. Чем большее количество гармонических составляющих нам известно, тем меньше будет расхождение между оригиналом и сжатым изображением. Большинство JPEG-кодеров позволяют регулировать степень сжатия. Достигается это очень простым путем: чем выше степень сжатия установлена, тем меньшим количеством гармоник будет представлен каждый 64-пиксельный блок.
Безусловно, сильной стороной данного вида кодирования является большой коэффициент сжатия при сохранении исходной цветовой глубины. Именно это свойство обусловило его широкое применение в Internet, где уменьшение размера файлов имеет первостепенное значение, в мультимедийных энциклопедиях, где требуется хранение возможно большего количества графики в ограниченном объеме.
Отрицательным свойством этого формата является неустранимое никакими средствами, внутренне ему присущее ухудшение качества изображения. Именно этот печальный факт не позволяет применять его в полиграфии, где качество ставится во главу угла.
Однако формат JPEG не является пределом совершенства в стремлении уменьшить размер конечного файла. В последнее время ведутся интенсивные исследования в области так называемого вейвлет-преобразования (или всплеск-преобразования). Основанные на сложнейших математических принципах вейвлет-кодеры позволяют получить большее сжатие, чем JPEG, при меньших потерях информации. Несмотря на сложность математики вейвлет-преобразования, в программной реализации оно проще, чем JPEG. Хотя алгоритмы вейвлет-сжатия пока находятся в начальной стадии развития, им уготовано большое будущее.
Фрактальное сжатие
Фрактальное сжатие изображений — это алгоритм сжатия изображений c потерями, основанный на применении систем итерируемых функций (IFS, как правило являющимися аффинными преобразованиями) к изображениям. Данный алгоритм известен тем, что в некоторых случаях позволяет получить очень высокие коэффициенты сжатия (лучшие примеры — до 1000 раз при приемлемом визуальном качестве) для реальных фотографий природных объектов, что недоступно для других алгоритмов сжатия изображений в принципе. Из-за сложной ситуации с патентованием широкого распространения алгоритм не получил.
Фрактальная архивация основана на том, что с помощью коэффициентов системы итерируемых функций изображение представляется в более компактной форме. Прежде чем рассматривать процесс архивации, разберем, как IFS строит изображение.
Строго говоря, IFS — это набор трехмерных аффинных преобразований, переводящих одно изображение в другое. Преобразованию подвергаются точки в трехмерном пространстве (x координата, у координата, яркость).
Основа метода фрактального кодирования — это обнаружение самоподобных участков в изображении. Впервые возможность применения теории систем итерируемых функций (IFS) к проблеме сжатия изображения была исследована Майклом Барнсли и Аланом Слоуном. Они запатентовали свою идею в 1990 и 1991 гг. Джеквин (Jacquin) представил метод фрактального кодирования, в котором используются системы доменных и ранговых блоков изображения (domain and range subimage blocks), блоков квадратной формы, покрывающих все изображение. Этот подход стал основой для большинства методов фрактального кодирования, применяемых сегодня. Он был усовершенствован Ювалом Фишером (Yuval Fisher) и рядом других исследователей.
В соответствии с данным методом изображение разбивается на множество неперекрывающихся ранговых подизображений (range subimages) и определяется множество перекрывающихся доменных подизображений (domain subimages). Для каждого рангового блока алгоритм кодирования находит наиболее подходящий доменный блок и аффинное преобразование, которое переводит этот доменный блок в данный ранговый блок. Структура изображения отображается в систему ранговых блоков, доменных блоков и преобразований.
Идея заключается в следующем: предположим, что исходное изображение является неподвижной точкой некоего сжимающего отображения. Тогда можно вместо самого изображения запомнить каким-либо образом это отображение, а для восстановления достаточно многократно применить это отображение к любому стартовому изображению.
По теореме Банаха, такие итерации всегда приводят к неподвижной точке, то есть к исходному изображению. На практике вся трудность заключается в отыскании по изображению наиболее подходящего сжимающего отображения и в компактном его хранении. Как правило, алгоритмы поиска отображения (то есть алгоритмы сжатия) в значительной степени переборные и требуют больших вычислительных затрат. В то же время, алгоритмы восстановления достаточно эффективны и быстры.
Вкратце метод, предложенный Барнсли, можно описать следующим образом. Изображение кодируется несколькими простыми преобразованиями (в нашем случае аффинными), то есть определяется коэффициентами этих преобразований (в нашем случае A, B, C, D, E, F).
Например, изображение кривой Коха можно закодировать четырмя аффинными преобразованиями, мы однозначно определим его с помощью всего 24-х коэффициентов.
Далее, поставив чёрную точку в любой точке картинки, мы будем применять наши преобразования в случайном порядке некоторое (достаточно большое) число раз (этот метод ещё называют фрактальный пинг-понг).
В результате точка обязательно перейдёт куда-то внутрь чёрной области на исходном изображении. Проделав такую операцию много раз, мы заполним все чёрное пространство, тем самым восстановив картинку.

Наиболее известны два изображения, полученных с помощью IFS: треугольник Серпинского и папоротник Барнсли. Первое задается тремя, а второе — пятью аффинными преобразованиями (или, в нашей терминологии, линзами). Каждое преобразование задается буквально считанными байтами, в то время как изображение, построенное с их помощью, может занимать и несколько мегабайт.
Становится понятно, как работает архиватор, и почему ему требуется так много времени. Фактически, фрактальная компрессия — это поиск самоподобных областей в изображении и определение для них параметров аффинных преобразований.
В худшем случае, если не будет применяться оптимизирующий алгоритм, потребуется перебор и сравнение всех возможных фрагментов изображения разного размера. Даже для небольших изображений при учете дискретности мы получим астрономическое число перебираемых вариантов. Даже резкое сужение классов преобразований, например, за счет масштабирования только в определенное число раз, не позволит добиться приемлемого времени. Кроме того, при этом теряется качество изображения. Подавляющее большинство исследований в области фрактальной компрессии сейчас направлены на уменьшение времени архивации, необходимого для получения качественного изображения.
Для фрактального алгоритма компрессии, как и для других алгоритмов сжатия с потерями, очень важны механизмы, с помощью которых можно будет регулировать степень сжатия и степень потерь. К настоящему времени разработан достаточно большой набор таких методов. Во-первых, можно ограничить количество преобразований, заведомо обеспечив степень сжатия не ниже фиксированной величины. Во-вторых, можно потребовать, чтобы в ситуации, когда разница между обрабатываемым фрагментом и наилучшим его приближением будет выше определенного порогового значения, этот фрагмент дробился обязательно (для него обязательно заводится несколько линз). В-третьих, можно запретить дробить фрагменты размером меньше, допустим, четырех точек. Изменяя пороговые значения и приоритет этих условий, можно очень гибко управлять коэффициентом компрессии изображения: от побитного соответствия, до любой степени сжатия.
Сравнение с JPEG
Сегодня наиболее распространенным алгоритмом архивации графики является JPEG. Сравним его с фрактальной компрессией.
Во-первых, заметим, что и тот, и другой алгоритм оперируют 8-битными (в градациях серого) и 24-битными полноцветными изображениями. Оба являются алгоритмами сжатия с потерями и обеспечивают близкие коэффициенты архивации. И у фрактального алгоритма, и у JPEG существует возможность увеличить степень сжатия за счет увеличения потерь. Кроме того, оба алгоритма очень хорошо распараллеливаются.
Различия начинаются, если мы рассмотрим время, необходимое алгоритмам для архивации/разархивации. Так, фрактальный алгоритм сжимает в сотни и даже в тысячи раз дольше, чем JPEG. Распаковка изображения, наоборот, произойдет в 5-10 раз быстрее. Поэтому, если изображение будет сжато только один раз, а передано по сети и распаковано множество раз, то выгодней использовать фрактальный алгоритм.
JPEG использует разложение изображения по косинусоидальным функциям, поэтому потери в нем (даже при заданных минимальных потерях) проявляются в волнах и ореолах на границе резких переходов цветов. Именно за этот эффект его не любят использовать при сжатии изображений, которые готовят для качественной печати: там этот эффект может стать очень заметен.
Фрактальный алгоритм избавлен от этого недостатка. Более того, при печати изображения каждый раз приходится выполнять операцию масштабирования, поскольку растр (или линиатура) печатающего устройства не совпадает с растром изображения. При преобразовании также может возникнуть несколько неприятных эффектов, с которыми можно бороться либо масштабируя изображение программно (для дешевых устройств печати типа обычных лазерных и струйных принтеров), либо снабжая устройство печати своим процессором, винчестером и набором программ обработки изображений (для дорогих фотонаборных автоматов). Как можно догадаться, при использовании фрактального алгоритма таких проблем практически не возникает.
Вытеснение JPEG фрактальным алгоритмом в повсеместном использовании произойдет еще не скоро (хотя бы в силу низкой скорости архивации последнего), однако в области приложений мультимедиа, в компьютерных играх его использование вполне оправдано.
Для уменьшения
размеров мультимедийных файлов используют
процедуру сжатия.
Под
сжатием
(компрессией,
упаковкой, уплотнением) понимается
такое преобразование информации, в
результате которого исходный файл
уменьшается в объеме, а количество
информации в сжатом файле уменьшается
на такую небольшую величину, которой
практически можно
пренебречь. По
смыслу термин «сжатие» близок к термину
«архивация». Однако последний термин
чаще всего предполагает сжатие информации
без ее искажения (без изменения, без
потерь).
Многие
приемы сжатия аудио- и видеоинформации
основываются на «обмане»
органов чувств (зрение и слух) человека
путем исключения избыточной информации,
которую человек (в силу своих физиологических
особенностей) не способен воспринять.
Разработано
несколько стандартов сжатия видео- и
аудиоинформации.
Наибольшее
влияние на настоящее и будущее
мультимедийных средств оказывает MPEG
(Moving
Picture
Experts
Group)
– объединенный комитет двух организаций:
Интернациональной организации по
стандартизации (ISO)
и Интернациональной электротехнической
комиссии (IEC).
Этот комитет разрабатывает стандарты
с одноименными названиями. Так стандарт
MPEG-1
был разработан с учетом возможностей
двухскоростных проигрывателей лазерных
дисков CD-ROM
и компьютеров с 486-м процессором.
В
январе 1992 г. комитет MPEG
опубликовал общие характеристики
будущего стандарта MPEG-1,
а в декабре 1993 г. они были приняты в
качестве стандарта. По требованиям
этого стандарта интенсивность
потока данных (скорость
передачи информации) сжатого видео и
звука должна укладываться в 1,5 Мбайт/с,
хотя были предусмотрены режимы вплоть
до 4 – 5 Мбайт/с.
Окончательное
утверждение MPEG-2
в. качестве международного стандарта
произошло в ноябре 1994 г. В его спецификациях
была определена допустимая интенсивность
потока данных от 2 до 10 Мбайт/с.
Стандарт
MPEG-2
позволяет записывать на лазерные диски
изготовленные по технологии DVD,
полноэкранные фильмы «вещательного»
качества. Для телевидения высокой
четкости разрабатывался стандарт
MPEG-3,
который впоследствии стал частью
стандарта MPEG-2
и отдельно теперь не упоминается
Разрабатываемый стандарт MPEG-4
предназначен для использования в
системах с низкой пропускной способностью.
Рассмотрим вначале
методы сжатия звуковой информации, а
затем – методы сжатия видеоинформации.
Согласно
теореме Котельникова,
чтобы
восстановить без искажений аналоговый
сигнал после его преобразования в
цифровой сигнал, необходимо, чтобы
частота выборки (дискретизации) была
хотя бы вдвое выше верхней граничной
частоты исходного сигнала. Для записи
звука на компакт-диски используется
частота выборки 44,1 кГц. Эта частота
более чем в 2 раза превышает верхнюю
граничную частоту, которую слышит
человек.
Второй фактор,
влияющий на качество воспроизводимого
звука, – количество двоичных разрядов
квантования. Во-первых, им определяется
передаваемый динамический диапазон
звука. Во-вторых, после цифроаналогового
преобразования уровень воспроизводимого
сигнала может принимать некоторое
множество фиксированных значений.
Исходный же аналоговый сигнал изменяется
непрерывно. В результате восстановленный
сигнал неизбежно отличается по форме
от исходного, и это отличие тем больше,
чем меньше разрядов использовалось для
квантования сигнала. Искажение формы
сигнала при воспроизведении эквивалентно
добавлению некоего шума – шума
квантования. Чтобы достичь полной
неразличимости шумов квантования, в
технике компакт-дисков используется
16-разрядное квантование, при этом уровень
воспроизводимого звука может принимать
одно из 65 536 значений.
Для записи
стереофонического звука с частотой
дискретизации 44,1 кГц и 16-битном
представлении звука (разрешение
составляет 65 536 уровней квантования)
требуется скорость передачи информации:
![]()
При такой скорости
передачи информации сохраняются
мельчайшие детали звуковой картины (в
том числе и исходные шумы). Этот способ
кодировки информации избыточен, так
как многие детали исходной звуковой
картины не воспринимается органом слуха
человека из-за биологических ограничений.
Как
известно, различают компрессию без
потерь и компрессию с потерями. Под
компрессией
без потерь подразумевается
возможность абсолютно точного
восстановления сжатых исходных данных.
Компрессия без потерь используется,
например, архиваторами ZIP,
RAR,
ARJ.
Применение подобных
алгоритмов для сжатия файлов, содержащих
оцифрованный звук в 16-битном формате,
не позволяет получить сжатие более чем
в 2 раза.
Программы компрессии
без потерь в процессе анализа данных
создают таблицы повторяющихся
последовательностей битов и заменяют
часто встречающиеся последовательности
более короткими записями (кодами).
Оцифрованный
(преобразованный с помощью АЦП) звуковой
сигнал обычно не повторяет сам себя и
по этой причине плохо сжимается с помощью
алгоритмов компрессии без потерь.
Адаптивная
разностная компрессия (Adaptive
Differential
Pulse
Code
Modulation,
ADPCM)
используется
в основном для сжатия речевых сигналов.
Для музыкальных произведений этот
алгоритм мало подходит из-за заметных
искажений.
Идея
компрессии ADPCM
заключается в том, что оцифрованный
речевой сигнал представляют не самими
отсчетами, а разностями
соседних
отсчетов, меньших по величине и,
следовательно, требующих меньшего числа
битов для своего представления.
Рассмотрим основные
идеи сжатия аудиоинформации, которые
базируются на использовании психофизических
ограничений (возможностей) человека.
Основные
приемы, положенные в основу сжатия
информации с помощью стандартов MPEG,
базируются на объективно существующих
психоакустических ограничениях органов
чувств человека. Человеческое ухо
способно воспринимать звуковые колебания,
лежащие лишь в диапазоне частот 20 –
20000 Гц, причем с возрастом этот диапазон
сужается. Методы сжатия звуковых данных,
основанные на использовании физиологических
особенностей человека, относятся к
классу компрессии
с потерями. Эти
методы не ставят цель абсолютно точного
восстановления формы исходных колебаний.
Их главная задача – достижение
максимального сжатия звукового сигнала
при минимальных слышимых искажениях
восстановленного после сжатия сигнала.
Звуковой
файл можно сжать с помощью компандирования.
Название
этого метода происходит от английского
термина compander,
который образован от английских слов:
compressing
– expanding
coder
– decoder.
Этот метод основан на законе, открытом
психологами: если интенсивность
раздражителя меняется в геометрической
прогрессии, то интенсивность человеческого
восприятия меняется в арифметической
прогрессии.
Компандирование
заключается в компрессии (сжатии) по
амплитуде исходного звукового сигнала
и последующем его восстановлении с
помощью экспандера (расширителя).
Компрессия – это
сжатие динамического диапазона сигнала,
когда слабые звуки усиливаются сильнее,
а сильные – слабее. На слух это
воспринимается как уменьшение различия
между тихим и громким звучанием исходного
сигнала.
Установлено, что,
если повышать громкость звука в 2, 4, 8 и
т. д. раз, то человеческое ухо будет
воспринимать этот процесс как линейное
увеличение интенсивности звука. Изменение
уровня громкости с 1 единицы до 2 единиц
столь же заметно для человеческого уха,
как и изменение громкости от 50 до 100
единиц. В то же время изменение громкости
от 100 единиц до 101 единицы человеком
практически не ощущается.
Таким образом, ухо
человека логарифмирует громкость
слышимых звуков.
При компандировании
значение амплитуды звука заменяется
логарифмом этого значения. Полученные
числа округляются, и для их записи
требуется меньшее число разрядов.
При
16-битном кодировании звука максимальное
значение кода не превышает значение
216.
Логарифм этого числа по основанию 2
равен 16. Последнее число может быть
закодировано пятью двоичными разрядами
(1610
= 100002).
Таким образом, для представления
информации вместо 16 битов можно
использовать лишь 5 битов. Этим достигается
сжатие информации. Для воспроизведения
компрессированного сигнала его подвергают
обратному по сравнению с логарифмированием
преобразованию – потенцированию.
Еще один способ
сжатия звуковой информации заключается
в том, что исходный звуковой сигнал
очищается с помощью фильтров от неслышимых
компонентов (например, убирают низкие
басовые шумы). Затем производится более
сложный анализ сигнала: вычисляются и
удаляются замаскированные частоты,
заглушенные другими мощными сигналами.
Таким образом, можно исключить до 70%
информации из сигнала, практически не
изменив качество его звучания.
Сжатие сигнала
также можно получить за счет еще одного
приема.
Если исходный
сигнал является стереофоническим, то
его можно преобразовать в так называемый
совмещенный стереофонический сигнал.
Установлено, что слуховой аппарат
человека может определить местоположение
источника звука лишь на средних частотах,
а высокие и низкие частоты звучат как
бы отдельно от источника звука. Таким
образом, высокие и низкие частоты можно
представить в виде монофонического
сигнала (т. е. без разделения на два
стереофонических канала). Это позволяет
вдвое уменьшить объем информации,
передаваемой на низких и высоких
частотах.
Еще одна возможность
сжатия звукового сигнала связана с
наличием двух потоков информации для
левого и правого каналов. Например, если
в правом канале наблюдается какое-то
время полная тишина, то это пустующее
место используется для повышения
качества звучания левого канала или
туда помещают данные, которые не
уместились в компрессированный поток
в предыдущие моменты времени.
Одно из свойств
человеческого слуха заключается в
маскировании тихого звука, следующего
сразу за громким звуком. Так после
выстрела пушки в течение некоторого
времени трудно услышать тиканье наручных
механических часов или стрекот кузнечиков.
При
сжатии звукового сигнала замаскированный,
почти неслышимый звук не сохраняется
в памяти и не передается через каналы
связи. Например, громкий звук длительностью
0,1 с может замаскировать тихие последующие
звуки, запаздывающие на время до 0,5 с, а
значит, их не надо сохранять. Такая
процедура исключения сигнала, следующего
за громким звуком, называется маскированием
во временной области.
Для
человеческого уха характерно также и
явление маскирования
в частотной области, заключающееся
в том, что постоянно звучащий громкий
синусоидальный сигнал маскирует
(«глушит») тихие сигналы, которые близко
лежат на оси частот к громкому сигналу.
При техническом
использовании таких физиологических
особенностей человеческого слуха
уплотняемый сигнал переносят с помощью
быстрого преобразования Фурье из
временной области в частотную область.
Затем удаляют спектральные составляющие,
замаскированные громким сигналом, и
делают обратное преобразование Фурье.
Еще одна возможность
компрессии основывается на следующей
особенности человеческого слуха.
Экспериментально установлено, что в
диапазонах частот 20 – 200 Гц и 14 – 20 кГц
чувствительность человеческого слуха
существенно ниже, чем на частотах 0,2 –
14 кГц. По этой причине допустимо более
грубое квантование сигналов в указанных
диапазонах частот. На этих частотах для
представления непрерывных сигналов
двоичными числами требуется меньшее
число уровней, а значит и меньшее число
битов. Так в среднем диапазоне частот
амплитуды кодируются 16 битами, а на
частотах, где ухо менее чувствительно
– 6 и даже 4 битами.
Биоакустические
свойства человеческого слуха не позволяют
сжать звуковой сигнал, если он представляет
собой однотонные звуки с постоянным
уровнем громкости. В этом случае наряду
с рассмотренными приемами сжатия дают
эффект традиционные методы архивации
информации (например, алгоритм Хаффмана).
Познакомимся с
основными показателями, характеризующими
качество движущихся изображений.
Частота
кадра (Frame
Rate).
Стандартная скорость воспроизведения
видеосигнала 30 кадров/с (для кино этот
показатель составляет 24 кадра/с).
Экспериментально установлено, что
иллюзия движущегося изображения
возникает при частоте смены кадров
более 16-ти в секунду. В этом случае
человек воспринимает быстроменяющиеся
картинки в виде динамичного непрерывного
изображения.
Глубина
цвета
(Color
Resolution). Этот
показатель определяет количество
цветов, одновременно отображаемых на
экране. Компьютеры обрабатывают цвет
в RGB-формате
(красный – зеленый – синий). RGB-формат
позволяет путем смешения в разных
пропорциях трех основных цветов получить
любой другой цвет или оттенок. Для
цветовой модели RGB
обычно характерны следующие режимы
глубины цвета: 8 бит/пиксель (256 цветов),
16 бит/пиксель (65 535 цветов) и 24 бит/пиксель
(16,7 миллиона цветов).
Экранное
разрешение (Spatial
Resolution)
или, другими словами, количество точек,
из которых состоит изображение на
экране. Наиболее часто в настоящее время
используется разрешение 640 х 480 точек
(пикселей).
Качество
изображения (Image
Quality).
Это комплексный показатель, который
вбирает в себя три предыдущих. Требования
к качеству зависят от конкретной задачи.
Иногда достаточно, чтобы картинка была
размером в четверть экрана с палитрой
из 256 цветов (8 битов), при скорости
воспроизведения 15 кадров/с. В других
случаях требуется полноэкранное видео
(768576)
с палитрой в 16,7 миллиона цветов (24 битов)
и кадровой разверткой (30 кадров/с).
Расчеты показывают,
что 24-битное цветное видео, при разрешении
640480 пикселей и
частоте 30 кадров/с, требует передачи
более 26 Мбайтов данных в секунду. Этот
поток информации превышает пропускную
способность системной шины ЭВМ. Для
наглядности приводим здесь эти расчеты.
![]()
Для оптимизации
процесса кодирования информации
необходимо, с одной стороны, не передавать
избыточную информацию, а с другой
стороны, не допускать чрезмерной потери
качества изображения.
В
зависимости от скорости упаковки
изображений методы сжатия подразделяются
на две группы. К первой группе относится
метод сжатия неподвижных
изображений. Сжатие
может выполняться с любой скоростью,
так как этот процесс не регламентирован
временем (в силу статичности изображения).
Вторую группу образуют методы сжатия
движущихся
изображений. Сжатие
движущихся изображений должно выполняться,
как правило, в режиме реального времени
по мере ввода данных.
Стандарт
JPEG
(Joint
Photographic
Experts
Group),
предложенный Объединенной группой
экспертов в области фотографии, позволяет
сократить размеры графического файла
с неподвижным изображением в 10 – 20 раз.
Благодаря специальным процессорам этим
методом удается сжимать и движущиеся
изображения.
Устаревший
стандарт сжатия движущихся изображений
AVI
(Audio
Visual
Interleave)
позволяет формировать упрощенное
видеоизображение, но не на полном экране
и со скоростью лишь 15 кадров в секунду.
При этом используется всего 160
120 пикселей и 256 цветов.
Наибольшее
распространение для сжатия движущихся
изображений получил стандарт MPEG.
С
помощью стандарта MPEG
обрабатывается и каждый кадр по
отдельности, и анализируется динамика
изменения изображения. Этим удается
уменьшить избыточные данные, так как в
большинстве фрагментов фон изображения
остается достаточно стабильным, а
изменения происходят в основном на
переднем плане. MPEG
начинает сжатие с создания исходного
(ключевого) кадра, называемого Intra
(внутренний) кадр. I-кадры
играют роль опорных
при
восстановлении остального видеоизображения
и размещаются последовательно через
каждые 10 – 15 кадров. I-кадры
формируют с помощью методов, разработанных
стандартом JPEG
для сжатия неподвижных изображений.
Фрагменты
изображений, которые претерпевают
изменения, сохраняются при помощи
Predicted
(расчетных, предсказуемых) кадров.
Р-кадры, содержат различия текущего
изображения с предыдущим или последующим
I-кадром.
Р-кадры располагаются между опорными
1-кадрами.
Кроме
перечисленных кадров, используются
В-кадры, название которых происходит
от английских слов Bi-directional
Interpolated.
В переводе с английского языка этот
термин означает «кадры двунаправленной
интерполяции (предсказания)». В-кадры
содержат усредненную информацию
относительно двух ближайших (предыдущего
и последующего) I-кадров
или Р-кадров. Это позволяет предположительно
восстанавливать (реконструировать)
отсутствующие кадры.
В-кадры учитывают
тот факт, что человек не способен за
доли секунды рассмотреть детали
движущегося изображения, поэтому можно
формировать некоторое приблизительное,
усредненное (промежуточное) изображение,
учитывая информацию опорных кадров.
Здесь происходит умышленный обман
органов чувств человека, за счет которого
происходит уплотнение информации.
Очевидно,
что существенный выигрыш в сжатии
информации дают Р- и особенно В-кадры,
так как для формирования I-кадров
необходимо использовать всю имеющуюся
информацию об изображении.
При сжатии
изображений (как и при сжатии звуков)
используются физиологические особенности
человека.
Установлено,
что ошибки в изображении заметны глазом
(визуально), если они превышают некоторый
порог
заметности. Различают
пространственную и временную заметность
искажений изображений.
Порог заметности
пространственных изменений яркости
зависит от многих факторов: яркости
деталей изображения, яркости фона,
относительного положения деталей
различной яркости, условий внешнего
освещения.
Что касается
временного восприятия цвета, то известно,
что вариация цветности менее заметны,
чем вариация яркости. Наиболее заметны
изменения зеленого цвета, затем красного,
и наименее заметны изменения синего
цвета.
Используя эту
особенность зрения человека, можно при
упаковке (сжатии) изображения исключить
данные о цвете, скажем, каждой второй
точки изображения (сохранив только ее
яркость), а при распаковке брать вместо
исключенного цвета цвет соседней точки.
Аналогично для группы соседних точек
брать можно некоторый средний цвет.
За высокое качество
сжатия, как правило, приходится платить
большими затратами времени на упаковку
и распаковку. Алгоритмы, дающие хорошее
качество сжатия, могут оказаться
неприменимыми из-за слишком большого
времени, необходимого для распаковки
информации. Разработчики новых методов
упаковки всегда ищут компромисс между
качеством сжатия и скоростью распаковки.
Как
правило, информацию можно «не торопясь»
сжать, а при воспроизведении распаковать
с большой скоростью. Но бывают случаи,
когда информацию нужно упаковать «на
лету», т. е. в режиме реального
времени. Такая
ситуация возникает, например, при
передаче изображения с видеокамеры в
Интернет.
Степень
сжатия характеризует коэффициент
сжатия, который
численно равен отношению объема сжатого
файла к объему исходного файла.
Выбор коэффициентов
сжатия – это компромисс между скоростью
передачи файлов и качеством
восстанавливаемого изображения. Чем
выше коэффициент сжатия, тем ниже это
качество. При этом следует иметь в виду,
что при очень высокой разрешающей
способности и большой степени сжатия
можно получить изображение с низкой
разрешающей способностью. Что касается
требующегося качества изображения, то
оно зависит от конкретной поставленной
задачи. Например, в системах видеоконференций
основной объем необходимой информации
содержится в речи. Качество же изображения
играет второстепенную роль.
Качество сжатия
варьируется в довольно широких пределах;
обычными для современных видеосистем
являются коэффициенты сжатия от 1:4 до
1:100.
При
сжатии информации часто используется
термин «кодек», который образован путем
сокращения слов «кодер» и «декодер».
Этим термином обозначается алгоритм,
предназначенный для кодирования (сжатия)
и декодирования (распаковки) цифровых
сигналов, идущих от системы цифровой
аудио- и видеозаписи. Алгоритм может
быть реализован программно и загружен
в память компьютера либо может быть
реализован аппаратно с помощью специальной
микросхемы. Симметричные
кодеки
упаковывают и распаковывают сигнал в
реальном времени.
Некоторые
сложные алгоритмы кодирования, например
алгоритм сжатия видеосигнала MPEG,
не могут выполняться в реальном времени
(при записи), поэтому кодек MPEG
называется асимметричным.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Сжатие информации
Сжатие информации, компрессия, Шаблон:Англ. data compression — алгоритмическое преобразование данных (кодирование), при котором за счет уменьшения их избыточности уменьшается их обьём.
Содержание
- 1 Принципы сжатия информации
- 2 Характеристики алгоритмов сжатия и применимость
- 2.1 Коэффициент сжатия
- 2.2 Допустимость потерь
- 2.3 Системные требования алгоритмов
- 3 См. также
Принципы сжатия информации
В основе любого способа сжатия информации лежит модель источника информации, или, более конкретно, модель избыточности. Иными словами для сжатия информации используются некоторые сведения о том, какого рода информация сжимается — не обладая никакми сведениями об информации нельзя сделать ровным счётом никаких предположений, какое преобразование позволит уменьшить объём сообщения. Эта информация используется в процессе сжатия и разжатия. Модель избыточности может также строиться или параметризоваться на этапе сжатия. Методы, позволяющие на основе входных данных изменять модель избыточности информации, называются адаптивными. Неадаптивными являются обычно узкоспецифичные алгоритмы, применяемые для работы с хорошо определёнными и неизменными характеристиками. Подавляющая часть же достаточно универсальных алгоритмов являются в той или иной мере адаптивными.
Любой метод сжатия информации включает в себя два преобразования обратных друг другу:
- преобразование сжатия;
- преобразование расжатия.
Преобразование сжатия обеспечивает получение сжатого сообщения из исходного. Разжатие же обеспечивает получение исходного сообщения (или его приближения) из сжатого.
Все методы сжатия делятся на два основных класса
- без потерь,
- с потерями.
Кардинальное различие между ними в том, что сжатие без потерь обеспечивает возможность точного восстановления исходного сообщения. Сжатие с потерями же позволяет получить только некоторое приближение исходного сообщения, то есть отличающееся от исходного, но в пределах некоторых заранее определённых погрешностей. Эти погрешности должны определяться другой моделью — моделью приёмника, определяющей, какие данные и с какой точностью представленные важны для получателя, а какие допустимо выбросить.
Характеристики алгоритмов сжатия и применимость
Коэффициент сжатия
Коэффициент сжатия — основная характеристика алгоритма сжатия, выражающая основное прикладное качество. Она определяется как отношение размера несжатых данных к сжатым, то есть:
- k = So/Sc,
где k — коэффициент сжатия, So — размер несжатых данных, а Sc — размер сжатых. Таким образом, чем выше коэффициент сжатия, тем алгоритм лучше. Следует отметить:
- если k = 1, то алгоритм не производит сжатия, то есть получает выходное сообщение размером, равным входному;
- если k < 1, то алгоритм порождает при сжатии сообщение большего размера, нежели несжатое, то есть, совершает «вредную» работу.
Ситуация с k < 1 вполне возможна при сжатии. Невозможно получить алгоритм сжатия без потерь, который при любых данных образовывал бы на выходе данные меньшей или равной длины. Обоснование этого факта заключается в том, что количество различных сообщений длиной n Шаблон:Е:бит составляет ровно 2n. Тогда количество различных сообщений с длиной меньшей или равной n (при наличии хотя бы одного сообщения меньшей длины) будет меньше 2n. Это значит, что невозможно однозначно сопоставить все исходные сообщения сжатым: либо некоторые исходные сообщения не будут иметь сжатого представления, либо нескольким исходным сообщениям будет соответствовать одно и то же сжатое, а значит их нельзя отличить.
Коэффициент сжатия может быть как постоянным коэффициентом (некоторые алгоритмы сжатия звука, изображения и т. п., например А-закон, μ-закон, ADPCM), так и переменным. Во втором случае он может быть определён либо для какого либо конкретного сообщения, либо оценён по некоторым критериям:
- среднее (обычно по некоторому тестовому набора данных);
- максимальное (случай наилучшего сжатия);
- минимальное (случай наихудшего сжатия);
или каким либо другим. Коэффициент сжатия с потерями при этом сильно зависит от допустимой погрешности сжатия или его качества, которое обычно выступает как параметр алгоритма.
Допустимость потерь
Основным критерием различия между алгоритмами сжатия является описанное выше наличие или отсутствие потерь. В общем случае алгоритмы сжатия без потерь универсальны в том смысле, что их можно применять на данных любого типа, в то время как применение сжатия потерь должно быть обосновано. Некоторые виды данных не приемлят каких бы то ни было потерь:
- символические данные, изменение которых неминуемо приводит к изменению их семантики: программы и их исходные тексты, двоичные массивы и т. п.;
- жизненно важные данные, изменения в которых могут привести к критическим ошибкам: например, получаемые с медицинской измерительной техники или контрольных приборов летательных, космических аппаратов и т. п.
- данные, многократно подвергаемые сжатию и расжатию: рабочие графические, звуковые, видеофайлы.
Однако сжатие с потерями позволяет добиться гораздо больших коэффициентов сжатия за счёт отбрасывания незначащей информации, которая плохо сжимается. Так, например алгоритм сжатия звука без потерь FLAC, позволяет в большинстве случаев сжать звук в 1,5—2,5 раза, в то время как алгоритм с потерями Vorbis, в зависимости от установленного параметра качетсва может сжать до 15 раз с сохранением приемлемого качества звучания.
Системные требования алгоритмов
Различные алгоритмы могут требовать различного количества ресурсов вычислительной системы, на которых исполняются:
- оперативной памяти (под промежуточные данные);
- постоянной памяти (под код программы и константы);
- процессорного времени.
В целом, эти требования зависят от сложности и «интеллектуальности» алгоритма. По общей тенденции, чем лучше и универсальнее алгоритм, тем большие требования с машине он предъявляет. Однако в специфических случаях простые и компактные алгоритмы могут работать лучше. Системные требования определяют их потребительские качества: чем менее требователен алгоритм, тем на более простой, а следовательно, компактной, надёжной и дешёвой системе он может работать.
Так как алгоритмы сжатия и разжатия работают в паре, то имеет значение также соотношение системных требований к ним. Нередко можно усложнив один алгоритм можно значительно упростить другой. Таким образом мы можем иметь три варианта:
- Алгоритм сжатия гораздо требовательнее к ресурсам, нежели алгоритм расжатия.
- Это наиболее распространённое соотношение, и оно применимо в основном в случаях, когда однократно сжатые данные будут использоваться многократно. В качетсве примера можно привести цифровые аудио и видеопроигрыватели.
- Алгоритмы сжатия и расжатия имеют примерно равные требования.
- Наиболее приемлемый вариант для линии связи, когда сжатие и расжатие происходит однократно на двух её концах. Например, это могут быть телефония.
- Алгоритм сжатия существенно менее требователен, чем алгоритм разжатия.
- Довольно экзотический случай. Может применяться в случаях, когда передатчиком является ультрапортативное устройство, где объём доступных ресурсов весьма критичен, например, космический аппарат или большая распределённая сеть датчиков, или это могут быть данные распаковка которых требуется в очень малом проценте случаев, например запись камер видеонаблюдения.
См. также
- Теория информации
- Теория вероятностей
- Статистика
Wikimedia Foundation.
2010.
В статье рассматриваются основные методы сжатия данных, приводится классификация наиболее известных алгоритмов, и на простых примерах обсуждаются механизмы работы методов CS&Q, RLE-кодирования, Хаффмана, LZW, дельта-кодирования, JPEG и MPEG. Статья представляет собой авторизованный перевод [1].
Передача данных и их хранение стоят определенных денег. Чем с большим количеством информации приходится иметь дело, тем дороже обходится ее хранение и передача. Зачастую данные хранятся в наиболее простом виде, например в коде ASCII (American Standard Code for Information Interchange — американский стандартный код для обмена информацией) текстового редактора, в исполняемом на компьютере двоичном коде, в отдельных файлах, полученных от систем сбора данных и т.д. Как правило, при использовании этих простых методов кодирования объем файлов данных примерно в два раза превышает действительно необходимый размер для представления информации. Ее сжатие с помощью алгоритмов и программ позволяет решить эту задачу. Программа сжатия используется для преобразования данных из простого формата в оптимизированный по компактности. Наоборот, программа распаковки возвращает данные в исходный вид. Мы обсудим шесть методов сжатия данных в этом разделе. Первые три из них являются простыми методами кодирования: кодирование длин серий с передачей информации об их начале и длительности; кодирование Хаффмана и дельта-кодирование. Последние три метода являются сложными процедурами сжатия данных, которые стали промышленными стандартами: LZW, форматы JPEG и MPEG.
Методы сжатия данных
В таблице 1 показаны два разных способа распределения алгоритмов сжатия по категориям. К категории (а) относятся методы, определяемые как процедуры сжатия без потерь и с потерями. При использовании метода сжатия без потерь восстановленные данные идентичны исходным. Этот метод применяется для обработки многих типов данных, например для исполняемого кода, текстовых файлов, табличных данных и т.д. При этом не допускается потеря ни одного бита информации. В то же время файлы данных, представляющие изображения и другие полученные сигналы, нет необходимости хранить и передавать без потерь. Любой электрический сигнал содержит шум. Если изменения в этих сигналах схожи с небольшим количеством дополнительного шума, вреда не наносится. Алгоритм, применение которого приводит к некоторому ухудшение параметров сигнала, называется сжатием с потерями. Методы сжатия с потерями намного эффективнее методов кодирования без потерь. Чем выше коэффициент сжатия, тем больше шума добавляется в данные.
| Табл. 1. Классификация методов сжатия: без потерь и с потерями | ||||||||||
|
Передаваемые по интернету изображения служат наглядным примером того, почему необходимо сжатие данных. Предположим, что требуется загрузить из интернета цифровую цветную фотографию с помощью 33,6-Кбит/с модема. Если изображение не сжато (например, это файл TIFF-формата), его объем составит около 600 Кбайт. При сжатии фото без потерь (в файл GIF-формата) его размер уменьшится примерно до 300 Кбайт. Метод сжатия с потерями (JPEG-формат) позволит уменьшить размер файла до 50 Кбайт. Время загрузки этих трех файлов составляет 142, 72 и 12 с, соответственно. Это большая разница. JPEG идеально подходит для работы с цифровыми фотографиями, тогда как GIF используется только для рисованных изображений.
Второй способ классификации методов сжатия данных проиллюстрирован в таблице 2. Большинство программ сжатия работает с группами данных, которые берутся из исходного файла, сжимаются и записываются в выходной файл. Например, одним из таких методов является CS&Q (Coarser Sampling and Quantization — неточные выборка и дискретизация). Предположим, что сжимается цифровой сигнал, например звуковой сигнал, который оцифрован с разрядностью 12 бит. Можно прочесть две смежные выборки из исходного файла (24 бит), отбросить одну выборку полностью, отбросить наименее значащие 4 бита из другой выборки, затем записать оставшиеся 8 битов в выходной файл. При 24 входных битах и 8 выходных коэффициент сжатия алгоритма с потерями равен 3:1. Этот метод высокоэффективен при использовании сжатия с преобразованием, составляющего основу алгоритма JPEG.
| Табл. 2. Классификация методов сжатия: фиксированный и переменный размер группы | ||||||||||||||||
|
В методе CS&Q из входящего файла читается фиксированное число битов, и меньшее фиксированное число записывается в выходной файл. Другие методы сжатия позволяют создавать переменное число битов для чтения или записи. Причина того, почему в таблицу не вошли форматы JPEG и MPEG, в том, что это составные алгоритмы, в которых совмещено множество других методов.
RLE-кодирование
Файлы данных содержат одни и те же символы, повторяющиеся множество раз в одном ряду. Например, в текстовых файлах используются пробелы для разделения предложений, отступы, таблицы и т.д. Цифровые сигналы также содержат одинаковые величины, указывающие на то, что сигнал не претерпевает изменений. Например, изображение ночного неба может содержать длинные серии символов, представляющих темный фон, а цифровая музыка может иметь длинную серию нулей между песнями. RLE-кодирование (Run-length encoding — кодирование по длинам серий) представляет собой метод сжатия таких типов файлов.
На рисунке 1 проиллюстрирован принцип этого кодирования для последовательности данных с частым повторением серии нулей. Всякий раз, когда нуль встречается во входных данных, в выходной файл записываются два значения: нуль, указывающий на начало кодирования, и число нулей в серии. Если среднее значение длины серии больше двух, происходит сжатие. С другой стороны, множество одиночных нулей в данных может привести к тому, что кодированный файл окажется больше исходного.
|
|
|
Рис. 1. Пример RLE-кодирования |

Входные данные можно рассматривать и как отдельные байты, или группы, например числа с плавающей запятой. RLE-кодирование можно использовать только в случае одного знака (как в случае в нулем в примере выше), нескольких знаков или всех знаков.
Кодирование Хаффмана
Этот метод был разработан Хаффманом в 1950-х гг. Метод основан на использовании относительной частоты встречаемости индивидуальных элементов. Часто встречающиеся элементы кодируются более короткой последовательностью битов. На рисунке 2 представлена гистограмма байтовых величин большого файла ASCII. Более 96% этого файла состоит из 31 символа: букв в нижнем регистре, пробела, запятой, точки и символа возврата каретки.
Алгоритм, назначающий каждому из этих стандартных символов пятибитный двоичный код по схеме 00000 = a, 00001 = b, 00010 = c и т.д., позволяет 96% этого файла уменьшить на 5/8 объема. Последняя комбинация 11111 будет указывать на то, что передаваемый символ не входит в группу из 31 стандартного символа. Следующие восемь битов в этом файле указывают, что представляет собой символ в соотоветствии со стандартом присвоения ASCII. Итак, 4% символов во входном файле требуют для представления 5 + 8 = 13 бит.
Принцип этого алгоритма заключается в присвоении часто употребляемым символам меньшего числа битов, а редко встречающимся символам — большего количества битов. В данном примере среднее число битов, требуемых из расчета на исходный символ, равно 0,96 . 5 + 0,04 . 13 = 5,32. Другими словами, суммарный коэффициент сжатия составляет 8 бит/5,32 бит, или 1,5 : 1.
|
|
|
Рис. 2. Гистограмма значений ASCII фрагмента текста из этой статьи |

На рисунке 3 представлена упрощенная схема кодирования Хаффмана. В таблице кодирования указана вероятность употребления символов с A по G, имеющихся в исходной последовательности данных, и их соответствия. Коды переменной длины сортируются в стандартные восьмибитовые группы. При распаковке данных все группы выстраиваются в последовательность нулей и единиц, что позволяет разделять поток данных без помощи маркеров. Обрабатывая поток данных, программа распаковки формирует достоверный код, а затем переходит к следующему символу. Такой способ формирования кода обеспечивает однозначное чтение данных.
|
|
|
||||||||||||||||||||||||
|
Рис. 3. Пример кодирования Хаффмана |

Дельта-кодирование
Термин «дельта-кодирование» обозначает несколько методов сохранения или передачи данных в форме разности между последующими выборками (или символами), а не сохранение самих выборок. На рисунке 4 приводится пример работы этого механизма. Первое значение в кодируемом файле является совпадает с исходным. Все последующие значения в кодируемом файле равны разности между соответствующим и предыдущим значениями входного файла.
|
|
|
Рис. 4. Пример дельта-кодирования |

Дельта-кодирование используется для сжатия данных, если значения исходного файла изменяются плавно, т.е. разность между следующими друг за другом величинами невелика. Это условие не выполняется для текста ASCII и исполняемого кода, но является общим случаем, когда информация поступает в виде сигнала. Например, на рисунке 5а показан фрагмент аудиосигнала, оцифрованного с разрядностью 8 бит, причем все выборки принимают значения в диапазоне –127–127. На рисунке 5б представлен кодированный вариант этого сигнала, основное отличие которого от исходного сигнала заключается в меньшей амплитуде. Другими словами, дельта-кодирование увеличивает вероятность того, что каждое значение выборки находится вблизи нуля, а вероятность того, что оно значительно больше этой величины, невелика. С неравномерным распределением вероятности работает метод Хаффмана. Если исходный сигнал не меняется или меняется линейно, в результате дельта-кодирования появятся серии выборок с одинаковыми значениями, с которыми работает RLE-алгоритм. Таким образом, в стандартном методе сжатия файлов используется дельта-кодирование с последующим применением метода Хаффмана или RLE-кодирования.
|
|
|
|
а) |
б) |
|
Рис. 5. Пример дельта-кодирования |


Механизм дельта-кодирования можно расширить до более полного метода под названием кодирование с линейным предсказанием (Linear Predictive Coding, LPC).
Чтобы понять суть этого метода, представим, что уже были закодированы первые 99 выборок из входного сигнала и необходимо произвести выборку под номером 100. Мы задаемся вопросом о том, каково наиболее вероятное ее значение? В дельта-кодировании ответом на данный вопрос является предположение, что это значение предыдущей, 99-й выборки. Это ожидаемое значение используется как опорная величина при кодировании выборки 100. Таким образом, разность между значением выборки и ожиданием помещается в кодируемый файл. Метод LPC устанавливает наиболее вероятную величину на основе нескольких последних выборок. В используемых при этом алгоритмах применяется z-преобразование и другие математические методы.
Алгоритм LZW
LZW-сжатие — наиболее универсальный метод сжатия данных, получивший распространение благодаря своей простоте и гибкости. Этот алгоритм назван по имени его создателей (Lempel-Ziv-Welch encoding — сжатие данных методом Лемпела-Зива-Велча). Исходный метод сжатия Lempel-Ziv был впервые заявлен в 1977 г., а усовершенствованный Велчем вариант — в 1984 г. Метод позволяет сжимать текст, исполняемый код и схожие файлы данных примерно вполовину. LZW также хорошо работает с избыточными данными, например табличными числами, компьютерным исходным текстом и принятыми сигналами. В этих случаях типичными значениями коэффициента сжатия являются 5:1. LZW-сжатие всегда используется для обработки файлов изображения в формате GIF и предлагается в качестве опции для форматов TIFF и PostScript.
Алгоритм LZW использует кодовую таблицу, пример которой представлен на рисунке 6. Как правило, в таблице указываются 4096 элементов. При этом кодированные LZW-данные полностью состоят из 12-битных кодов, каждый из которых соответствует одному табличному элементу. Распаковка выполняется путем извлечения каждого кода из сжатого файла и его преобразования с помощью таблицы. Табличные коды 0—255 всегда назначаются единичным байтам входного файла (стандартному набору символов). Например, если используются только эти первые 256 кодов, каждый байт исходного файла преобразуется в 12 бит сжатого LZW-файла, который на 50% больше исходного. При распаковке этот 12-битный код преобразуется с помощью кодовой таблицы в единичные байты.
|
Пример кодовой таблицы
|
|||||||||||||||||||||||
|
|
|||||||||||||||||||||||
|
Рис. 6. Пример сжатия в соответствии с таблицей кодирования |

Метод LZW сжимает данные с помощью кодов 256—4095, представляя последовательности байтов. Например, код 523 может представлять последовательность из трех байтов: 231 124 234. Всякий раз, когда алгоритм сжатия обнаруживает последовательность во входном файле, в кодируемый файл ставится код 523. При распаковке код 523 преобразуется с помощью таблицы в исходную последовательность из трех байтов. Чем длиннее последовательность, назначаемая единичному коду и чем чаще она повторяется, тем больше коэффициент сжатия.
Существуют два основных препятствия при использовании этого метода сжатия: 1) как определить, какие последовательности должны указываться в кодовой таблице и 2) как обеспечить программу распаковки той же таблицей, которую использует программа сжатия. Алгоритм LZW позволяет решить эти задачи.
Когда программа LZW начинает кодировать файл, таблица содержит лишь первые 256 элементов — остальная ее часть пуста. Это значит, что первые коды, поступающие в сжимаемый файл, представляют собой единичные байты исходного файла, преобразуемые в 12-бит группы. По мере продолжения кодирования LZW-алгоритм определяет повторяющиеся последовательности данных и добавляет их в кодовую таблицу. Сжатие начинается, когда последовательность обнаруживается вторично. Суть метода в том, что последовательность из входящего файла не добавляется в кодовую таблицу, если она уже была помещена в сжатый файл как отдельный символ (коды 0—255). Это важное условие, поскольку оно позволяет программе распаковки восстановить кодовую таблицу непосредственно из сжатых данных, не нуждаясь в ее отдельной передаче.
JPEG
Из множества алгоритмов сжатия с потерями кодирование с преобразованием оказалось наиболее востребованным. Наилучший пример такого метода — популярный стандарт JPEG (Joint Photographers Experts Group — Объединенная группа экспертов по машинной обработке фотографических изображений). Рассмотрим на примере JPEG работу алгоритма сжатия с потерями.
Мы уже обсудили простейший метод сжатия с потерями CS&Q, в котором уменьшается количество битов на выборку или полностью отбрасываются некоторые выборки. Оба этих приема позволяют достичь желаемого результата — файл становится меньше за счет ухудшения качества сигнала. Понятно, что эти простые методы работают не самым лучшим образом.
Сжатие с преобразованием основано на простом условии: в трансформированном сигнале (например, с помощью преобразования Фурье) полученные значения данных не несут прежней информационной нагрузки. В частности, низкочастотные компоненты сигнала начинают играть более важную роль, чем высокочастотные компоненты. Удаление 50% битов из высокочастотных компонентов может привести, например, к удалению лишь 5% закодированной информации.
Из рисунка 7 видно, что JPEG-сжатие начинается путем разбиения изображения на группы размером 8×8 пикселов. Полный алгоритм JPEG работате с широким рядом битов на пиксел, включая информацию о цвете. В этом примере каждый пиксел является единичным байтом, градацией серого в диапазоне 0—255. Эти группы 8×8 пикселов обрабатываются при сжатии независимо друг от друга. Это значит, что каждая группа сначала представляется 64 байтами. Вслед за преобразованием и удалением данных каждая группа представляется, например, 2—20 байтами. При распаковке сжатого файла требуется такое же количество байтов для аппроксимации исходной группы 8×8. Эти аппроксимированные группы затем объединяются, воссоздавая несжатое изображение. Почему используются группы размерами 8×8, а не 16×16? Такое группирование было основано исходя из максимального возможного размера, с которым работали микросхемы на момент разработки стандарта.
|
|
|
Рис. 7. Пример применения метода сжатия JPEG. Три группы 8?8, показанные в увеличенном виде, представляют значения отдельных пикселов |

Для реализации методов сжатия было исследовано множество различных преобразований. Например, преобразование Karhunen-Loeve обеспечивает наиболее высокий коэффициент сжатия, но оно трудно осуществляется. Метод преобразования Фурье реализуется гораздо проще, но он не обеспечивает достаточно хорошего сжатия. В конце концов, выбор был сделан в пользу разновидности метода Фурье — дискретного косинусного преобразования (Discrete Cosine Transform — DCT).
На примере работы алгоритма JPEG видно, как несколько схем сжатия объединяются, обеспечивая большую эффективность. Вся процедура сжатия JPEG состоит из следующих этапов:
– изображение разбивается на группы 8×8;
– каждая группа преобразуется с помощью преобразования DCT;
– каждый спектральный элемент 8×8 сжимается путем сокращения числа битов и удаления некоторых компонентов с помощью таблицы квантования;
– видоизмененный спектр преобразуется из массива 8×8 в линейную последовательность, все высокочастотные компоненты которой помещаются в ее конец;
– серии нулей сжимаются с помощью метода RLE;
– последовательность кодируется либо методом Хаффмана, либо арифметическим методом для получения сжатого файла.
MPEG
MPEG (Moving Pictures Experts Group — Экспертная группа по кинематографии) — стандарт сжатия цифровых видеоданных. Этот алгоритм обеспечивает также сжатие звуковой дорожки к видеофильму. MPEG представляет собой еще более сложный, чем JPEG, стандарт с огромным потенциалом. Можно сказать, это ключевая технология XXI века.
У MPEG имеется несколько очень важных особенностей. Так например, он позволяет воспроизводить видеофильм в прямом и обратном направлениях, в режиме нормальной и повышенной скорости. К кодированной информации имеется прямой доступ, т.е. каждый отдельный кадр последовательности отображается как неподвижное изображение. Таким образом, фильм редактируется — можно кодировать его короткие фрагменты, не используя всю последовательность в качестве опорной. MPEG также устойчив к ошибкам, что позволяет избегать цифровых ошибок, приводящих к нежелательному прерыванию воспроизведения.
Используемый в этом стандарте метод можно классифицировать по двум типам сжатия: внутрикадровое и межкадровое. При сжатии по первому типу отдельные кадры, составляющие видеопоследовательность, кодируются так, как если бы они были неподвижными изображениями. Такое сжатие выполняется с помощью JPEG-стандарта с несколькими вариациями. В терминологии MPEG кадр, закодированный таким образом, называется внутрикодированным, или I-picture.
Наибольшая часть пикселов в видеопоследовательности изменяется незначительно от кадра к кадру. Если камера не движется, наибольшая часть изображения состоит из фона, который не меняется на протяжении некоторого количества кадров. MPEG использует это обстоятельство, сжимая избыточную информацию между кадрами с помощью дельта-кодирования. После сжатия одного из кадров в виде I-picture последующие кадры кодируются как изображения с предсказанием, или P-pictures, т.е. кодируются только изменившиеся пикселы, т.к. кадры I-picture включены в P-picture.
Эти две схемы сжатия составляют основу MPEG, тогда как практическая реализация данного метода намного сложнее описанной. Например, кадры P-picture могут использовать изображение I-picture как опорное, которое претерпело изменение при перемещении объектов в последовательности изображений. Существуют также двунаправленные предиктивно-кодированные изображения, или B-pictures. Эти видеокадры формируются способом предсказания «вперед» и «назад» на основе I-picture. При этом обрабатываются участки изображения, которые постепенно меняются на протяжении множества кадров. Отдельные кадры также хранятся без соблюдения последовательности в сжатых данных, чтобы облегчить упорядочение изображений I-, P- и B-pictures. Наличие цвета и звука еще больше усложняет реализацию этого алгоритма.
Наибольшее искажение при использовании формата MPEG наблюдается при быстром изменении больших частей изображения. Для поддержания воспроизведения с быстро меняющимися сценами на должном уровне требуется значительный объем информации. Если скорость передачи данных ограничена, зритель в этом случае видит ступенчатообразные искажения при смене сцен. Эти искажения сводятся к минимуму в сетях с одновременной передачей данных по нескольким видеоканалам, например в сети кабельного телевидения. Внезапное увеличение объема данных, требуемое для поддержки быстро меняющейся сцены в видеоканале, компенсируется относительно статическими изображениями, передаваемыми по другим каналам.
Литература
1. Steven W. Smith, Data compression tutorial Part 1, Part 2, and Part 3.