Search code, repositories, users, issues, pull requests…
Provide feedback
Saved searches
Use saved searches to filter your results more quickly
Sign up
multi-tacotron-voice-cloning
Project ID: 150
Star
0
Find file
Download source code
zip
tar.gz
tar.bz2
tar
-
Clone with SSH
-
Clone with HTTPS
-
Open in your IDE
Visual Studio Code (SSH)Visual Studio Code (HTTPS)IntelliJ IDEA (SSH)IntelliJ IDEA (HTTPS)
- Copy SSH clone URL[email protected]:vanutp/multi-tacotron-voice-cloning.git
- Copy HTTPS clone URLhttps://foxlab.dev/vanutp/multi-tacotron-voice-cloning.git
- README
- MIT License
Клонирование голоса при помощи нейросети
overbafer1Сегодня мы разбёрем метод подмены голоса при помощи нейросети, благодаря которой, вы можете воспроизвести практически любой текст, любым голосом человека(даже знаменитостей)

Так как это нейросеть, то что бы добиться приемлемого качества голоса, необходимо долго «учить» её, на основе разных голосовых записей человека
это занимает сотни часов и десятки гигабайт файлов.
Но в этой статье мы разберём 2 возможных пути этой реализации:
1) Установка утилиты непосредственно на наш ПК и проведение всех манипуляций практически с нуля(заранее скачав «натренированные» данные)
2) Онлайн решение на Колаборатории гугла (быстро,есть русский язык)
Сразу скажу, что онлайн решение будет более быстрым и менее геморным, но а если вы хотите тренировать свою нейросеть, то тут никак не обойтись без установки всего этого на ПК.
Итак, рассмотрим сначала первый вариант.
Устанавливаем Multi-Tacotron-Voice-Cloning на ваш ПК
1)Переходим по ссылке на github проект клонирования голоса: https://github.com/vlomme/Multi-Tacotron-Voice-Cloning
и сразу скачаем проект на пк

2)Скачиваем заранее натренированные модели:
https://drive.google.com/uc?id=1aQBmpflbX_ePUdXTSNE4CfEL9hdG2-O8
3) Если ваш ПК и интернет это позволяет, рекомендуется также скачать
готовый сет для клонирования голоса:
http://www.openslr.org/resources/12/train-clean-100.tar.gz
Дальше разберемся что куда кидать.
4)Если вы устанавливали Avatarify(подмена лица), то у вас должен быть установленная Anaconda prompt.
Если у вас её нет, то скачиваем по ссылке:
https://www.anaconda.com/products/individual#Downloads
Нужно выбрать Python 3.7 версию
5) Нужно также скачать и установить тулкит CUDA 10.0, если конечно до этого не устанавливали.
https://developer.nvidia.com/cuda-10.0-download-archive
6)После всего этого, запускаем Anaconda prompt(miniconda3) и прописываем следующие команды:
conda create -n clone python=3.6

Далее нас попросят нажать y и продолжить(enter):

Готово,теперь нам нужно активировать виртуальную среду, которую мы только что сделали
Для этого прописываем там же:
conda activate clone
После этого, нужно устанавливать необходимые пакеты
прописываем в консоле Anaconda:
conda install pytorch

Также подтверждаем
Теперь распаковываем архив с github, и копируем его путь.Далее в консоли анаконды прописываем:
cd (ВАШ ПУТЬ К ФАЙЛАМ С АРХИВА)
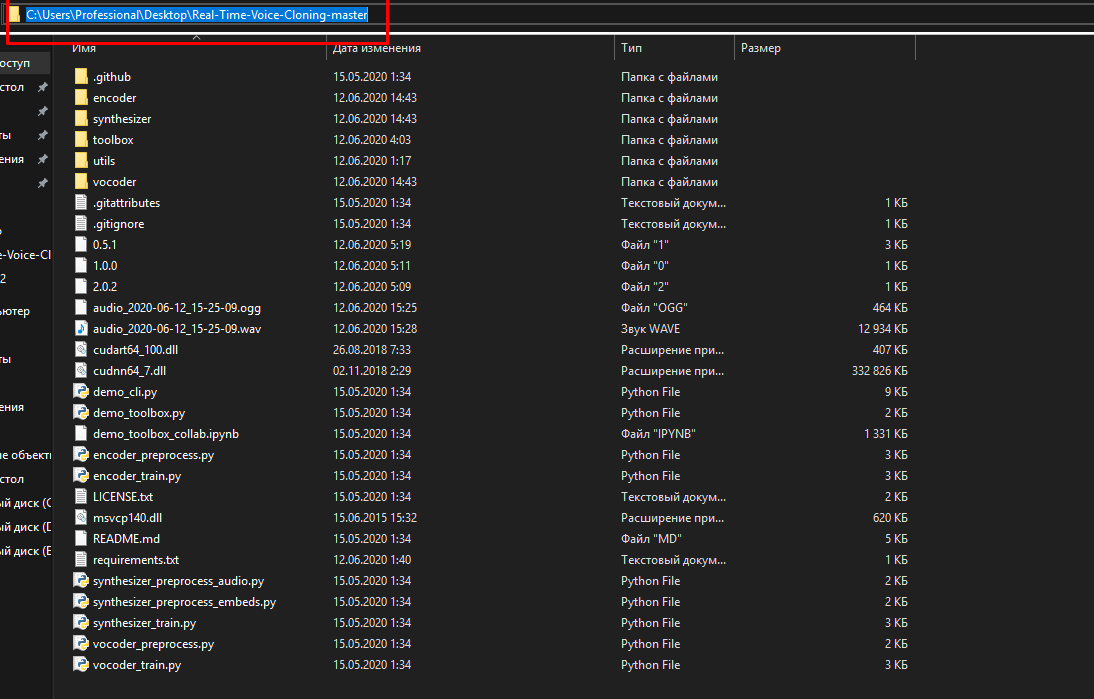

Теперь прописываем:
pip install -r requirements.txt

пошла установка необходимых модулей,нужно дождаться конца установки.
ещё пропишем одну команду:
conda install numba
Теперь нужно распаковать те доп. архивы,которые вы скачивали ранее
архив pretrained.zip распаковываем прямо в папку с программой Real-Time-Voice-Cloning-master, а второй архив если скачивали:
создаём в папке с программой подпапку LibriSpeech
в ней создаём папку train-clean-100 и туда скидываем данные с распакованного архива.
Так же,что бы не было ошибок, закидываем в папку утилиты dll файлы CUDA:
cudart64_100.dll
cudnn64_7.dll
Их можно найти в папке: C:\ProgramData\Miniconda3\pkgs\pytorch-1.0.0-py3.7_cuda100_cudnn7_1\Lib\site-packages\torch\lib
Если устанавливали avatarify, то тут: ProgramData\Miniconda3\envs\avatarify\Lib\site-packages\torch\lib
Теперь попробуем запустить:
Вводим в анаконде следующее:
python demo_toolbox.py
Процесс много жрёт! на системе с 16 гб ОЗУ пришлось закрыть почти все программы, имейте ввиду.
У нас откроется главное окно:

Вверху по кнопке Browse мы загружаем нужный нам образец голоса в формате wav. Либо можно записать фрагмент своего голоса, нажав на кнопку record.
Вы должны понимать, что речь должна быть нормальной, состоящей из 9-10 слов, обладать чёткостью. Натренированные данные заточены под английский текст, так что с русским тут не выйдет(англ. более менее)

После того, как загрузили голос, пишем нужный текст на английском вверху справа, и нажимаем кнопку Synthesize and vocode. После чего, мы услышим полученный вариант голоса
Если несколько раз проводить эту процедуру, то качество голоса может самостоятельно улучшаться.
Вот пример голоса Игоря, до и через несколько проходов:
https://drive.google.com/file/d/12gaRJEx2WZdNeWQd2pJHVGVqa3rVmyXv/view?usp=sharing
Если хотите сохранить результат:
Редактируем изначально файл demo_cli.py, прописываем нужный текст и имя исх.файла:

Сохраняем, и в анаконде вместо python demo_toolbox.py прописываем:
python demo_cli.py
И всё, пойдёт процесс генерации. По завершению вы получите в той же папке готовый вариант.
Что же,вариант очень интересный, но занимает много времени,ресурсов и сил.
Да и тренировать свои данные надо,не вариант
переходим ко второму варианту.
Tacotrone на Colaboratory
1.Переходим по ссылке
https://colab.research.google.com/github/vlomme/Multi-Tacotron-Voice-Cloning/blob/master/Multi_Tacotron_Voice_Cloning.ipynb
2.Нажимаем Connect в правом углу

Теперь во вкладке runtime выбираем run all.


Теперь в конце отобразятся 2 аудиофайла: Оригинал и склонированный, с заданным текстом.
здесь уже подготовлено всё,даже пример голоса. Можете попробовать написать свой текст на русском в этом поле:

Теперь, если мы хотим загрузить чей-то голос, то для начала надо подготовить его в формате wav, затем открыть слева в меню Files:


Нажимаем кнопку Upload вверху, и выбираем наш подготовленный голос. достаточно даже 9-15 секунд речи.
после того, как файл прогрузился, сместим его ближе к ex.wav:

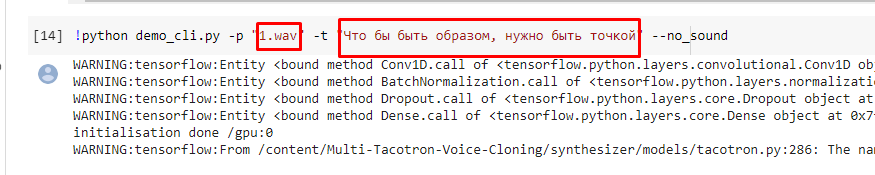
В этой строчке меняем сначала название файла на ваш загруженный, и также меняем текст на желаемый.
После этого нажимаем запуск кода:
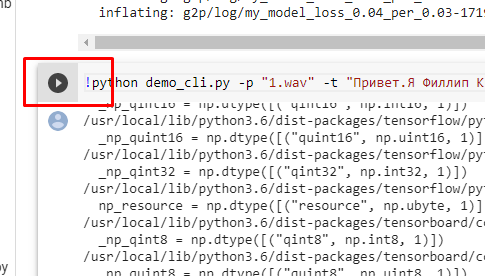
После завершения, прокручиваем вниз и запускаем следующий код:

Ниже отобразится клонированный файл,который вы можете прослушать либо скачать
Вот пример голоса Киркорова:
https://drive.google.com/file/d/1tPvgt2Tc8IMqukMS4LX3eb2g2gEN4LNL/view?usp=sharing
Стоит отметить, что не с каждым примером голоса всё работает корректно.Речи может совсем не быть, или очень не разборчивая
Так что нужно поэкспериментировать, ведь тут тоже данные тренировались на шаблонном примере, но может выйти очень неплохой результат и с этими данными.Экспериментируйте с разными вариантами текста, а так же голоса.
Стоит отметить, что при перезагрузке этого сайта вам придётся проводить все манипуляции заново, а так же не будут сохраняться ваши загруженные файлы.
Многоязычный синтез речи с клонированием
Время на прочтение
5 мин
Количество просмотров 41K
Хотя нейронные сети стали использоваться для синтеза речи не так давно (например), они уже успели обогнать классические подходы и с каждым годам испытывают на себе всё новые и новый задачи.
Например, пару месяцев назад появилась реализация синтеза речи с голосовым клонированием Real-Time-Voice-Cloning. Давайте попробуем разобраться из чего она состоит и реализуем свою многоязычную (русско-английскую) фонемную модель.
Строение
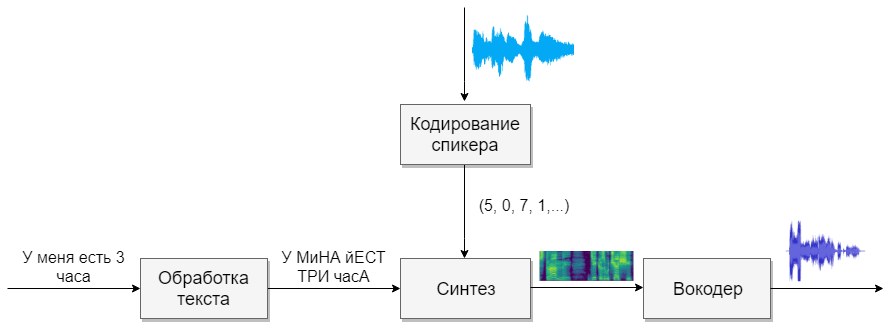
Наша модель будет состоять из четырёх нейронных сетей. Первая будет преобразовывать текст в фонемы (g2p), вторая — преобразовывать речь, которую мы хотим клонировать, в вектор признаков (чисел). Третья — будет на основе выходов первых двух синтезировать Mel спектрограммы. И, наконец, четвертая будет из спектрограмм получать звук.
Наборы данных
Для этой модели нужно много речи. Ниже базы, которые в этом помогут.
Обработка текста
Первой задачей будет обработка текста. Представим текст в том виде, в котором он будет в дальнейшем озвучен. Числа представим прописью, а сокращения раскроем. Подробнее можно почитать в статье посвященной синтезу. Это тяжелая задача, поэтому предположим, что к нам поступает уже обработанный текст (в базах выше он обработан).
Следующим вопросом, которым следуют задаться, это использовать ли графемную, или фонемную запись. Для одноголосного и одноязычного голоса подойдет и буквенная модель. Если хотите работать с многоголосой многоязычной моделью, то советую использовать транскрипцию (Гугл тоже).
G2P
Для русского языка существует реализация под названием russian_g2p. Она построена на правилах русского языка и хорошо справляется с задачей, но имеет минусы. Не для всех слов расставляет ударения, а также не подходит для многоязычной модели. Поэтому возьмём созданный ей словарь, добавим словарь для английского языка и скормим нейронной сети (например этим 1, 2)
Прежде чем обучать сеть, стоит подумать, какие звуки из разных языков звучат похоже, и можно им выделить один символ, а для каких нельзя. Чем больше будет звуков, тем сложнее модели учиться, а если их будет слишком мало, то у модели появиться акцент. Не забудьте ударным гласным выделять отдельные символы. Для английского языка вторичное ударение играет малую роль, и я бы его не выделял.
Кодирование спикеров
Сеть схожа с задачей идентификации пользователя по голосу. На выходе у разных пользователей получаются разные вектора с числами. Предлагаю использовать реализацию самого CorentinJ, которая основана на статье. Модель представляет собой трехслойный LSTM с 768 узлами, за которыми следует полносвязный слой из 256 нейронов, дающие вектор из 256 чисел.
Опыт показал, что сеть, обученная на английской речи, хорошо справляется и с русской. Это сильно упрощает жизнь, так как для обучения требуется очень много данных. Рекомендую взять уже обученную модель и дообучить на английской речи из VoxCeleb и LibriSpeech, а также всей русской речи, что найдёте. Для кодера не нужна текстовая аннотация фрагментов речи.
Тренировка
- Запустите
python encoder_preprocess.py <datasets_root>для обработки данных - Запустите «visdom» в отдельном терминале.
- Запустите
python encoder_train.py my_run <datasets_root>для тренировки кодировщика
Синтез
Перейдём к синтезу. Известные мне модели не получают звук напрямую из текста, так как, это сложно (слишком много данных). Сначала из текста получается звук в спектральной форме, а уже потом четвертая сеть будет переводить в привычный голос. Поэтому сначала поймём, как спектральное вид связанна с голосом. Проще разобраться в обратной задаче, как из звука получить спектрограмму.
Звук разбивается на отрезки длинной 25 мс с шагом 10 мс (по умолчанию в большинстве моделей). Далее с помощью преобразования Фурье для каждого кусочка вычисляется спектр (гармонические колебания, сумма которых даёт исходный сигнал) и представляется в виде графика, где вертикальная полоса — это спектр одного отрезка (по частоте), а по горизонтальной — последовательность отрезков (по времени). Этот график называется спектрограммой. Если же частоту закодировать нелинейно (нижние частоты качественнее, чем верхние), то изменится масштаб по вертикали (нужно для уменьшения данных) то такой график называют Mel спектрограммой. Так устроен человеческий слух, что небольшое отклонение на нижних частотах мы слышим лучше, чем на верхних, поэтому качество звука не пострадает
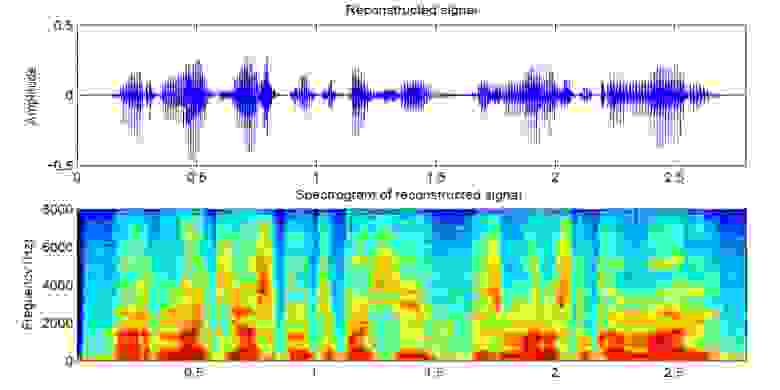
Существует несколько хороших реализаций синтеза спектрограмм, такие как Tacotron 2 и Deepvoice 3. У каждой из этих моделей есть свои реализации, например 1, 2, 3, 4. Будем использовать(как и CorentinJ) модель Tacotron от Rayhane-mamah.
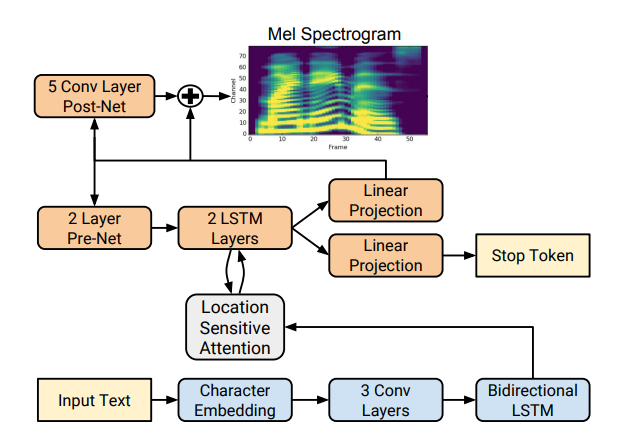
Tacotron основан на сети seq2seq с механизмом внимания. Ознакомитесь с подробностями в статье.
Тренировка
Не забудьте отредактировать utils/symbols.py, если будете синтезировать не только английскую речь, hparams.pу, а так же preprocess.py.
Для синтеза нужно много чистого, хорошо размеченного звука разных спикеров. Здесь чужой язык не поможет.
- Запустите
python synthesizer_preprocess_audio.py <datasets_root>для создания обработанного звука и спектрограмм - Запустите
python synthesizer_preprocess_embeds.py <datasets_root>для кодирования звука (получения признаков голоса) - Запустите
python synthesizer_train.py my_run <datasets_root>для тренировки синтезатора
Вокодер
Теперь осталось только преобразовать спектрограммы в звук. Для этого служит последняя сеть — вокодер. Возникает вопрос, если спектрограммы получаются из звука с помощью преобразования Фурье, нельзя ли с помощью обратного преобразования получить снова звук? Ответ и да, и нет. Гармонические колебания, из которых состоит исходный сигнал, содержат как амплитуду, так и фазу, а наши спектрограммы содержат информацию только об амплитуде (ради сокращения параметров и работаем со спекрограммами), поэтому если мы сделаем обратное преобразование Фурье, то получим плохой звук.
Для решения этой проблемы придумали быстрый алгоритм Гриффина-Лима. Он делает обратное преобразование Фурье спектрограммы, получая «плохой» звук. Далее делает прямое преобразования этого звука и получают спектр, в котором уже содержится немножко информации о фазе, причём амплитуда в процессе не меняется. Далее берётся еще раз обратное преобразование и получается уже более чистый звук. К сожалению, качество сгенерированной таким алгоритмом речи оставляет желать лучшего.
На его смену пришли нейронные вокодеры, такие как WaveNet, WaveRNN, WaveGlow и другие. CorentinJ использовал модель WaveRNN за авторством fatchord

Для предобработки данных используется два подхода. Либо получить спектрограммы из звука (с помощью преобразования Фурье), или из текста (с помощью модели синтеза). Google рекомендует второй подход.
Тренировка
- Запустите
python vocoder_preprocess.py <datasets_root>для синтеза спектрограмм - Запустите
python vocoder_train.py <datasets_root>для вокодера
Итого
Мы получили модель многоязычного синтеза речи, умеющей клонировать голос.
Запустите toolbox: python demo_toolbox.py -d <datasets_root>
Примеры можно послушать тут
Советы и выводы
- Нужно много данных (>1000 голосов, >1000 часов)
- Скорость работы сравнима с реальным временем только при синтезе минимум 4 предложений
- Для кодера используйте предобученную модель для английского языка, немножко дообучив. Она справляется хорошо
- Синтезатор, обученный на «чистых» данных, работает лучше, но хуже клонирует, чем тот, кто обучался на большем объёме, но грязных данных
- Модель хорошо работает только на данных, на которых училась
Можете синтезировать свой голос онлайн с помощью colab, или посмотреть мою реализацию на github и скачать мои веса.
Search code, repositories, users, issues, pull requests…
Provide feedback
Saved searches
Use saved searches to filter your results more quickly
Sign up
vlomme / multi-tacotron-voice-cloning
Goto Github
PK
View Code? Open in Web Editor
NEW
33.0
97.0
1009 KB
Phoneme multilingual(Russian-English) voice cloning based on
Home Page: https://github.com/CorentinJ/Real-Time-Voice-Cloning
License: Other
Jupyter Notebook 0.98%
Python 99.02%
deep-learning
pytorch
tensorflow
tts
voice-cloning
g2p
tacotron
wavernn
russian
Contributors


multi-tacotron-voice-cloning’s Issues
WaveGlow
Is it possible to use WaveGlow?
And not to train your own model but use pretrained?
How to run on new voices?
Hello,
Amazing work.
I am running inference using your models on 2080 gpu. your example is perfect. But when I give a new audio clip (in English) and make it say the same Russian sentence, the output audio isn’t good. There’s lot of noise, and cloning is not even of good quality.
My question is:
- Can I use pretrained models(from this repo) to clone a new speaker, and make it speak Russian? or Should I train every thing(g2p, encoder, synthesizer, vocoder) on new speaker(assuming I obtain hours of this speaker’s audio)? Please advise.
Thanks,
S
Вопрос по поводу поддержки
Здравствуйте. У меня видео-карта GeForce GT 630M. Уж очень нужно запустить программу, но там у PyTorch минимум compute capability 3.0, а на моей видеокарте 2.1
Нужен именно интерфейс, для изучения графиков, на Colab только ввиде командной строки.
Если устанавливаю версию только CPU, то пишет, что не поддерживается.
Может быть есть способ отключить использование GPU и перейти на CPU?
No module named ‘tensorflow.contrib’
Tryed to run google collab, but there is an error. Please help.
How to implement it on local Computer?
Обучение нейронки
Доброго времени суток!
Как начать С НУЛЯ обучать нейронку? (т.е не нужен pretrained model)
missed file «g2p/en.dic»
Speech2Speech вместо Text2Speech
Спасибо больше за проект, я ищу какое-то быстрое решение для себя, которое могло бы делать voice style transfer (пародировать записанный голос по семплу), можно ли применить ваш синтезатор для этой задачи?
Есть альтернативные модели клонирующие лучше чем эта?(оригинальная английская модель не в счет)
Обучение сети для одного голоса.
Предположим нужно добиться хорошего звучания всего одного голоса(русский). Куда нажимать(инструкция для хомяков).
OOM Error by additional text to be spoken
I have a problem inserting additional text to be spoken into the toolbox. The additional lines cause the vocoder to crash with out of memory error. Trying with the original code from CorentinJ and code from here I found that activating g2p in toolbox / __ init__ caused this error.
Apparently the g2p binds the resources that are important for other neural networks and does not release them when it has finished its task.
Can you fix that somehow?
Thank you
pretrained Tocotron2
Hi. Thank you.
Is it possible to not train your own Tacotron2 and use pretrained model on russian language?
This for example https://github.com/alphacep/tn2-wg
Use of language embedding
Hi @vlomme,
Great work here, and thanks for open-sourcing it. I’m trying to understand how this works so that I can replicate it. I’ve gone through the code and don’t see any language embedding, which I thought would be how you separate the speaker from the language.
Can you please explain how language-speaker independence is achieved?
Training for other language other than Russian? English -> Other Language?
Hello, I am looking for a way So I can able to make a Japanese speaker speaks English, is it possible?
ModuleNotFoundError: No module named ‘distance’
File «…\g2p\train.py», line 4, in
from distance import levenshtein
ModuleNotFoundError: No module named ‘distance’
Training encoder
Thanks for work! Help me to train an encoder. How is it possible to add new custom voices to train datasets, or only fixed (like LibriSpeech: train-other-500, VoxCeleb1…) are available through the interface of commands:
python encoder_preprocess.py <datasets_root>
and
python encoder_train.py my_run <datasets_root>/SV2TTS/encoder
If possible, than how i should keep files, in root data directory or subfolders, in what formats? I tried to add my voice to subfolder but got an error like:
«Python encoder_preprocess.py data
Arguments:
datasets_root: data
out_dir: data/SV2TTS/encoder
datasets: [‘preprocess_voxforge’]
skip_existing: False
Preprocessing preprocess_voxforge
Couldn’t find data/book, skipping this dataset»
I looked at the source and found that there are fixed funcs that preprocess different formats of train data (like preprocess22,preprocess44…) What do they mean? Maybe i should use one of them?
Thank you.
pretrained model
Здравствуйте, экспериментировал с вашей моделью, но лишь некоторые записи дают хороший результат. На Хабре вы писали, что пробовали так же обучать модель только для русского языка и она работала лучше, у вас не осталось натренерованной модели? Если да, не могли бы вы поделиться ей?
Unable to clone any voice other then the provided «ex.wav»
Hello,
I tried using the demo with the pre-trained network.
See the attached example. The output is just pure noise.
Is there anything wrong with the voice sample i provided as input?
I tried both male / female.
Thanks,
orig_16.zip
Multi-Language Training
Hi,
I’m slightly confused in G2P model. Let’s suppose If I need to train a model which specifically translates from Russian to English (Only). Do I still need to add dictionary or train G2P model ?
Also, I’m not able to catch the significance of G2P model here. We have the synthesizer, which is already doing the same work.
Thanks!
Any Samples?
Hi I am doing similar work like yours, my datasets is «En + Chineses».
I have tried the pretrained model offered by CorentinJ, and also finetune on the pretrained model, but i have not achieve good results till now. I am still training the encoder model now. And I wonder if you have some good results to share?
Твоя версия лучше чем Real-Time-Voice-Cloning?
Интересует твоё оценочное суждение, может сэмплы накидаешь, чтобы поиметь представление?
Я пробовал https://github.com/CorentinJ/Real-Time-Voice-Cloning и результатом не впечатлён, куча каких то шумов, на пару тонов выше речь.
Не работает.
Запустил демо-версию, не работает.

How can i add Arabic Language ??
How can i add Arabic Language ??
use tacotron2 trained on russian?
first, thanks for such a complete pipeline.
second, would you integrate e.g. this repo for native russian support?
При запуске вне коллаба ошибка
OSError: [WinError 127] Не найдена указанная процедура. Error loading «C:\Users\admin\PycharmProjects\pythonProject\venv\lib\site-packages\torch\lib\caffe2_detectron_ops_gpu.dll» or one of its dependencies.
Пробовал разные методы и подходы, в общем ничего не помогает… Даже не знаю что и делать.
P.S. tensorflow-gpu поддерживается только до python-3.7, всё что выше будет писать ошибку что не нашло нужной версии.
Может кто сталкивался?
Training problem
First of all, thank you for sharing the open-source of Multi-Tacotron-Voice-Cloning. I also just started learning about natural language processing programming. And I also started learning Python programming.
-I put the software in the directory: D: \ SV2TTS
-I put the dataset in the directory: D: \ Datasets, I have D: \ Datasets \ book and D: \ Datasets \ LibriSpeech
When using the code you provided, I had some training issues:
- I have finished the steps
- Run python encoder_preprocess.py D: \ Datasets
and the result is
Arguments:
datasets_root: D: \ Datasets
out_dir: D: \ Datasets \ SV2TTS \ encoder
datasets: [‘preprocess_voxforge’]
skip_existing: False
Done preprocessing book.
- Run visdom
- But I could not continue
- Run python encoder_train.py my_run D: \ Datasets
because the notice appeared
C: \ Users \ Admin \ anaconda3 \ envs \ [Test_Voice] \ lib \ site-packages \ umap \ spectral.py: 4: NumbaDeprecationWarning: No direct replacement for ‘numba.targets’ available. Visit https://gitter.im/numba/numba-dev to request help. Thanks!
import numba.targets
usage: encoder_train.py [-h] [—clean_data_root CLEAN_DATA_ROOT]
[-m MODELS_DIR] [-v VIS_EVERY] [-u UMAP_EVERY]
[-s SAVE_EVERY] [-b BACKUP_EVERY] [-f]
[—visdom_server VISDOM_SERVER] [—no_visdom]
run_id
encoder_train.py: error: unrecognized arguments: D: \ Datasets
My question: How can I fix this problem?
Thanks again for your sharing!!!
Could not find a version
❯ python3 -m pip install -r requirements.txt
ERROR: Could not find a version that satisfies the requirement tensorflow-gpu<=1.14.0 (from -r requirements.txt (line 1)) (from versions: 2.2.0rc1, 2.2.0rc2, 2.2.0rc3, 2.2.0rc4, 2.2.0, 2.2.1, 2.3.0rc0, 2.3.0rc1, 2.3.0rc2, 2.3.0, 2.3.1)
ERROR: No matching distribution found for tensorflow-gpu<=1.14.0 (from -r requirements.txt (line 1))
❯ python --version
Python 3.8.5
Could not find a version that satisfies the requirement PyQt5
Could not find a version that satisfies the requirement PyQt5 (from -r requirements.txt (line 13)) (from ver
sions: )
No matching distribution found for PyQt5 (from -r requirements.txt (line 13))
Не видит dataset
Привет, у меня не видит dataset RU. LibriSpeech видит, а русский dataset не видит. Что делать? Спасибо
Recommend Projects
-

React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.