Вместо вступления.
Эта статья и её продолжение появились благодаря вопросам студентов на семинарах по СУБД. Каждый студент должен был выбрать тему для проектирования базы данных, реализовать полный цикл проектирования от логической и физической диаграммы в Oracle SQL Developer Data Modeler (SDDM) до работающей базы данных в СУБД Oracle с использованием APEX. Затем стать пользователем своей разработки: заполнить схему данными и написать аналитические запросы. Некоторые возможности SDDM оказались неочевидными и мы потратили полтора занятия, что бы рассмотреть самое необходимое.
Некоторым студентам, имеющим некоторый стихийно накопленный опыт разработки приложений с использованием СУБД, тяжело перестраиваться на анализ предметной области, трудно понять важность методик проектирования реляционной модели. Потому статья начнется с напоминания порядка разработки.
Не надо сразу делать таблицы. Порядок разработки следующий:
- анализ данных, процессов обработки информации и бизнес-правил, документирование собранной информации
- выявление и определение сущностей
- выявление, описание атрибутов сущностей, определение типов атрибутов
- выявление, описание и определение типов связей между сущностями
- создание матрицы связей и проверка идеи на прочность анализом матрицы связей, документирование бизнес-правил и ограничений
- создание логической диаграммы сущность-связь (ERD) в SDDM, в свойствах атрибутов и связей в том числе отражаются бизнес-правила и ограничения, те что не могут быть реализованы в СУБД описываются отдельным документом и реализуются на прикладном уровне триггерами
Статью готовил я, Присада Сергей Анатольевич, сейчас работаю в Финансовом университете при Правительстве РФ, почта sergey.prisada на яндексе.
Рассмотрим на некоторых абстрактных отношениях следующие возможности:
- Домены атрибутов.
- Глоссарий имен.
- Суррогатные (искусственные) первичные ключи.
- Комментарии к атрибутам. Комментарии к сущностям.
Задачи
- Создать домен атрибутов содержащий 4 значения (Value List).
- Создать 3 сущности, каждая с 4 атрибутами. В каждой сущности 1 атрибут использует домен значений. 2 атрибута обязательные, два не обязательные, один атрибут уникальный, но не первичный UID. Сущности используют суррогатные (искусственные) ключи, первичные ключи вручную не устанавливаем. Каждому атрибуту и сущности сделать комментарий для RDBMS.
- Создать связи между сущностями 1:N и в свойствах связей установить использование суррогатных ключей.
- Создать и применить глоссарий имен.
- Преобразовать в реляционную, затем в физическую модель. Изучить код, при наличии ошибок выяснить причину и устранить.
- Отобразить комментарии на диаграмме для улучшения читаемости.
1. Создать домен атрибутов с 4 значениями (Value List). Указать строковый тип и параметры типа.
Меню “Tools” – “Domains Administrator”

Домен атрибутов будет использоваться для создания ограничений значений стрибутов на уровне таблицы. Ограничения могут быть не только списком значений, но также ограничивать диапазоны численных данных, можно указать конкретные значения диапазона.
Создать список допустимых значений домена.

Домены атрибутов сохраняются в файл defaultdomains.xml в каталоге с настройками Oracle Data Modeler профиля пользователя, или в каталоге с установленной программой – зависит от операционной системы.
Файл с доменами атрибутов необходимо сохранить в каталоге с моделью с новым именем, подключить его в настройках и сохранить модель. Для этого открыть настройки доменов:
Меню “Tools” – “Domains Administrator”, выбрать файл

и сохранить

Для справки:
- домен это совокупность всех значений, которые может принимать атрибут сущности
- каждый атрибут может быть определен только одним доменом атрибутов
- каждый домен может определять множество атрибутов
- в понятие домен входит не только область значений домена, но и тип данных, диапазон значений
Примеры:
- домен «Имя» определен, тип строковые данные, перечень атрибутов «Иванов», «Петров», «Сидоров» как принадлежащие этому домену
- домен «Почтовый индекс», тип данных NUMBER длиной 6 символов
- домен «SMS to client», тип строковые данные длинной 100 символов
2. Создать 3 сущности, каждая с 4 атрибутами. В каждой сущности 1 атрибут использует домен значений. 2 атрибута обязательные, два не обязательные, один атрибут уникальный, но не первичный UID. Сущности используют суррогатные ключи, первичные ключи не устанавливаем. Каждому атрибуту и сущности сделать комментарий для RDBMS.
Первичные ключи указывать не нужно, только уникальные атрибуты в разделе “Uniaue Identifiers”.
Использование суррогатных ключей для сущности.

Домен атрибутов и комментарий к атрибуту, параметр Mandatory (обязательности) устанаваливаем у двух из четырех.

Комментарий в свойствах сущности. Он появится на логической диаграмме, отобразится в свойствах таблицы и будет создан в физической модели.

Первичных и уникальных ключей сами не создаем (пусто на вкладке)

Создать связи между сущностями 1:N и в свойствах связей установить использование суррогатных (Искусственных) ключей “Use surrogate keys”. Свойства связи: переносимость Transferable, обязательность Optional и кардинальность Cardinality выбираем какие угодно, это же пример.

3. Создать и применить глоссарий имён.
Использование глоссария облечает работу с правилами именования в модели данных. Имя сущности должно быть в единственном числе, производная из неё таблица во множественном. Имя атрибута может быть длинным и понятным при разработке, но имя производного столбца должно быть кратким для уменьшения кода и удобства работы с запросами. Как правило, для имени столбца используют аббревиатуру имени атрибута. Имя атрибута сущности для автоматически создаваемого первичного ключа будет состоять из имени сущности с добавлением “_id”. Также в Oracle Data Modelerотдельно есть настройки правил для формирования имён внешних ключей, составных первичных ключей, индексов, ограничений уникальности.
Глоссарий имён можно создать новый, но также можно создать шаблон из уже разработанной логической
Предварительно необходимо сделать настройки имён в свойствах Oracle Data Modeler.
В настройках в Oracle Data Modeler, убрать чек-бокс.

Создать глоссарий имен из готовой логической диаграммы. Сохранить его как файл в каталоге с моделью.

Глоссарий обязательно должен содержать множественную форму для имени каждой сущности и аббревиатуру для каждого атрибута. Большие глоссарии можно редактировать выгрузив их в таблицу Excel. Меню редактирования глоссария находится в меню “Tools” – “Glossary Editor”. Используйте глоссарий во множестве проектов, нарабатывайте его в своей практике.
Меню сохранения глоссария

В настройках модели подключить глоссарий.


И примените правила именования к логической модели.

Преобразовать в реляционную.

Результат преобразования будет содержать имена из глоссария, комментарии.

Преобразовать реляционную модель в физическую.

В диалоговом окне можно выбрать не только сохранение, но также вид конкретной СУБД в которой будет использоваться готовая модель. Напомню, что проектирование не зависит от физической реализации СУБД. Мы выберем СУБД Oracle последней доступной в планировщике версии.

В настройках генерации физической модели можно указать множество параметров, например выбрать только определенные объекты модели (например вы разработали только представления View). Обязательно установить чек-боксы как на картинке. Все подробности в документации.

Результат – DDL файл с инструкциями для создания схемы в базе данных. Внимательно изучите его, найдите все элементы, которые были созданы в логической диаграмме, при наличии ошибок выяснить причину и устранить. Например домены атрибутов, каким образом создаются ограничения и т.п.

Этот скрипт готов для импорта в базу данных.
4. Отображение комментариев.
Отображение комментариев в логической и реляционной моделях делает диаграммы более читаемыми во время работы.

При открытой логической диаграмме в меню Oracle Data Modeler включить в меню отображение комментариев.

5.Скачайте пример
Модель из статьи вы можете скачать по ссылке на Github: https://github.com/saprisada/odm
Изучите её как пример, создайте аналог, прочтите дополнительно документацию и примените знания в своём проекте.
It’s true, Oracle are giving away free stuff. “Oracle ?”, I hear you say, “as in Larry’s Database Emporium and Cloud base ?” The very same.
It’s been going on for quite a while and includes relatively hidden gems such as SQLDeveloper Data Modeler.
There is some confusion around this particular tool for a couple of reasons.
When it was first released (sometime around 2009 as I recall), Data Modeler was an additional cost option. However, that didn’t last long.
At present (and for a number of years now), it is available either as a completely standalone tool, or as a fully integrated component of the SQLDeveloper IDE.
Either way, it costs exactly the same as the SQLDeveloper IDE – i.e. nothing.
I can tell you like the price, want to take it for a spin ?
I’m going to focus here on using the integrated version of Data Modeler. This is because
- I want to use it for small-scale modelling of the type you might expect to find when using an Agile Methodology
- I’m a developer and don’t want to leave the comfort of my IDE if I don’t need to
What I’m going to cover is :
- Viewing a Table Relationship Diagram (TRD) for an existing database table
- Creating a Logical Data Model and Entity Relationship Diagram (ERD)
- Generating a physical model from a logical model
- Generating DDL from a Physical Model (including some scripting tweaks to suit your needs)
- Using a Reporting Schema and pre-canned SQLDeveloper Reports to explore your models
Disclaimer
This post is about introducing the features of Data Modeler in the hope that you may find them useful.
It’s not intended as a paragon of data modelling virtue.
Come to that, it’s not intended as a definitive guide on how to use this tool. I’m no expert with Data Modeler (as you are about to find out). Fortunately, there are people out there who are.
If, after reading this, you want to explore further, then you could do worse than checking out words of Data Modeler wisdom from :
- Heli Helskyaho
- Jeff Smith
Let’s get started…
The Model Tab
Say I’m connected to the database as HR and I’m looking at the DEPARTMENTS table.
I’d really like to see a TRD for this table.
The bad news is that the data model originally created when building the application fell into disuse long ago and is now hopelessly outdated.
The good news is that I’m using a recent version of SQLDeveloper ( 18.1, since you ask), so I just need to navigate to the DEPARTMENTS table in the tree, hit the Model Tab and wait a few seconds…

That’s Data Modeler doing it’s thing – in this case, reading information from the Data Dictionary and building the resulting diagram on the fly.
Note that, you may wait some time for the tab to initialize and then be greeted with an apparently empty space. I’ve found that this is especially true when looking at Fact tables in a star-schema.
The tables are there, just not where you can see them.
If you want to explore the diagram, tweak the layout, or even just export it to a file, you can click on the Copy to Data Modeler button :

Incidentally, if you do have a diagram where nothing is visible, you should now be able to use the Fit Screen button to make sure you can see everything.

You should then be able to drag objects around and amend the layout to suit your purposes.
Once you’re finished, if you’d like to save the diagram into a separate file, you can use the right-click menu and select Print Diagram :

Whilst it’s extremely useful to be able to generate an accurate and up-to-date TRD from the Data Dictionary, where Data Modeler comes into it’s own is when you want to …er…create a Data Model.
Creating a Data Model for a new Application
The traditional approach to Data Modelling was to create a full sized, complete model before moving on to write the rest of the application. The extended timelines for this approach may not be practical if you are following one of the Agile development methodologies. However, having a properly designed data model is rather important for an Application running on the Oracle platform.
We can go some way to squaring this circle by creating models for sub-sections of the application in one sprint for the developers to code against in the next sprint.
This is the context in which I imagine the modelling that follows to be taking place.
In this case, I’m using my trusty World Cup Wallchart application as the example. This is a “new” application rather than being an enhancement to an existing one.
The Entities I’ve identified at this point are :
- A COMPETITION is an international football competition, such as the World Cup or the Copa America
- A TOURNAMENT is an instance of a COMPETITION (e.g. Russia 2018 is a World Cup Finals Tournament).
- A TEAM is a competitior in international football and may compete in one or more TOURNAMENTs, such as Brazil in all World Cups or England (briefly) in some
Right, let’s get cracking then, starting with…
The Logical Model
The first challenge is to choose the correct Data Modeler sub-menu to open to start creating our model. There are three separate entries in the IDE – in the File menu, the View menu, and the Tools menu.
In this case, we want to open the Data Modeler Browser tree using View/Data Modeler/Browser

…which opens the browser in the left-hand pane.
Note – You can find Jeff Smith’s useful guide to the Integrated Data Modeler menus here.
If we expand the Untitled_1 node we can see some items which may be of interest…

We can now right-click the Logical Model node and select Show from the pop-up menu and we can see that a Diagram area, together with a widget toolbar appears…

We need to use the toolbar widgets to create our model objects.
The toolbar looks like this :

The widgets are :
- Select
- New Entity
- New View
- New M:N Relation
- New 1:N Relation
- New 1:N Relation Identifying
- New Type Substitution
- New Arc
- Add Foreign Key to Arc
- Remove Foreign Key from Arc
- New Note
- New Picture
- Delete
- Engineer to Relational Model
- Zoom in
- Zoom Out
- Fit Screen
- Default Size
- Search
For now, we’re going to click on New Entity and then click in the diagram area, which presents us with :

Our first Entity is COMPETITION. We specify this in the Name field in the General Tab.
Next we select Attributes section of the Entity Properties so that we can start specifying the COMPETITION attributes.

To add an attribute, simply click the green plus button in the Attributes toolbar that appears and then fill in the details.
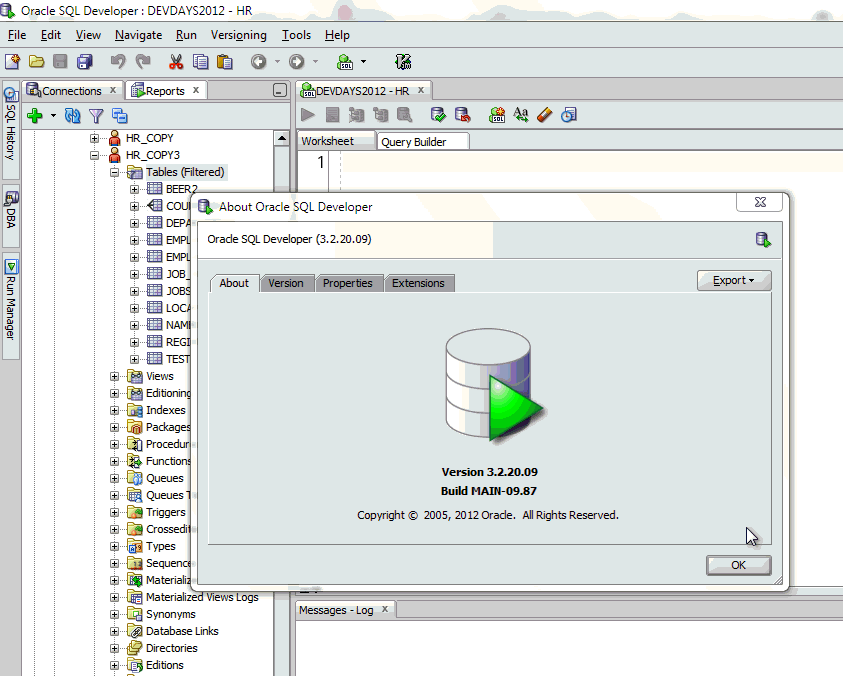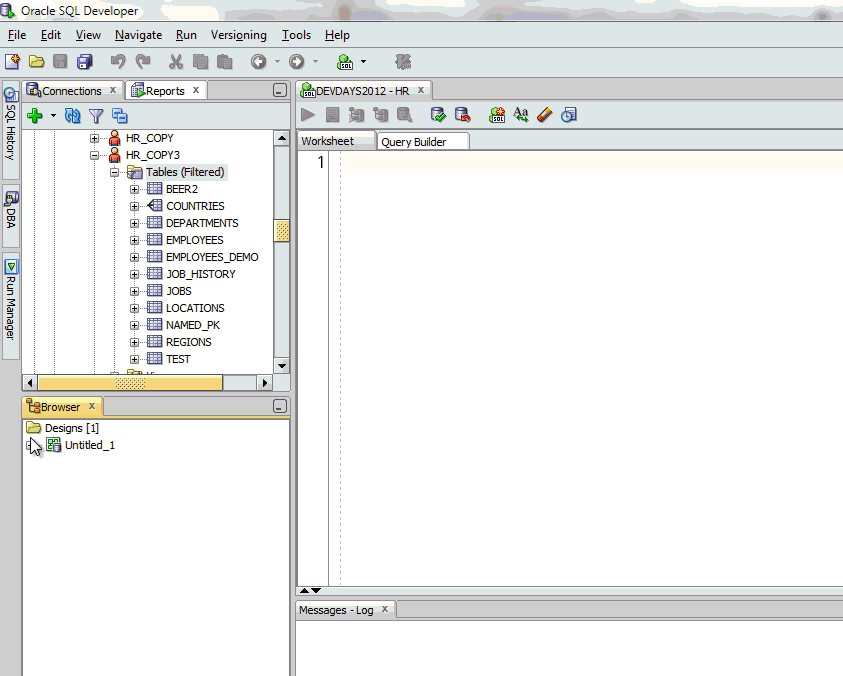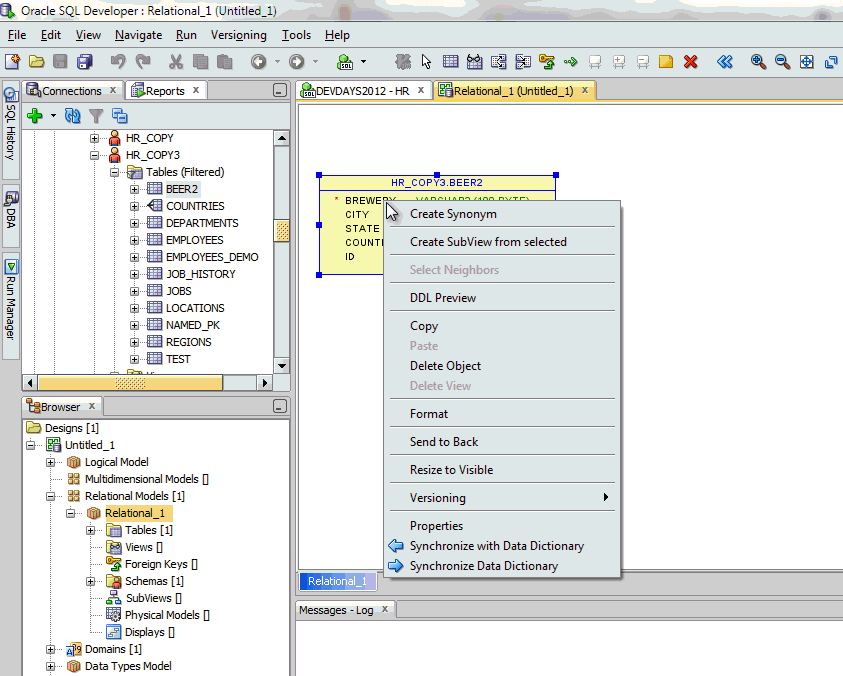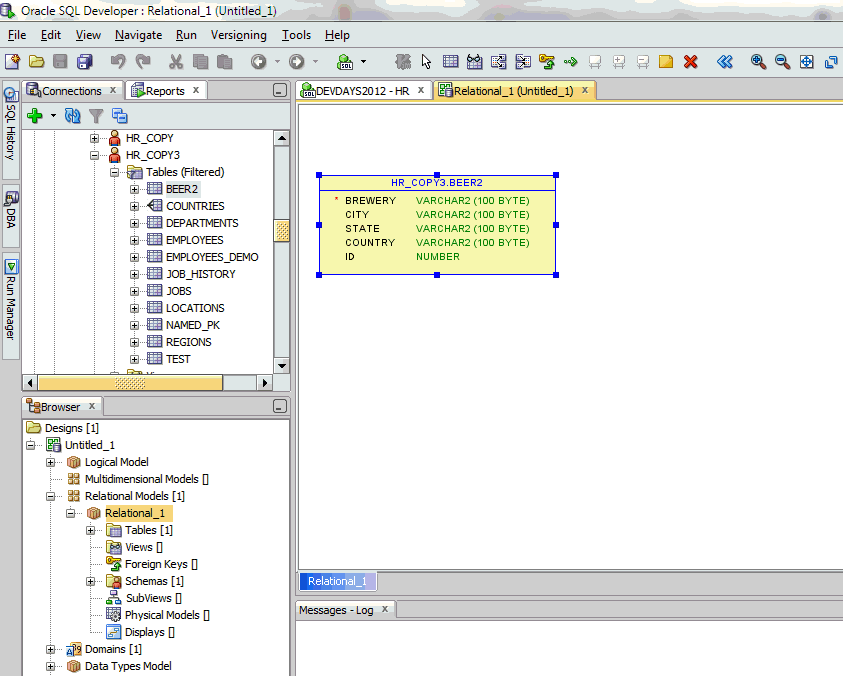
In this case, I’m adding a column called COMP_CID which is a VARCHAR with a maximum length of 25 characters.
The value in this column will uniquely identify an instance of a COMPETITION so I’ve ticked the Primary UID box.
I’ve also selected the Comments in RDBMS Tab and added a comment for what will ultimately become a column in the finished database table.
Finally, I’ve hit the Apply button and can now see this :

If we now navigate to the Unique Identifiers section we can see that a Primary Key has been created for us

Once we’ve returned to Attributes and added a few more, the finishing touch for this entity is to navigate to the Comments in RDBMS section.
This time, we’re entering comments for what will ultimately be the database table :

Once we’re finished, we can now see our finished entity in the diagram :

Having added the other Entities, our model now looks like this :

We can now save the design by going to the File menu and clicking Data Modeler/Save.
We need to save the design as a file with a .dmd extension.
Notice that once you’ve saved the file, the name of the Untitled_1 node in the Data Modeler browser changes to the base name of the file you’ve just created.
Notice also that at no point have we been connected to the database during the creation of our model.
In fact, it’s quite possible to progress from a Logical Model to a Physical model and even generate the DDL required to implement it without connecting to a database at any point.
However, SQLDeveloper does offer some useful Data Modeler reports which we can take advantage of if we decide to create a Reporting Schema.
Using a Reporting Schema
To start with, we need to create the Reporting Schema, in this case, DM_REPORT_REPOS :
set verify off accept passwd prompt 'Password for DM_REPORT_REPOS : ' hide create user dm_report_repos identified by &passwd / alter user dm_report_repos default tablespace users / alter user dm_report_repos quota unlimited on users /
Now we need to edit and run the Reporting_Schema_Permissions.sql script, which is located in the datamodeler\datamodeler\reports folder.
In my case, runninig on an Ubuntu client with SQLDeveloper installed in /opt/sqldeveloper181, the path to this script is :
/opt/sqldeveloper181/sqldeveloper/sqldeveloper/extensions/oracle.datamodeler/reports/Reporting_Schema_Permissions.sql
Before running the script, we need to edit the file to replace and with desired values:
- is the schema to hold the reporting repository (DM_REPORT_REPOS in this example)
- is a directory on the database server
Incidentally, I’ve also created a new directory on the Operating System so that when the script creates the directory object in the database, it will be pointing to an existing directory on the OS :
sudo su oracle mkdir /u01/app/oracle/dm_reports
With my changes, the script now looks like this :
CREATE OR REPLACE DIRECTORY OSDDM_REPORTS_DIR AS '/u01/app/oracle/dm_reports'; GRANT READ, WRITE ON DIRECTORY OSDDM_REPORTS_DIR TO dm_report_repos; GRANT CREATE SESSION TO dm_report_repos; GRANT RESOURCE TO dm_report_repos; GRANT CREATE TABLE TO dm_report_repos; GRANT CREATE SEQUENCE TO dm_report_repos; GRANT CREATE VIEW TO dm_report_repos; GRANT CREATE PROCEDURE TO dm_report_repos;
Once we’ve created the Repository schema and added a connection for it in SQLDeveloper, we can then report on our model.
In order to do this, we first need to export our model into the repository.
So, go to the File Menu and select Data Modeler/Export/To Reporting Schema.
You should be rewarded with :

Select the DM_REPORT_REPOS connection and hit OK. You should eventually get :

If the Reports Tree is not already visible, open it by selecting on View/Reports.
If you now expand the Data Modeler Reports node, you’ll see a number of pre-built reports available.
For example, I can see which of my Logical entities are missing relationships :

It’s probably worth remembering that, after you’ve made changes to your data model, you will need to export it again to the reporting repository for those changes to be reflected in the reports.
Anyway, it’s clear that we need to finish off our Logical model with some relations.
First, we create a 1:N relationship between COMPETITION and TOURNAMENT by clicking on the 1:N widget then clicking in the COMPETITION entity and then in the TOURNAMENT ENTITY.
Once the line appears on the diagram we can then name the relationship :

If we now go into the TOURNAMENTS entity properties, we can see that the COMP_CID column has been added automatically :

We can now also add it to the TOURNAMENTS existing Unique Key :

One final point to note is that, although it’s not yet apparent, we are going to have a Surrogate Key for TOURNAMENT :

Finally, we’re going to add a Many-to-Many ( M:N relationship) between TEAM and TOURNAMENT, which leaves our logical model looking like this :

Let’s see how smart Data Modeler is when we move on to…
Engineering a Relational Model from the Logical Model
With the Logical Model Diagram displayed, if we hit the Engineer to Relational Model button in the toolbar we’ll get this window :

Now hit the Engineer button and you should now see :

The main thing that jumps out when looking at this are :
- the layout could do with some work
- Tournament has had TOURNAMENT_ID column generated which is now it’s Primary Key
- a join table – tourn_team_mm – has been generated to resolve the many-to-many relationship
Using options on the right-click menu, or even just dragging objects around, you can adjust the diagram to be more to your liking.
In this case I’ve used the Layout/Resize Objects to Visible option as well so that we can see everything for each table :

Before we can turn this into physical database objects, we probably want to do a bit of tweaking…
Refining the Relational Model
Templates
First of all, we want to make some changes to our table and column names.
By convention, Entity names in a Logical model are singular, but once they become tables, they become plural.
This may not be a convention you necessarily feel obliged to follow, but it does give me the chance to demonstrate one method of changing this in the Data Modeler.
The other thing we want to do is to change column names which include a table name( e.g. the TOURNAMENT_ID column in the TOURNAMENT table), to use an abbreviation instead.
To do this, we first need to edit the template used to generate names for these objects.
In the Data Modeler Tree, right-click the Design and select Properties.
Expand the tree in the left-hand side of the pop-up window and you should get to the Templates :

Using the Add Variable buttons we can amend these templates to look something like this :

I’ve also specified abbreviations for each of the tables. For example :

In order to implement our improved object naming we need to right-click the relational model and then click Apply Naming Standards to Keys and Constraints

Hit OK and…

So, the TOURNAMENT_ID column has now been renamed to TOURN_ID. However, there are still some things that I’ll need to change manually ( probably because I haven’t figured out the proper way to do it).
Bear with me, I’ll be back in a minute…
Right, that’s better…

Now, let’s sort out those table names.
Transformation Scripts
First off, I’d like to make all of my table names uppercase.
One way of doing this, as described by Heli, is to use a pre-supplied transformation script.
To do this, go to the Tools menu and select Data Modeler/Design Rules and Transformations/Transformations.
Then simply select the appropriate script – in this case – Tables to upper case – Rhino and hit Apply.
The table names should now show in uppercase on this diagram.

I also wanted to pluralize the names ( e.g. COMPETITIONS rather than COMPETITION).
Whilst there are a number of ways to do this, we’re going to do a little light hacking to produce our own Transformation script to accomplish this.
So, back to the menu and select Tools/Data Modeler/Design Rules and Transformations/Transformations.
If I hit the Green Plus button, I can then add a script of my own.
Now, I know that my model contains table names which can all be pluralized simply by adding an “S”. I also know that this will not make any of the table names too long ( i.e. over 30 characters).
This makes the script fairly simple.
tables = model.getTableSet().toArray();
for (var t = 0; t<tables.length;t++){
table = tables[t];
name = table.getName()+"S"
table.setName(name);
table.setDirty(true);
}
I’ve named the script Append upper case ‘S’ to table names. I’ve also specified the object as relational and the engine as Oracle Nashorn.
Finally, I hit Save :

Now hit the Apply button and…

Table DDL Transformation Script
We’re almost ready to generate the DDL scripts to translate our Relational Model into a Physical one.
As I’m planning to use Editions in this application so I need to make sure that each table has an Editioning View created.
So, once more unto the Tools/Data Modeler/Design Rules and Transformations menu and this time we select Table DDL Transformation Scripts.
If we then navigate to the After Create scripts for the Journal Tables, we come across a script that we can plaigarise…
![]()
We need to create a new Script Set by clicking the Green Plus button, filling out some details and then, in the After Create section, adding the following code :
var ddl;
var lname;
//Editions Based Redefinition View suffix
ebrSuf = "#EBR";
prompt = model.getAppView().getSettings().isIncludePromptInDDL();
useSchema = model.getAppView().getSettings().isIncludeSchemaInDDL();
if(model.getStorageDesign().isOpen()){
if(useSchema){
lname = tableProxy.getLongName();
}else{
lname = tableProxy.getName();
}
}else{
if(useSchema){
lname = table.getLongName();
}else{
lname = table.getName();
}
}
if(prompt){
ddl= "PROMPT Creating Editioning View for '"+lname+"';\n";
}else{
ddl = "";
}
ddl = ddl + "create or replace editioning view "+lname+ebrSuf+" as select * from "+lname+";\n"
ddlStatementsList.add(new java.lang.String(ddl));
Finally, Save the new Script.

Now, we can test our script on a single table ( in this case COMPETITIONS), by clicking the Test button :

Generating DDL from a Relational Model
Let’s find out if our Relational Model is ready to go out into the big wide world.
With the Relational Model Diagram in focus, hit the Generate DDL toolbar button.

Now click Generate Button.
Go to Include Table DDL scripts tab and select our script from the drop-down and ensure all tables are checked

Click OK and…

We can see that Data Modeler has found a couple of errors. Taking a closer look at the script it’s generated we can find the culprits :

The easiest way to fix this is to edit the script directly before hitting Save.
At last, we have a script containing the DDL statements required to deploy our relational model to a real database.
Conclusion
I realise that this has not been so much a stroll through the well-kept garden as a hack through the undergrowth of Data Modeler in it’s integrated form.
Hopefully though, it’s enough for you to consider exploring further.
After all, a well-designed relational data model is the bedrock of a good Oracle Database Application and this is the tool that could well help you achieve this…and at minimal cost.
![]()
Back in 1993, I discovered that I could get paid money for doing fun stuff with computers.
Over the years, I’ve specialised in Oracle Databses as a developer, a DBA and sometimes, an architect.
It’s my evil alter-ego — The Antikyte — who writes a blog about my various technical adventures.
Yes, that is his Death Star parked in the Disabled Bay.
I currently live in the South-West of England with Deb, my long-suffering wife.
View all posts by mikesmithers
The Oracle SQL Developer family currently has two ‘SQL Developer’ branded products:
- Oracle SQL Developer
- Oracle SQL Developer Data Modeler
Oracle SQL Developer is the database IDE and Oracle SQL Developer Data Modeler is our dedicated data modeling solution. Where it gets interesting is that the entire Data Modeler product also runs inside of SQL Developer.
When I do demo’s of building quick ad hoc models in SQL Developer, I’m frequently asked to ‘back up’ and slowly demonstrate how to get started with a model in SQL Developer.
Here’s a quick animated GIF showing you the basics:
The Basic Steps
- View -> Data Modeler -> Browser
- Expand Browser tree and go to ‘Logical’ or ‘Relational’ models node
- Expand node and select default model
- Right click -> ‘Show’
You can also open an existing model by using the File -> Data Modeler -> Open/Recent Diagrams menus.
A Few Reminders
There’s no difference in the modeling technology between running it stand alone or inside of SQL Developer. The practical differences come down to the user interface, where you see the Data Modeler menu’ing system running under SQL Developer.
You can disable the modeler in SQL Developer (for quicker startup time and less complicated UI) by going to Tools > Preferences > Extensions and disabling ‘Oracle SQL Developer Data Modeler’ and ‘Oracle SQL Developer Data Modeler – Reports.’

I’m a Distinguished Product Manager at Oracle. My mission is to help you and your company be more efficient with our database tools.
An Introduction to Oracle SQL Developer Data Modeler
Oracle SQL Developer Data Modeler is a new graphical data modeling tool that facilitates and enhances communication between data architects
Data Modeler User’s Guide Release 4.1
September 2016. Provides conceptual and usage information about Oracle SQL. Developer Data Modeler a data modeling and database design tool that provides an
e
144011

http://www.oracle.com/technetwork/ http://www.oracle.com/technetwork/indexes/documentation/ boldfaceBoldface type indicates graphical user interface elements associated
with an action, or terms defined in text or the glossary.italicItalic type indicates book titles, emphasis, or placeholder variables for
which you supply particular values. monospaceMonospace type indicates commands within a paragraph, URLs, code in examples, text that appears on the screen, or text that you enter.
C:\ datamodeler datamodeler datamodeler64.exe datamodeler.exe
C:\Program Files\Java\jdk1.7.0_51
.dmd .dmd my_db_design
my_db_design.dmdmy_db_design businessinfo datatypes subviews logical entity subviews mapping pm rdbms rel 1 subviews table
dataflows pm Database design Logical model Relational model 1
Physical model 1a Physical model 1b . . . (other physical models) Relational model 2 Physical model 2a Physical model 2b . . . (other physical models) . . . (other relational models)
NOT NULL
SCOTT.EMP
EMP
CREATETABLE
CREATE INDEX
TBLS_ {model} TBLS_ datamodeler/reports datamodeler\reports
C:\ProgramFiles\datamodeler\datamodeler\reports
C:\saxon9.3\saxon9he.jar
http://saxon.sourceforge.net/ ȑhttp://msdn.microsoft.com/en-us/data/aa937724.aspxȑ http://www-01.ibm.com/software/data/db2/linux-unix-windows/downloads.html mumble.txt *.txt Problem Description (with bug ID if any):Fix Description: system3.1.0.678
C:\Documents and Settings\\Application Data\Oracle SQLDeveloper Data Modeler\system3.1.0.678
OSDDMW_DIAGRAMS
OSDDMW_DIAGRAMS
ȑC:/Windows/Fonts/Arial.ttf
ȑ/Library/Fonts/Arial Unicode.ttf
ȑ/usr/share/fonts/dejavu/DejaVuSans.ttf/usr/share/ fonts/truetype/dejavu/DejaVuSans.ttf datamodeler.conf datamodeler\datamodeler\bin sqldeveloper.confsqldeveloper\sqldeveloper\bin AddVMOption -Ddatamodeler.pdf.font=/usr/share/fonts/unifont.ttf
AllTablesDetails_1.html
AllTablesDetails_2.html
AllTablesDetails_1_rs.html
Reporting_Schema_Upgrade_readme.txt
datamodeler\datamodeler\reports
Reporting_Schema_Permissions.sql
datamodeler\datamodeler\reports dm_reporting_repos_conn datamodeler\datamodeler\reports\Reports_Info.txt _ http://subversion.tigris.org/ http://svnbook.red-bean.com/ branches
C:\designs
library
C:\designs\library
C:\designs\library
.dmd .dmd https://example.com/svn/designs/ branches branches branches branches library https://example.com/svn/designs/branches/library root/branches/library
C:\designs\library
datamodeler\datamodeler\types $ git init —bare local_des.gitD:/git-tests/bare_repo/local_des.Git/
D:/git-tests/bare_repo/local_des.git/
**/*.local files files gtest1 gtest1
Revert
Revert Commit
http://www.oracle.com/technetwork/developer-tools/sql-developer/ȑ http://www.omg.org/ http://www.omg.org/mof/ http://www.omg.org/spec/CWM/ http://coastguardinstructions.tpub.com/CI_5230_42A/
Person NameVARCHARSize: 25Address LineVARCHARSize: 40CityVARCHARSize: 25StateVARCHARSize: 2ZipVARCHARSize: 10Book IdVARCHARSize: 20Numeric IdNUMERICPrecision: 7, Scale: 0TitleVARCHARSize: 50
defaultdomains.xml datamodeler/domains datamodeler\domains defaultdomains.xml library_domains.xml book_idDomain: Book IdPrimary UID (unique identifier). (The Dewey code
or other book identifier.)titleDomain: TitleM (mandatory, that is, must not be null).author_last_nameDomain: Person
NameM (mandatory, that is, must not be null).author_first_nameDomain: Person Name(Author©s first name; not mandatory, but enter it if the author has a first name.)ratingLogical type:
NUMERIC
(Precision=2, Scale= 0)(Librarian©s personal rating of the book, from 1 (poor) to 10 (great).) patron_idDomain: Numeric IdPrimary UID (unique identifier). (Unique patron ID number, also called the library card number.)last_nameDomain: Person
NameM (mandatory, that is, must not be null). 25
characters maximum.first_nameDomain: Person Name(Patron©s first name.)street_addressDomain:
Address Line(Patron©s street address.)
cityDomain: City(City or town where the patron lives.)stateDomain: State(2-letter code for the state where the patron lives.)zipDomain: Zip(Postal code where the patron lives.)locationStructured type:
SDO_GEOMET
RYOracle Spatial and Graph geometry object
representing the patron©s geocoded address. transaction_idDomain: Numeric IdPrimary UID (unique identifier). (Unique transaction
ID number)transaction_dateLogical type:
DatetimeM (mandatory, that is, must not be null). Date and time of the transaction.transaction_typeDomain: Numeric IdM (mandatory, that is, must not be null). (Numeric code indicating the type of transaction, such as 1 for checking out a book.)
Library (relational)
create_library_objects.sql library_design.xml
SCOTT.EMP
EMP SQL> sqlplus user/password@name @script_name start_step stop_step log_file log_level jdbc:oracle:thin:scott/@localhost:1521:orcl thin oci8 createdByFKDiscoverer true
Columns_and_Comments
Foreign_Keys_All
SQL> sqlplus user/password@name @script_name start_step stop_step log_file log_levelȑ datamodeler\datamodeler\types\dl_settings.xml Table
Column
Entity
Attribute
Warning
Error http://jruby.org jruby.jar lib jruby.jar ext C:
C:\datamodeler\jdk\jre\lib\ext
loader loader pdf createdByFKDiscoverer true clone http://www.git-scm.com/documentation git-clone(1) https://www.kernel.org/pub/software/scm/git/docs/git-clone.html
Update
Create
http://www.oracle.com/technetwork/ http://www.oracle.com/technetwork/indexes/documentation/ boldfaceBoldface type indicates graphical user interface elements associated
with an action, or terms defined in text or the glossary.italicItalic type indicates book titles, emphasis, or placeholder variables for
which you supply particular values. monospaceMonospace type indicates commands within a paragraph, URLs, code in examples, text that appears on the screen, or text that you enter. C:\ datamodeler datamodeler datamodeler64.exe datamodeler.exe
C:\Program Files\Java\jdk1.7.0_51
.dmd .dmd my_db_design
my_db_design.dmdmy_db_design businessinfo datatypes subviews logical entity subviews mapping pm rdbms rel 1 subviews table
dataflows pm Database design Logical model Relational model 1
Physical model 1a Physical model 1b . . . (other physical models) Relational model 2 Physical model 2a Physical model 2b . . . (other physical models) . . . (other relational models)
NOT NULL
SCOTT.EMP
EMP
CREATETABLE
CREATE INDEX
TBLS_ {model} TBLS_ datamodeler/reports datamodeler\reports
C:\ProgramFiles\datamodeler\datamodeler\reports
C:\saxon9.3\saxon9he.jar
http://saxon.sourceforge.net/ ȑhttp://msdn.microsoft.com/en-us/data/aa937724.aspxȑ http://www-01.ibm.com/software/data/db2/linux-unix-windows/downloads.html mumble.txt *.txt Problem Description (with bug ID if any):Fix Description: system3.1.0.678
C:\Documents and Settings\\Application Data\Oracle SQLDeveloper Data Modeler\system3.1.0.678
OSDDMW_DIAGRAMS
OSDDMW_DIAGRAMS
ȑC:/Windows/Fonts/Arial.ttf
ȑ/Library/Fonts/Arial Unicode.ttf
ȑ/usr/share/fonts/dejavu/DejaVuSans.ttf/usr/share/ fonts/truetype/dejavu/DejaVuSans.ttf datamodeler.conf datamodeler\datamodeler\bin sqldeveloper.confsqldeveloper\sqldeveloper\bin AddVMOption -Ddatamodeler.pdf.font=/usr/share/fonts/unifont.ttf
AllTablesDetails_1.html
AllTablesDetails_2.html
AllTablesDetails_1_rs.html
Reporting_Schema_Upgrade_readme.txt
datamodeler\datamodeler\reports
Reporting_Schema_Permissions.sql
datamodeler\datamodeler\reports dm_reporting_repos_conn datamodeler\datamodeler\reports\Reports_Info.txt _ http://subversion.tigris.org/ http://svnbook.red-bean.com/ branches
C:\designs
library
C:\designs\library
C:\designs\library
.dmd .dmd https://example.com/svn/designs/ branches branches branches branches library https://example.com/svn/designs/branches/library root/branches/library
C:\designs\library
datamodeler\datamodeler\types $ git init —bare local_des.gitD:/git-tests/bare_repo/local_des.Git/
D:/git-tests/bare_repo/local_des.git/
**/*.local files files gtest1 gtest1
Revert
Revert Commit
http://www.oracle.com/technetwork/developer-tools/sql-developer/ȑ http://www.omg.org/ http://www.omg.org/mof/ http://www.omg.org/spec/CWM/ http://coastguardinstructions.tpub.com/CI_5230_42A/
Person NameVARCHARSize: 25Address LineVARCHARSize: 40CityVARCHARSize: 25StateVARCHARSize: 2ZipVARCHARSize: 10Book IdVARCHARSize: 20Numeric IdNUMERICPrecision: 7, Scale: 0TitleVARCHARSize: 50
defaultdomains.xml datamodeler/domains datamodeler\domains defaultdomains.xml library_domains.xml book_idDomain: Book IdPrimary UID (unique identifier). (The Dewey code
or other book identifier.)titleDomain: TitleM (mandatory, that is, must not be null).author_last_nameDomain: Person
NameM (mandatory, that is, must not be null).author_first_nameDomain: Person Name(Author©s first name; not mandatory, but enter it if the author has a first name.)ratingLogical type:
NUMERIC
(Precision=2, Scale= 0)(Librarian©s personal rating of the book, from 1 (poor) to 10 (great).) patron_idDomain: Numeric IdPrimary UID (unique identifier). (Unique patron ID number, also called the library card number.)last_nameDomain: Person
NameM (mandatory, that is, must not be null). 25
characters maximum.first_nameDomain: Person Name(Patron©s first name.)street_addressDomain:
Address Line(Patron©s street address.)
cityDomain: City(City or town where the patron lives.)stateDomain: State(2-letter code for the state where the patron lives.)zipDomain: Zip(Postal code where the patron lives.)locationStructured type:
SDO_GEOMET
RYOracle Spatial and Graph geometry object
representing the patron©s geocoded address. transaction_idDomain: Numeric IdPrimary UID (unique identifier). (Unique transaction
ID number)transaction_dateLogical type:
DatetimeM (mandatory, that is, must not be null). Date and time of the transaction.transaction_typeDomain: Numeric IdM (mandatory, that is, must not be null). (Numeric code indicating the type of transaction, such as 1 for checking out a book.)
Library (relational)
create_library_objects.sql library_design.xml
SCOTT.EMP
EMP SQL> sqlplus user/password@name @script_name start_step stop_step log_file log_level jdbc:oracle:thin:scott/@localhost:1521:orcl thin oci8 createdByFKDiscoverer true
Columns_and_Comments
Foreign_Keys_All
SQL> sqlplus user/password@name @script_name start_step stop_step log_file log_levelȑ datamodeler\datamodeler\types\dl_settings.xml Table
Column
Entity
Attribute
Warning
Error http://jruby.org jruby.jar lib jruby.jar ext C:
C:\datamodeler\jdk\jre\lib\ext
loader loader pdf createdByFKDiscoverer true clone http://www.git-scm.com/documentation git-clone(1) https://www.kernel.org/pub/software/scm/git/docs/git-clone.html
Update
Create
- oracle sql developer data modeler tutorial pdf
- oracle sql developer data modeler user’s guide
- oracle sql developer data modeler installation guide
- oracle sql developer data model tutorial
- oracle sql developer data modeler tutorial español
1.1 Installing and Getting Started with SQL Developer Data Modeler
To install and start SQL Developer Data Modeler, the process is similar to that for SQL Developer: you download a .zip file and unzip it into a desired parent directory or folder, and then type a command or double-click a file name. You should read any Data Modeler release notes or «readme» file before you perform the following steps.
- Unzip the Data Modeler kit into a directory (folder) of your choice. This directory location will be referred to as
<datamodeler_install>. For example, on a Windows system you might want to chooseC:\as this location.Unzipping the Data Modeler kit causes a directory named
datamodelerto be created under the<datamodeler_install>directory. It also causes many files and folders to be placed in and under that directory. - To start Data Modeler, go to the
datamodelerdirectory under the<datamodeler_install>directory, and do one of the following:On Linux and Mac OS X systems, run sh datamodeler.sh.
On Windows systems, double-click
datamodeler64.exe(Windows 64-bit systems) ordatamodeler.exe(Windows 32-bit systems).If you are asked to enter the full pathname for the JDK, click Browse and find it. For example, on a Windows system the path might have a name similar to
C:\Program Files\Java\jdk1.7.0_51 - If you want to become familiar with data modeling concepts before using the interface, read the rest of this chapter before proceeding to the next step.
- Do the short tutorial in Data Modeler Tutorial: Modeling for a Small Database. (For more advanced tutorials and other materials, see For More Information About Data Modeling.)
1.2 Data Modeler User Interface
The Data Modeler window generally uses the left side for navigation to find and select objects, and the right side to display information about selected objects.
Figure 1-1 shows the main window.
The menus at the top contain some standard entries, plus entries for features specific to Data Modeler (see Menus for Data Modeler), as shown in the following figure.
You can use shortcut keys to access menus and menu items: for example Alt+F for the File menu and Alt+E for the Edit menu; or Alt+H, then Alt+S for Help, then Search. You can also display the File menu by pressing the F10 key.
Icons under the menus perform actions relevant to what is currently selected for display on the right side of the window, such as the logical model, a relational model, or a data flow diagram. For example, for a relational model the icons include New Table, New View, Split Table, Merge Tables, New FK Relation, Generate DDL, Synchronize Model with Data Dictionary, and Synchronize Data Dictionary with Model. To see the name of any icon, hover the pointer over the icon. The actions for the icons are also available from the Object menu.
The left side of the Data Modeler window has an object browser with a hierarchical tree display for data modeling objects, as shown in the following figure.
To select an object in the object browser, expand the appropriate tree node or nodes, then click the object.
The right side of the Data Modeler window has tabs and panes for objects that you select or open, as shown in the following figure, which displays information about a deliberately oversimplified relational model for library-related data (the model developed in Data Modeler Tutorial: Modeling for a Small Database).
To switch among objects, click the desired tabs; to close a tab, click the X in the tab. If you make changes to an object and click the X, you are asked if you want to save the changes.
Related Topics
Menus for Data Modeler
Context Menus
Data Modeler
Data Modeler Concepts and Usage
Data Modeler Tutorial: Modeling for a Small Database
1.2.1 Menus for Data Modeler
This topic explains menu items that are of special interest for Data Modeler .
File menu
Open: Opens a Data Modeler design that had been saved or exported. For more information, see Saving, Opening, Exporting, and Importing Designs.
Close: Closes the current design without exiting Data Modeler.
Close All: Closes all open designs without exiting Data Modeler.
Import: Lets you import models from a variety of sources. For more information, see Saving, Opening, Exporting, and Importing Designs.
Export: Lets you export models to files that can be imported into a variety of data modeling tools. For more information, see Saving, Opening, Exporting, and Importing Designs.
Reports: Lets you generate Data Modeler Reports.
Page Setup: Displays a dialog box where you can specify the following for any diagram print operations: media Size (Letter, Legal, or other predefined size) and Source (Automatically Select or a specified paper source), Orientation (Portrait, Landscape, Reverse Portrait, Reverse Landscape), and Margins (left, right, top, bottom).
Print: Prints the currently selected diagram.
Print Diagram: Saves the currently selected diagram to an image file of the type associated with the file extension that you specify (.png or.jpg), to a PDF file, to a scalable vector graphics (.svg) file, or to an HTML/SVG (.html) file.
Recent Designs: Lets you open a Data Modeler design that you recently worked on.
Exit: Closes any open designs and exits Data Modeler.
Edit menu
Contains standard Edit menu options related to cutting, copying, pasting, deleting, aligning, and finding objects.
View menu
Contains options that affect what is displayed in the Data Modeler interface.
Show Status Bar: Toggles the displaying of the status bar at the bottom of the Data Modeler window.
Browser: Displays the object browser, which shows data modeling objects in a hierarchical tree format.
Navigator: Displays a graphical thumbnail representation of the view that is currently selected. The Navigator appears by default in the right side of the window.
Log: Displays the Messages — Log pane with a record of Data Modeler actions during the current invocation.
External Log: Displays a separate window with a record of all invocations of Data Modeler for the current full release number.
External Log: Displays a record of Data Modeler actions in an external viewer instead of in a pane within the Data Modeler window.
Files: Displays the Files pane for navigating the local file system.
Logical Diagram Notation: Controls whether Barker or Bachman notation is used to display the logical model.
View Details: Controls the level of detail in displays. Including Comments causes any Comments in RDBMS text to appear diagram displays for the logical model (entities and attributes) and relational models (tables and columns).
DDL Preview (relational diagram objects): Shows the DDL statements that would be generated to create the object. (When the DDL Preview window is displayed, you can click on other objects in the relational diagram to see the DDL statements that would be generated to create those objects.)
DDL File Editor: Lets you generate DDL statements for a selected physical model. Displays the DDL File Editor dialog box. (This command is equivalent to clicking the Generate DDL icon, or clicking File, then Export, then DDL File.)
Zoom In (and corresponding icon): Displays more detail, and potentially fewer objects, in the currently selected diagram.
Zoom Out (and corresponding icon): Displays less detail, and potentially more objects, in the currently selected diagram.
Fit Screen (and corresponding icon): Makes all relevant objects fit in the window for the currently selected diagram, adjusting the sizes of shapes and text labels as needed.
Default Size (and corresponding icon): Adjusts the shapes and text labels in the currently selected diagram to the default sizes.
Find (Search) Displays a dialog box for finding objects in the currently selected diagram. Useful for finding objects in large, complex diagrams. (See Find Object (Search).)
Note:
To do a global search across all open models, use the search (binoculars icon) box in the top-right area of the window.
Refresh: Updates the contents of the Data Modeler window to reflect current information.
Full Screen: Lets you toggle between a full-screen view of the Data Modeler window and the current or most recent non-full-screen view.
Team menu
Contains options related to support for the Subversion version management and source control system. See Using Versioning for more information.
Versions: Lets you display the Versions Navigator and the Pending Changes window.
The other commands on the Team menu depend on which version management and source control systems are available for use with Data Modeler.
Tools menu
Invokes Data Modeler tools and lets you set certain options (user preferences).
Domains Administration: Lets you view, modify, add, and delete domains. Displays the Domains Administration dialog box.
Types Administration: Lets you view, modify, add, and delete logical types. Displays the Types Administration dialog box.
RDBMS Site Administration: Lets you view RDBMS sites (names associated with supported types of databases), and to add your own names (aliases) for convenience in creating physical models. Displays the RDBMS Site Editor dialog box.
Mask Templates Administration: Lets you create one or more «templates» that you can then associate with appropriate columns in tables in a relational model. Displays the Mask Templates Administration dialog box.
Table to View Wizard: Lets you create views based on tables in a selected relational model. Displays the Table to View wizard.
View to Table Wizard: Lets you create tables based on views in a selected relational model. Displays the View to Table wizard.
Name Abbreviations: Specifies a .csv file with strings to be changed in names of relational model objects (for example, to ensure the use of standard abbreviations or spellings). Displays the Name Abbreviations dialog box.
Glossary Editor: Lets you create a new glossary file (if you specify a file name that does not exist) or edit an existing glossary file. Displays a file selection dialog box, and then the Glossary Editor dialog box.
Object Names Administration: Lets you make the names of specified objects fixed (unchangeable) or changeable in dialog boxes for the properties of the objects. Displays the Object Names Administration dialog box.
Design Rules: Lets you check your current design for violations of Data Modeler design rules. Displays the Design Rules dialog box.
Engineering Status: Displays the Engineering dialog box.
Compare/Merge Models: Lets you open a design file, compare a relational model from the file with a relational model in the current design, and merge objects from one model into the other. After you select the design file, the Relational Models dialog box is displayed.
General Options: Lets you customize the behavior of Data Modeler. Displays the Data Modeler dialog box.
Help Menu
Displays help about Data Modeler. The Help Center window includes the following icons in each tab:
-
Keep on Top: Toggles whether to keep the Help Center window on top of the Data Modeler window.
-
Navigators: Lets you select the Contents or Favorites navigator.
-
Print: Prints the topic.
-
Change Font Size: Lets you increase or decrease the font size for the display of the current help topic.
-
Add to Favorites: Adds the topic to the list in the Favorites navigator.
-
Find: Lets you search for a string in the current help topic.
Search: Displays the Help Center window, with focus in the Search (binoculars icon) box. You can enter one or more strings to be searched for in the online help.
Table of Contents: Displays the Help Center window, with the Contents tab selected.
Start Page: Displays a page with links for options for learning about Data Modeler. The options include a link to a page with Sample Models and Scripts.
Release Notes: Displays important information this release of Data Modeler, including requirements and some usage notes.
About: Displays version-related and other information about Data Modeler, its properties, and installed extensions.
1.2.2 Context Menus
The context menus (right-click menus) in the object browser and diagrams contain commands relevant for the object or objects selected.
In the object browser, if you right-click the logical model or a relational model, the context menu generally includes the following:
-
Change Subview Object Names Prefix: Specifies the new prefix to replace a specified current prefix for selected types of objects. Displays the Change Subview Object Names Prefix dialog box.
-
Apply Custom Transformation Scripts: Displays the Custom Transformation Scripts dialog box, where you can select scripts to be applied. (For more information about custom transformation scripts, see Transformations.)
-
Discover Foreign Keys: Lets you discover foreign key relationships among tables in the relational model, and to create foreign keys. (See Create Discovered Foreign Keys.)
-
Engineer to Relational Model (with the logical model selected): Performs forward engineering: generates or updates a relational model from the logical model. You can also specify if the operation creates a subview.
-
Engineer to Logical Model (with a relational model selected): Performs reverse engineering: updates the logical model from the selected relational model.
In diagrams, if you right-click outside any displayed object, the context menu generally includes the following:
-
Create Discovered Foreign Keys (relational model) Displays discovered hidden foreign key relationships in a relational model. (See Create Discovered Foreign Keys.)
-
Remove Discovered Foreign Keys (relational model): Removes any discovered foreign keys from the relational model diagram.
-
Create Subview: Creates a subview. (See also Logical Diagram and Subviews and Relational Diagram and Subviews.)
-
Create Display: Creates a separate display pane of the view or subview. Displays enable you to represent the same set of objects in different ways. For example, you can create a display, select it, and then experiment with changing the context-menu settings for View Details, Show (Grid, Page Grid, Labels, Legend), and Diagram Color.Displays are in the same window together with related main diagram or subview; however, you can find tabs for displays at the bottom of that window. To remove a display, right-click in it and select Delete Display.
-
Auto Route: Toggles the setting of the Line Auto Route option (see Diagram under Data Modeler). You must disable Auto Route before you can adjust lines in diagrams, such as clicking and dragging edges and elbows (vertices) to move them, or Ctrl+clicking and dragging on an edge to create a new elbow. Note: If you then enable Auto Route, any manual adjustments are lost.
-
Straighten Lines (available only if Auto Route is disabled): Removes any elbows so that the line connects only the start and end points.
-
AutoLayout (relational and data flow diagrams): Rearranges the objects in the diagram to a layout that may be more meaningful and attractive. If you do not like the rearrangement, you can restore the previous layout by clicking Edit, then Undo AutoLayout.
-
View Details: Lets you view all available details for objects or only selected details.
-
Show: Grid displays a grid in the background, which can help you to align objects vertically and horizontally on the diagram; Page Grid displays where page margins will be in printed PDF output; Labels displays the foreign key names on relationship arrows and the flow names on flow lines in data flow diagrams; Legend displays a legend box (which you can drag to move) containing the diagram name, author, creation date, and other information.
-
Resize Objects to Visible: Resizes objects in the diagram so that all are visible in the display area.
-
Diagram Color: Displays a dialog box for selecting the color scheme for the background on diagrams.
-
Properties: Displays the dialog box for viewing and editing properties of the model.
In diagrams, if you right-click a line connecting two objects, the context menu generally includes the following:
-
Delete: Removes the line and deletes the relationship represented by the line.
-
Straighten Lines (available only if Auto Route is disabled): Removes any elbows so that the line connects only the start and end points.
-
Format: Lets you change the width and color of the line.
-
Add Elbow (available only if Auto Route is disabled): Adds an elbow (vertex) at the selected point.
-
Remove Elbow (available only if Auto Route is disabled): Removes the selected elbow (vertex).
-
Properties: Displays the dialog box for viewing and editing properties of the relationship represented by the line.
In the logical and relational diagrams, if you select one or more entities or tables and right-click one of them, the context menu includes at least the following:
-
Create Synonym: Creates a synonym object in the display.
-
Create Subview from Selected: Creates a subview containing the selected objects. (See also Logical Diagram and Subviews and Relational Diagram and Subviews.)
-
Select Neighbors: Selects objects that are related to the selected object or objects. You can specify the selection direction: All (higher- and lower-level zones), Parent, or Child. You may want to select neighbors before creating a subview from the selection.
-
DDL Preview (relational diagrams): Shows the DDL statement that would be generated to create the object. (When the DDL Preview window is displayed, you can click on other objects in the relational diagram to see the DDL statements that would be generated to create those objects.)
-
Format: Lets you specify colors and fonts for the selected objects.
-
Show/Hide Elements: Lets you hide specified elements in the display.
-
Send to Back: Sends the selected objects to the back of the diagram display, which may cause them to be partially or completely covered by other objects.
-
Properties: Displays the dialog box for viewing and editing properties of the object.
In data flow diagrams, if you select one or more objects and right-click one of them, the context menu includes at least the following:
-
Delete: Deletes the selected object.
-
Format: Lets you specify colors and fonts for the selected objects.
-
Send to Back (for objects not represented by lines): Sends the selected objects to the back of the diagram display, which may cause them to be partly or completely covered by other objects.
-
Properties: Displays the dialog box for viewing and editing properties of the object.
1.3 Working with Data Modeler
You can use Data Modeler to create, edit, and delete objects at different hierarchy levels in different kinds of models. Many objects have similar properties, and the methods for performing operations are usually consistent and intuitive. To perform operations on objects (create, edit, delete), you can often use the context menu in the object browser or the toolbar or the Object menu after selecting a diagram.
-
To perform an operation on an object using the object browser, right-click the appropriate node (or click the node and press Shift+f10) in the hierarchy, and select the command for the desired operation.
For example, to edit an entity, expand the Logical display so that all entities are visible, right-click the name of the entity to be edited, and select Properties.
-
To perform an operation using a diagram, select the tab for the diagram, and use the toolbar icons.
For example, to create an entity, select the Logical tab; click the New Entity toolbar icon; then define the entity in the Entity Properties box. To edit an entity, either double-click its box in the diagram or right-click the box and select Properties.
Context Menus (right-click menus) in diagrams contain commands relevant for either the diagram generally or the object or objects currently selected.
For conceptual and usage information about specific kinds of objects, see the following topics:
-
Database Design
-
Data Types Model
-
Process Model
-
Logical Model
-
Relational Models
-
Physical Models
-
Business Information
1.3.1 Database Design
Data Modeler works with one open database design, consisting of one logical model, optionally one or more relational models based on the logical model, and optionally one or more physical models based on each relational model. The database design can also include a data types model, and business information. To work on another database design, close the current design (click File, then Close), and create or import objects for the other database design.
When you save a database design, the structural information is stored in an XML file (with the extension .dmd) in a folder or directory that you specify, and subfolders or subdirectories are created as needed under it. The .dmd file contains pointers to information in these subfolders or subdirectories. For example, for a very basic design named my_db_design, the following hierarchy might be created starting at the folder or directory in which you created it:
my_db_design.dmd
my_db_design
businessinfo
datatypes
subviews
logical
entity
subviews
mapping
pm
rdbms
rel
1
subviews
table
Additional subfolders or directories may be automatically created later, for example, dataflows under pm if you create any data flow diagrams in the process model.
Related Topics
Working with Data Modeler
Data Modeler Concepts and Usage
1.3.2 Data Types Model
Data Modeler supports supertypes and subtypes in its logical model, but it also provides the data types model, to be CWM (Common Warehouse Metamodel) compliant and to allow modeling of SQL99 structured types, which can be used in the logical model and in relational models as data types.
Structured types are supported as named user-defined composite types with the possibility of building a supertype/subtypes inheritance hierarchy. You can create and visualize structured types and the inheritance hierarchies of structured types, defining distinct and collection (array) types.
Both logical and relational models can use definitions from the data types model to specify the data type for attributes and columns or to define that a table (entity) is of a certain structured type.
You can build the data types model in one or more of the following ways:
-
Manually in Data Modeler
-
By importing from Oracle Designer repository. See Importing an Oracle Designer Model.
The data types model in Data Modeler combines two kinds of data:
-
One data types diagram, plus an optional set of subviews and auxiliary displays, each associated with the appropriate diagram/subview
-
Data type object definitions
Subviews are considered as independent diagrams of the data types model, created to represent different subject areas.
The data types model enables you to create and manage object definitions of distinct, structured, collection, and logical types.
All data type model objects (except logical types) are displayed in the object browser tree, but only structured type objects and their interrelations are represented graphically on data types diagrams.
1.3.2.1 Data Types Diagram and Subviews
The data types diagram contains graphical representations of structured data types and links between them, as shown in the following figure.
A structured type box contains the name of the object, its defined attributes, and its methods (if any). Diagram links represent various kinds of attributes with a structured data type.
When you are working with a complicated data types model, you may want to create subviews, with each subview describing only a section of that model. You can define several data types subviews for a single data types model, and you can assign a structured type to more than one subview. However, links (references) between two structured types are displayed on the complete data types model and only on subviews to which both types have been assigned.
There is no difference between performing changes in a subview or in the complete data types model. Any changes made are immediately reflected in the complete model and any relevant subviews. However, you can remove a structured type from a subview without deleting it from the data types model.
1.3.2.2 Distinct Types
A user-defined distinct type is a data type derived from an existing logical type, defined in Types Administration dialog box. A distinct type shares its representation with an existing type (the source type), but is considered to be a separate and incompatible type.
A distinct type object can be accessed only in the Distinct Types subfolder of the Data Types folder.
You can create new distinct types or edit the properties of existing distinct types.
1.3.2.3 Structured Types
Structured types are user-defined data types that have attributes and methods. They also can be part of a supertype and subtype inheritance hierarchy. A structured type can be defined based on a basic data type, a distinct type, another structured type, or a reference to structured type, or it can be defined as a collection type.
A table or entity can be defined as based on a structured type. Type substitution enables you to describe (graphically on a diagram) instances of which subtypes can be accommodated by the table (entity).
Table column or entity attributes can be defined as based on a structured type, a reference to structured type, a collection type, a distinct type, and basic data types. Type substitution can be defined for a column based on a structured type, and a scope table can be defined for a column based on a reference to a structured type.
A structured type also includes a set of method specifications. Methods enable you to define behaviors for structured types. Like user-defined functions (UDFs), methods are routines that extend SQL. In the case of methods, however, the behavior is integrated solely with a particular structured type.
The expanded structured types subfolder lists all structured type objects, with the hierarchy of attributes and methods for each.
The Oracle Spatial and Graph SDO_GEOMETRY type is predefined as a structured type. In addition, you can create new structured types or edit the properties of existing structured types.
1.3.2.4 Collection Types
Collection types represent arrays or collections of elements (basic type, distinct type, structured type, or another collection) and are mapped to the Oracle VARRAY and nested table types.
You can create new collection types or edit the properties of existing collection types.
1.3.2.5 Logical Types
Logical types are not actual data types, but names that can be associated with native types or with domains. The presupplied logical types include several from Oracle Multimedia (names starting with ORD); however, ORDIMAGE_SIGNATURE is deprecated and should not be used for new definitions.
You can create logical types and edit their mappings to native types (see Types Administration), and you can associate a domain with a logical type (see Domains Administration).
Related Topics
Working with Data Modeler
Data Modeler Concepts and Usage
1.3.3 Process Model
The process model represents a functional area of an information structures system. The process model, embodied graphically in one or more data flow diagrams, is an analysis technique used to capture the flow of inputs through a system (or group of processes) to their resulting output. The model shows the flow of information through a system, which can be an existing system or a proposed system.
All necessary elements for data flow diagramming are supported in the Data Modeler process model: primitive processes, composite processes with unlimited levels of decomposition, reusable transformation tasks, triggering events, information stores, external agents, record structure for describing external data elements, source-target mapping of data elements, and CRUD (create, read, update, delete) dependencies between primitive process and data elements.
The following are important concepts for the process model:
-
A process is an activity or a function that is performed for some specific reason. Ultimately each process should perform only one activity.
A primitive process is a standalone process.
A composite process consists of multiple outer processes. The data flow model allows you to drill down to child processes through a composite process. This means that a top-level process can drill down to another full data flow model.
-
A trigger is something that happens which initiates the execution of a process.
-
A data flow reflects the movement of single piece of data or logical collection of information. Flows describe the sequence of a data flow diagram. (For more information, see Data Flow Diagrams.)
-
A data store is a collection of data that is permanently stored.
-
An external agent is a person, organization, or system that is external to the system but interacts with it. External agents send information to and receive information from processes.
-
An information store is a passive object that receives or stores information as entities and attributes in the data model. Ultimately, an information store corresponds with one or more entities of the data model.
-
A transformation task, including input and output parameters, is an execution unit that communicates with surrounding environment that will execute it. An input parameter might be a date for which processing should be done. An output parameter might be a code that indicates whether the operation was successful or not. Transformation itself might involve reading, transforming, and saving information, some of which may not be directly tied to the input and output parameters. (For more information, see Transformation Processes and Packages.)
-
A role is a set of defined privileges and permissions. Primitive processes connected to information stores (processes that create, read, update, and delete data elements) can be attached to a defined role, thus defining collaboration between roles and data elements. Later, role definitions can be transferred to any particular physical model such that appropriate database roles with defined Select, Insert, and Update permission will be created.
1.3.3.1 Data Flow Diagrams
A formal, structured analysis approach employs the data flow diagram (DFD) to assist in the functional decomposition process. A data flow diagram consists of the following components:
-
External interactors, which are represented by rectangles
-
Data stores, which are represented by open rectangles (two or three sides)
-
Processes, which are represented by any rounded object (circle, oval, or square with rounded corners)
A process can represent a system function at one of various levels, from atomic through aggregate.
-
Data flows, which are represented by arrows, and optionally with labels indicating their content.
1.3.3.2 Transformation Processes and Packages
In a general data flow diagram, you may want to extract data from external sources and then transform the data before loading the it into the target store or database. You can build transformation packages for use with transformation processes.
For a transformation process, you need to create one or more transformation tasks in a transformation package. After you have the transformation task, you can include that in the main transformation process.
A transformation package is a package as defined in the Object Management Group (OMG) Common Warehouse Metamodel™ (CWM™) Specification, V1.1. This specification introduces transformation packages as follows:
«A key aspect of data warehousing is to extract, transform, and load data from operational resources to a data warehouse or data mart for analysis. Extraction, transformation, and loading can all be characterized as transformations. In fact, whenever data needs to be converted from one form to another in data warehousing, whether for storage, retrieval, or presentation purposes, transformations are involved. Transformation, therefore, is central to data warehousing.
«The Transformation package contains classes and associations that represent common transformation metadata used in data warehousing. It covers basic transformations among all types of data sources and targets: object-oriented, relational, record, multidimensional, XML, OLAP (On-Line Analytical Processing), and data mining.
«The Transformation package is designed to enable interchange of common metadata about transformation tools and activities.»
1.3.4 Logical Model
At the core of Data Modeler is the logical model (also called the entity-relationship diagram). It provides an implementation-independent view of enterprise information and acts as the mediator that maps definitions in the dimensional and process models to different physical implementations. A logical model, or a part of it (subject area, subview), can be transformed to one or more relational models.
You can build the logical model in any of the following ways:
-
Manually in Data Modeler
-
By importing models from a VAR file, such as those created by at least these versions of the following products: Sterling COOL:DBA V2.1 or Sterling Bsnteam V7.2, Cayenne Bsnteam V7.2
-
By importing an existing model created by Data Modeler
-
By reverse engineering from an imported relational model
The logical model combines two kinds of data:
-
One logical diagram, plus an optional set of subviews and auxiliary displays, each associated with the appropriate diagram or subview
-
Logical model object definitions
Subviews are considered as independent diagrams of the logical model, created to represent different subject areas.
The logical model enables you to create and manage object definitions for entities, logical views, attributes, unique identifiers, inheritances, relations, and arcs.
All logical model objects are displayed in the object browser tree.
1.3.4.1 Logical Diagram and Subviews
The logical model diagram contains graphical representations of entities, views, and links (relations and inheritances) between them.
When you are working with a complex logical model, you may want to create subviews, each describing only a section of that model. You can define several logical subviews for a single logical model, and you can assign entities and views to more than one subview. Links (relations) between two entities are displayed on the complete logical model and on logical subviews to which both referenced entities have been assigned.
There is no difference between performing changes in one of the subviews or in the complete logical model. Any changes made are immediately reflected in the complete logical model and any relevant subviews. However, you can remove entities and views from a subview without deleting them from the complete logical model.
To create a subview containing specific entities, you can select the desired entities in the logical model diagram, right-click, and select Create Subview from Selected. You can also right-click in the subview and select Add/Remove Elements to add objects to the subview and remove objects from the subview (using the Add/Remove Objects dialog box).
Diagraming Notation
Data Modeler supports the following alternatives for logical model diagramming notation:
-
Bachman notation
-
Barker notation
Detailed explanations and examples of each notation style are widely available in textbooks and on the Web. You can set the default notation type for new logical diagrams in the Data Modeler (General Options, Diagram, Logical).
To switch from one notation type to the other (and to see the differences for a diagram), select the logical model diagram and click View, then Logical Model Notation, then the notation that is not the current one.
1.3.4.2 Entities
An entity is an object or concept about which you want to store information. The structure of entity can be defined as collection of attributes or as based on structured type from the data types model. An entity may have candidate unique identifiers, one of which can be defined as primary unique identifier. Usually, an entity is mapped to table in the relational model.
1.3.4.3 Attributes
A data attribute (property, data element, field) is a characteristic common to a particular entity. The data type of an attribute can be based on a logical data type, a domain, a distinct type, a collection type, or a structured type, or it can be a reference to structured type. If it a reference to a structured type, a scope entity can be defined. An attribute is mapped to a column in the relational model.
1.3.4.4 Unique Identifiers (UIDs)
An entity unique identifier can be composed of one or more attributes. For each entity, you can define one primary unique identifier that uniquely identifies each entity occurrence. You can also specify one or more foreign unique identifiers, each of which points to (that is, must contain a value found in) a unique identifier in another entity.
1.3.4.5 Inheritances
Inheritance defines a hierarchy of entities based on supertypes and subtypes. The supertype and subtype entities represent part of a system that has a recognizable subset of occurrences of an existing entity type. The subsets are referred to as entity subtypes, with the original entity type being the supertype.
All attributes and relationships of the supertype must belong to all of its subtypes. However, some attributes and relationships of the subtype are added to those of the supertype. Subtypes are usefully defined where an identifiable group of entity occurrences has attributes in addition to those of the supertype.
1.3.4.6 Relations
A relation (data relationship) is a natural association that exists between two or more entities. Cardinality defines the number of occurrences of one entity for a single occurrence of the related entity.
The relationship can be identifying or not identifying, and with a cardinality of 1:1 (one-to-one), 1:N (one-to-many), or N:M (many-to-many). A relationship with N:M cardinality is mapped to a reference table in the relational model. An identifying relationship indicates that the relationship is a component of the primary identifier for the target entity.
1.3.4.7 Arcs
An arc is an exclusive relationship group, which is defined such that only one of the relationships can exist for any instance of an entity. For example, a seminar may be able to be taught by a staff member or an external consultant, but not by both. As examples, a seminar for new employees can be taught only by a corporate staff member, while a seminar in using Product XYX can be taught only by an external consultant with special qualifications.
All relations included in an arc should belong to the same entity and should have the same cardinality Any foreign unique identifier (foreign UID) attributes belonging to relationships in an arc should be transferred as Allow Nulls during forward engineering. The meaning of mandatory relationships in an arc is that only one relationship must exist for a given instance of an entity.
To create an arc, do so after creating all the relationships to be included. Select the entity box, select all relationship lines to be included (hold Shift and click each line), and click the New Arc button in the toolbar.
1.3.4.8 Type Substitution
Type substitution is a subclassing mechanism that complements inheritance. Type substitution on the entity level take place only if the following are defined:
-
Supertype/subtype inheritance between two structured types
-
Entities based on the structured types which form a data type inheritance hierarchy (supertype/subtype inheritance)
1.3.4.9 Views
1.3.5 Relational Models
A relational model describes a database in terms of SQL tables, columns, and joins between tables. Each entity that you choose from the logical model is represented as a table in the relational model. Each row in a table represents a specific, individual occurrence of the corresponding entity. Each attribute of an entity is represented by a column in the table.
You can build a relational model in any of the following ways:
-
Manually in Data Modeler
-
By forward engineering from the logical model or a subview of the logical model
-
By importing models from a VAR file, such as those created by at least these versions of the following products: Sterling COOL:DBA V2.1 or Sterling Bsnteam V7.2, Cayenne Bsnteam V7.2
-
By importing an existing model created by Data Modeler
-
By importing an Oracle Designer model
-
By importing DDL files based on an existing database implementation
-
By importing from the data dictionary of a supported database type and version
A relational model combines two kinds of data:
-
One relational diagram, plus an optional set of subviews and auxiliary displays, each associated with the appropriate diagram or subview
-
Relational model object definitions
Subviews are considered as independent diagrams of the relational model, created to represent different subject areas.
A relational model enables you to create and manage object definitions for tables, views, columns, indexes, and foreign keys, and optionally to associate certain relational model objects with database schemas. A relational model can contain one or more physical models.
All relational model objects are displayed in the object browser tree.
1.3.5.1 Relational Diagram and Subviews
The relational diagram contains graphical representations of tables, views, and links between them.
When you are working with a complex relational model, you may want to create subviews, each describing only a section of that model. You can define several relational subviews for a single relational model, and you can assign tables and views to more than one subview. Links (relations) between two tables are displayed on the complete relational model and on relational subviews to which both referenced tables have been assigned.
To create a subview containing specific tables, you can select the desired entities in the logical model diagram, right-click, and select Create Subview from Selected. You can also right-click in the subview and select Add/Remove Elements to add objects to the subview and remove objects from the subview (using the Add/Remove Objects dialog box).
If you import from the data dictionary and select more than one schema to import, a relational model is created for all the schemas and a subview is created for each schema.
There is no difference between performing changes in one of the subviews or in the complete relational model. Any changes made are immediately reflected in the complete relational model and any relevant subviews. However, you can remove tables and views from a subview without deleting them from the complete relational model.
1.3.5.2 Tables
A table is an object in which you want to store information. The structure of table can be defined as a group of columns or as based on structured type from data types model. A table may have candidate keys, one of which can be defined as primary key. Usually, a table is mapped to entity from the logical model.
1.3.5.3 Columns
A table column is a characteristic common to a particular table. The data type of a column can be based on a logical data type, a domain, a distinct type, a collection type, or a structured type, or it can be a reference to structured type. If it is a reference to a structured type, a scope table can be defined. Usually, the columns in a table are mapped to the attributes of the corresponding entity from the logical model.
1.3.5.4 Indexes
An index is an object that consists of an ordered set of pointers to rows in a base table. Each index is based on the values of data in one or more table columns. Defining indexes on frequently searched columns can improve the performance of database applications.
1.3.5.5 Relations
A relation (data relationship) is a natural association that exists between two or more tables. Relationships are expressed in the data values of the primary and foreign keys. Cardinality defines the number of occurrences in one table for a single occurrence in the related table.
An identifying relationship indicates that the relationship is a component of the primary identifier for the target table.
An exclusive relationship (arc) specifies that only one of the relationships can exist for a given instance in the table. For example, a seminar may be able to be taught by a staff member or an external consultant, but not by both. As examples, a seminar for new employees can be taught only by a corporate staff member, while a seminar in using Product XYX can be taught only by an external consultant with special qualifications.
All relationships in an arc should belong to the same table, and should have the same cardinality. Any foreign key (FK) attributes belonging to relationships in an arc should be transferred as Allow Nulls during forward engineering. The meaning of mandatory relationships in an arc is that only one relationship must exist for a given instance in the table.
To create an arc, do so after creating all the relationships to be included. Select the table box, select all relationship lines to be included (hold Shift and click each line), and click the New Arc button in the toolbar.
1.3.5.6 Relational Views
A relational view is a named result set of a SQL query. A view selects the required data from one or more tables into a single virtual set. Views enable you to display different perspectives on the same database.
Related Topics
Working with Data Modeler
Data Modeler Concepts and Usage
1.3.6 Physical Models
A physical model describes a database in terms of Oracle Database objects (tables, views, triggers, and so on) that are based on a relational model. Each relational model can have one or more physical models. The following shows a database design hierarchy with several relational and physical models:
Database design
Logical model
Relational model 1
Physical model 1a
Physical model 1b
. . . (other physical models)
Relational model 2
Physical model 2a
Physical model 2b
. . . (other physical models)
. . . (other relational models)
Each physical model is based on an RDBMS site object. An RDBMS site is a name associated with a type of database supported by Data Modeler. Several RDBMS sites are predefined (for example, for Oracle 11g and Microsoft SQL Server 2005). You can also use the RDBMS Site Editor dialog box to create user-defined RDBMS sites as aliases for supported types of databases; for example, you might create sites named Test and Production, so that you will be able to generate different physical models and then modify them.
When you export to a DDL file, you specify the physical model to be applied. The generated DDL statements include clauses and keywords appropriate for features specified in that physical model (for example, partitioning for one or more tables).
Physical models do not have graphical representation in the work area; instead, they are displayed in the object browser hierarchy. To create and manage objects in the physical model, use the Physical menu or the context (right-click) menu in the object browser.
The rest of this topic briefly describes various Oracle Database objects, listed in alphabetical order (not the order in which they may appear in an Oracle physical model display).
1.3.6.1 Clusters
A cluster is a schema object that contains data from one or more tables.
-
An index cluster must contain more than one cluster, and all of the tables in the cluster have one or more columns in common. Oracle Database stores together all the rows from all the tables that share the same cluster key.
-
In a hash cluster, which can contain one or more tables, Oracle Database stores together rows that have the same hash key value.
1.3.6.2 Contexts
A context is a set of application-defined attributes that validates and secures an application.
1.3.6.3 Dimensions
A dimension defines a parent-child relationship between pairs of column sets, where all the columns of a column set must come from the same table. However, columns in one column set (called a level) can come from a different table than columns in another set. The optimizer uses these relationships with materialized views to perform query rewrite. The SQL Access Advisor uses these relationships to recommend creation of specific materialized views.
1.3.6.4 Directories
A directory is an alias for a directory (called a folder on Windows systems) on the server file system where external binary file LOBs (BFILEs) and external table data are located.
You can use directory names when referring to BFILEs in your PL/SQL code and OCI (Oracle Call Interface) calls, rather than hard coding the operating system path name, for management flexibility. All directories are created in a single namespace and are not owned by an individual schema. You can secure access to the BFILEs stored within the directory structure by granting object privileges on the directories to specific users.
1.3.6.5 Disk Groups
A disk group is a group of disks that Oracle Database manages as a logical unit, evenly spreading each file across the disks to balance I/O. Oracle Database also automatically distributes database files across all available disks in disk groups and rebalances storage automatically whenever the storage configuration changes.
1.3.6.6 External Tables
An external table lets you access data in an external source as if it were in a table in the database. To use external tables, you must have some knowledge of the file format and record format of the data files on your platform.
1.3.6.7 Indexes
An index is a database object that contains an entry for each value that appears in the indexed column(s) of the table or cluster and provides direct, fast access to rows. Indexes are automatically created on primary key columns; however, you must create indexes on other columns to gain the benefits of indexing.
1.3.6.8 Roles
A role is a set of privileges that can be granted to users or to other roles. You can use roles to administer database privileges. You can add privileges to a role and then grant the role to a user. The user can then enable the role and exercise the privileges granted by the role.
1.3.6.9 Rollback Segments
A rollback segment is an object that Oracle Database uses to store data necessary to reverse, or undo, changes made by transactions. Note, however, that Oracle strongly recommends that you run your database in automatic undo management mode instead of using rollback segments. Do not use rollback segments unless you must do so for compatibility with earlier versions of Oracle Database. See Oracle Database Administrator’s Guide for information about automatic undo management.
1.3.6.10 Segments (Segment Templates)
A segment is a set of extents that contains all the data for a logical storage structure within a tablespace. For example, Oracle Database allocates one or more extents to form the data segment for a table. The database also allocates one or more extents to form the index segment for a table.
1.3.6.11 Sequences
A sequence is an object used to generate unique integers. You can use sequences to automatically generate primary key values.
1.3.6.12 Snapshots
A snapshot is a set of historical data for specific time periods that is used for performance comparisons by the Automatic Database Diagnostic Monitor (ADDM). By default, Oracle Database automatically generates snapshots of the performance data and retains the statistics in the workload repository. You can also manually create snapshots, but this is usually not necessary. The data in the snapshot interval is then analyzed by ADDM. For information about ADDM, see Oracle Database Performance Tuning Guide.
1.3.6.13 Stored Procedures
A stored procedure is a schema object that consists of a set of SQL statements and other PL/SQL constructs, grouped together, stored in the database, and run as a unit to solve a specific problem or perform a set of related tasks.
1.3.6.14 Synonyms
A synonym provides an alternative name for a table, view, sequence, procedure, stored function, package, user-defined object type, or other synonym. Synonyms can be public (available to all database users) or private only to the database user that owns the synonym).
1.3.6.15 Structured Types
A structured type is a non-simple data type that associates a fixed set of properties with the values that can be used in a column of a table. These properties cause Oracle Database to treat values of one data type differently from values of another data type. Most data types are supplied by Oracle, although users can create data types.
1.3.6.16 Tables
A table is used to hold data. Each table typically has multiple columns that describe attributes of the database entity associated with the table, and each column has an associated data type. You can choose from many table creation options and table organizations (such as partitioned tables, index-organized tables, and external tables), to meet a variety of enterprise needs.
1.3.6.17 Tablespaces
A tablespace is an allocation of space in the database that can contain schema objects.
-
A permanent tablespace contains persistent schema objects. Objects in permanent tablespaces are stored in data files.
-
An undo tablespace is a type of permanent tablespace used by Oracle Database to manage undo data if you are running your database in automatic undo management mode. Oracle strongly recommends that you use automatic undo management mode rather than using rollback segments for undo.
-
A temporary tablespace contains schema objects only for the duration of a session. Objects in temporary tablespaces are stored in temp files.
1.3.6.18 Users
A database user is an account through which you can log in to the database. (A database user is a database object; it is distinct from any human user of the database or of an application that accesses the database.) Each database user has a database schema with the same name as the user.
1.3.6.19 Views
A view is a virtual table (analogous to a query in some database products) that selects data from one or more underlying tables. Oracle Database provides many view creation options and specialized types of views.
Related Topics
Working with Data Modeler
Data Modeler Concepts and Usage
1.3.7 Business Information
Business information objects define business-oriented information about model objects, such as responsible parties and information about how to contact them, and identification of relevant offline documentation.
A model object can have zero or more business information objects associated with it, and a business information object can be associated with zero or more model objects. For example, a single document can be used to describe many different entities and attributes, or a single person can be the responsible party for multiple events.
There can also be many-to-many relationships among business objects. For example, a responsible party can have multiple sets of contact information (contact objects), and a contact object can be associated with multiple responsible parties. Similarly, one or more telephone, email, location, and URL objects can be associated with multiple contact objects.
The Data Modeler business information model is based on the Object Management Group (OMG) business information package, which is described in the OMG Common Warehouse Metamodel™ (CWM™) Specification, V1.1 as follows: «The Business Information Metamodel provides general purpose services available to all CWM packages for defining business-oriented information about model elements. The business-oriented services described here are designed to support the needs of data warehousing and business intelligence systems; they are not intended as a complete representation of general purpose business intelligence metamodel. Business Information Metamodel services support the notions of responsible parties and information about how to contact them, identification of off-line documentation and support for general-purpose descriptive information.»
The rest of this topic briefly describes business information objects, listed in alphabetical order (not the order in which they appear in the object browser under Business Information).
1.3.7.1 Contacts
A contact object groups the various types of related contact information. Each contact object can be associated with multiple email, location, URL, and telephone objects. Conversely, each email, location, URL, and telephone object can be associated with many contact objects. (See also Contact Properties.)
1.3.7.2 Documents
A document object represents externally stored descriptive information about some aspects of the modeled system. A document object can be associated with one or more model objects. (See also Document Properties.)
1.3.7.3 Emails
An email object identifies a single electronic mail address. Through the use of a contact object, you can associate an email address with one or more responsible parties. The sequence of email objects for a contact might be used to represent the order in which to try email addresses in attempting to communicate with a contact. (See also Email Properties.)
1.3.7.4 Locations
A location object identifies a single physical location. Through the use of a contact object, you can associate a location with one or more responsible parties. The sequence of contact objects for a location might be used to represent the order in which to try contacting a person or group associated with a location. (See also Location Properties.)
1.3.7.5 Resource Locators
A resource locator object provides a general means for describing a resource whose location is not defined by a traditional mailing address. For example, a resource locator could refer to anything from a Web address (such as «www.example.com») to a location within a building (such as «Room 317, third file cabinet, 2nd drawer»). (See also Resource Locator Properties.)
1.3.7.6 Responsible Parties
A responsible party object represents a person, role, or organization that has a responsibility for, or should receive information about, one or more model objects. The precise meaning of the «responsibility» of a responsible object depends on the specific system being implemented. (See also Responsible Party Properties.)
1.3.7.7 Telephones
1.4 Approaches to Data Modeling
When modeling data, you can choose an approach best suited to the nature of the work to be done. The approaches to data modeling include the following: designing a new database, developing a design for an existing database, or performing maintenance on an existing database design
-
Top-Down Modeling: for designing a new database
-
Bottom-Up Modeling: for creating a database based on extracting metadata from an existing database or using the DDL code obtained from an implementation of an existing database
-
Targeted Modeling: for adapting a database to new requirements
1.4.1 Top-Down Modeling
Top-down modeling gathers information about business requirements and the internal environment, and proceeds to define processes, a logical model of the data, one or more relational models, and one or more physical models for each relational model. The steps and information requirements can range from simple to elaborate, depending on your needs. Top-down modeling can involve the following steps, but you can abbreviate or skip steps as appropriate for your needs.
-
Develop the business information.
-
Create documents. In the object browser, right-click Logical and select Properties, then click Documents and add items as appropriate.
-
Create responsible parties with contacts, email addresses, locations, telephone numbers, and locations. In the object browser, right-click Logical and select Properties, then click Responsible Parties and add items as appropriate.
-
Define any other information. In the object browser, right-click Logical and select Properties, then modify other properties (Naming Options, Comments, Notes) as needed.
-
-
Develop the process model, using a data flow diagram. In the object browser under Process Model, right-click Data Flow Diagrams and select New Data Flow Diagram.
-
Create processes. For each process, click the New Process icon, click in the data flow diagram window, and enter information in the Process Properties dialog box.
-
Create external agents. For each external agent, click the New External Agent icon, click in the data flow diagram window, and enter information in the External Agent Properties dialog box.
-
Create information stores. For each process, click the New Information Store icon, click in the data flow diagram window, and enter information in the Information Store Properties dialog box.
-
Create flows with information structures. For each flow, click the New Flow icon, click the starting object (such as a process) in the data flow diagram window, and click the ending object for the flow; then double-click the flow arrow and modify information (as needed) in the Flow Properties dialog box
-
-
Develop the logical model.
-
Create entities, and for each entity its attributes and unique identifiers. You can create all entities first and then the attributes and unique identifiers for each, or you can create the first entity with its attributes and unique identifiers, then the second, and so on.
To create an entity, click the Logical tab, click the New Entity icon, click in the logical model window, and enter information in the Entity Properties dialog box. You can also enter attributes and unique identifiers using the appropriate panes in this dialog box.
-
Create relations between entities. For each relation, click the desired icon: New M:N Relation (many-to-many), New 1:N Relation (one-to-many) , New 1:N Identifying Relation (one-to-many, identifying), or New 1:1 Relation (one-to-one). Click the entity for the start of the relation, and click the entity for the end of the relation; then double-click the relation line and modify information (as needed) in the Relation Properties dialog box.
-
Apply design rules to the logical model. Click Tools, then Design Rules, and use the Design Rules dialog box to check for and fix any violations of the design rules.
-
Forward engineer the logical model to a relational model. Right-click the logical model in the navigator, then select Engineer to Relational Model, and use the Engineering dialog box to generate a relational model reflecting all or a specified subset of objects from the logical model.
-
-
Develop the multidimensional model, if needed.
-
Create cubes.
-
Create levels.
-
Create dimensions.
-
Create links.
-
Apply design rules for the multidimensional model.
-
Export the multidimensional model, as needed.
-
-
Develop one or more relational models, doing the following for each as needed.
-
Split tables. To split one table into two, select the table on the relational model diagram, and click the Split Table button
-
Merge tables. To merge a table into another table (removing the merged table), click the Merge Tables button. Then, in the relational model diagram, first the table into which to merge columns from the other table, and next select the other table whose columns are to me merged. (After the merge, the second table will be removed.)
-
Check design rules for the relational model. Click Tools, then Design Rules.
-
-
Develop one or more physical models for each relational model, doing the following for each.
-
Open a physical model.
-
Check design rules for the physical model. Click Tools, then Design Rules.
-
Generate DDL code, which can be used to generate the actual database objects. Click View, then DDL File Editor, and then use the DDL File Editor dialog box to select a physical model, generate DDL code, and save the code to a script file.
-
1.4.2 Bottom-Up Modeling
Bottom-up modeling builds a database design based on either metadata extracted from an existing database or a file with DDL code that implements an existing database. The resulting database is represented as a relational model and a physical model, and you reverse engineer the logical model from the relational model. Bottom-up modeling can involve the following steps, but you can abbreviate or skip some steps as appropriate for your needs.
-
Generate the relational model in either of the following ways:
-
Extract metadata directly from an existing database: click File, then Import, then Data Dictionary; then follow the instructions for the wizard (see Data Dictionary Import (Metadata Extraction)).
-
Import DDL code that reflects an existing database implementation. Click File, then Import, then DDL File.
-
-
As needed, modify the relational model and create additional relational models.
-
As needed, denormalize the relational model or models. Perform the following steps iteratively, as needed, on each model.
-
Split or merge tables, or do both.
To split one table into two, select the table on the relational model diagram, and click the Split Table button. Use the Split Table wizard to copy or move source foreign keys and columns to the target table (the new table to be created).
To merge a table into another table (removing the merged table), click the Merge Table button. Then, in the relational model diagram, first click the table whose columns are to be merged into the other table, and next click the table into which to merge the columns from the first table that you clicked. (After the merge, the first table that you clicked will be removed, and the remaining table will include its original columns plus the columns that had been in the first table.)
-
Check the design rules for the model. To view the design rules, click Tools, then Design Rules; select the desired relational model; and use the Design Rules dialog box.
-
-
Reverse engineer the logical model from a relational model. Click the Engineer to Logical Model icon, or right-click the relational model, then select Engineer to Logical Model.
-
As needed, modify the logical model.
-
Check design rules for the logical model. Click Tools, then Design Rules.
-
Save the design.
-
Generate DDL code, and use it to create the database implementation. Click View, then DDL File Editor. In the DDL File Editor dialog box, select the physical model and click Generate. Specify any desired DDL Generation Options, then click OK.
1.4.3 Targeted Modeling
Targeted modeling involves maintaining an existing database by adapting it to new requirements.
Note:
Maintaining a database with Data Modeler requires that the design and the actual database implementations be fully synchronized. If you are not sure if this is the case, you should consider the designs outdated and perform the procedures in Bottom-Up Modeling.
Depending on the kind of changes necessary, you can start with the logical model, one or more relational models, or one or more physical models, and then forward engineer or reverse engineer as appropriate.
To start with changes to the logical model:
-
For each logical model object (entity, attribute, relation, and so on) that you want to modify, modify its properties. For example, to add an attribute to an entity:
-
Double-click the entity’s icon in the Logical diagram (or right-click the entity name in the object browser and select Properties).
-
In the Entity Properties dialog box, click Attributes.
-
Click the Add (+) icon and specify the attribute properties.
-
-
When you are finished modifying the logical model, forward engineer the changes to the relational model or models by clicking the Engineer to Relational Model icon or by right-clicking the logical model in the navigator, then selecting Engineer to Relational Model.
-
In the Engineering dialog box, specify any desired filtering, then click Engineer.
To start with changes to a relational model:
-
For each relational model object (table, column, and so on) that you want to modify, modify its properties. For example, to add a column to a table in a relational model:
-
Double-click the table’s icon in the diagram for the relational model (or right-click the table name in the object browser and select Properties).
-
In the Table Properties dialog box, click Columns.
-
Click the Add (+) icon and specify the column properties.
-
-
When you are finished modifying the relational model, reverse engineer the changes to the logical model by clicking the Engineer to Logical Model icon or by right-clicking the relational model name in the navigator, then selecting Engineer to Logical Model.
-
In the Engineering dialog box, specify any desired filtering, then click Engineer.
1.5 User Preferences for Data Modeler
You can customize many aspects of the Data Modeler environment and interface by modifying user preferences according to your personal wishes and needs. To modify the user preferences, select Tools, then Preferences.
Search box: You can enter a string to limit the tree display to matching relevant preference groups.
Most preferences are self-explanatory, and this topic explains only those whose meaning and implications are not obvious. Some preferences involve performance or system resource trade-offs (for example, enabling a feature that adds execution time), and other preferences involve only personal aesthetic taste. The preferences are grouped in the following categories:
-
Environment
-
Data Modeler
-
Format
-
Global Ignore List
-
Mouse Actions
-
Shortcut Keys (Accelerator Keys)
-
SSH (Secure Shell)
-
Versioning
-
Web Browser and Proxy
1.5.1 Environment
The Environment pane contains options that affect the startup and overall behavior and appearance of Data Modeler. You can specify that certain operations be performed automatically at specified times, with the trade-off usually being the extra time for the operation as opposed to the possibility of problems if the operation is not performed automatically (for example, if you forget to perform it when you should).
For example, changes to the undo level (number of previous operations that can be undone) and navigation level (number of open files) values may cause slight increases or decreases in system resource usage.
Automatically Reload Externally Modified Files: If this option is checked, any files open in Data Modeler that have been modified by an external application are updated when you switch back to Data Modeler, overwriting any changes that you might have made. If this option is not checked, changes that you make in Data Modeler overwrite any changes that might have been made by external applications.
Silently Reload When File Is Unmodified: If this option is checked, you are not asked if you want to reload files that have been modified externally but not in Data Modeler. If this option is not checked, you are asked if you want to reload each file that has been modified externally, regardless of whether it has been modified in Data Modeler.
Environment: Dockable Windows
The Dockable Windows pane configures the behavior of dockable windows and the shapes of the four docking areas of Data Modeler: top, bottom, left, and right.
Dockable Windows Always on Top: If this option is checked, dockable windows always remain visible in front of other windows.
Windows Layout: Click the corner arrows to lengthen or shorten the shape of each docking area.
Environment: Log
The Log pane configures the colors of certain types of log messages and the saving of log messages to log files.
Save Logs to File: If this option is checked, all output to the Messages — Log window is saved to log files, where the file name reflects the operation and a timestamp. You are also asked to specify a Log Directory; and if the specified directory does not already exist, it is created. Note that if you save log information to files, the number of these files can become large.
Maximum Log Lines: The maximum number of lines to store in each log file.
Related Topics
User Preferences for Data Modeler
1.5.2 Data Modeler
The Data Modeler pane contains options that affect the startup and overall behavior and appearance of Data Modeler.
Default Designs Directory: The default directory or folder from which to open a design or in which to create a design.
Default Import Directory: The default directory or folder from which to import files.
Show Log After Import: Controls whether a Log window is displayed after an import operation. The window contains informational messages and any warning or error messages.
Default Save Directory: The default directory or folder in which to save files.
Default System Types Directory: The default directory or folder for storing type definition files.
Show «Select Relational Models» Dialog: Controls whether the dialog box for selecting relational models to be included is displayed when you open a Data Modeler design. If this option is disabled, all relational models are included by default when you open a Data Modeler design.
Show Properties Dialog on New Object: Controls whether the Properties dialog box for objects of that type is displayed when you create a new model object.
Use OCI/Thick Driver: For Oracle Database connections, controls whether the oci8 (thick) driver is used by default if it is available, instead of the JDBC (thin) driver.
Reload Last State: Controls whether the last open design is reloaded when Data Modeler is restarted. (Regardless of the setting of this option, you can see any recently open designs by clicking File > Recent Designs.)
Import: Lets you import Data Modeler preferences and other settings that had previously been exported, as explained in Exporting and Importing Preferences and Other Settings.
Export: Saves Data Modeler preferences and other settings to an XML file, so that you can later import the information, as explained in Exporting and Importing Preferences and Other Settings.
Other Data Modeler preferences are grouped into the following categories:
-
DDL
-
Diagram
-
Model
-
Reports
-
Search
-
Third Party JDBC Drivers
1.5.2.1 DDL
The DDL pane contains general options for Data Definition Language (DDL) statements in code to be generated.
Statement Termination Character for DB2 and UDB: Termination character for DDL for IBM DB2 and UDB databases.
Create Type Substitution Triggers for Oracle and UDB: Controls whether triggers are created for type substitutions in Oracle and IBM UDB physical models.
Create Arc Constraints: Controls whether triggers are created in generated DDL code to implement foreign key arc constraints.
Create Triggers for Non Transferable FK: Controls whether triggers are created for non-transferable foreign key relationships. (Whether a foreign key relationship is transferable is controlled by the Transferable (Updatable) option in the Foreign Key Properties dialog box.)
Show CHAR/BYTE Unit for Oracle Varchar2 and Char Types: Controls whether, for attributes of Oracle type CHAR or VARCHAR2, the unit (CHAR or BYTE) associated with the attribute length is included for columns based on the attribute in relational model diagrams and in generated CREATE TABLE statements.
Extended Size for Characters for Oracle: Controls whether the behavior of the MAX_STRING_SIZE = EXTENDED initialization parameter is available when generating DDL: that is, the size limit is 32767 bytes for the VARCHAR2, NVARCHAR2, and RAW data types. A VARCHAR2 or NVARCHAR2 data type with a declared size of greater than 4000 bytes, or a RAW data type with a declared size of greater than 2000 bytes, is an extended data type. Extended data type columns are stored out-of-line, leveraging Oracle’s LOB technology. For more information, see the «Extended Data Types» section of the «Data Types» chapter in Oracle Database SQL Language Reference.
Generate Short Form of NOT NULL Constraint: Controls whether to use a NOT NULL constraint name in column definitions (in CREATE TABLE statements).
Use Quoted Identifiers: Controls whether object names are enclosed in double quotes in the generated DDL statements.
Replace System Names During Import: Controls whether constraint names originally assigned by Oracle Database (such as starting with SYS_) are kept during import operations or are replaced by names assigned by Data Modeler (such as starting with T_PK for a primary key). (For more information, see http://www.thatjeffsmith.com/ask-a-question/#comment-49000.)
Create Domains During Import: Controls whether domains are created from data types during import operations.
Generate Comments in RDBMS: Controls whether Comment in RDBMS text is included in the generated DDL statements
Generate Inline Column Check Constraints: Controls whether the column check constraint clause is included inline (in the CREATE TABLE statement) or as separate constraint definition (in an ALTER TABLE statement).
Include Default Settings in DDL: Controls whether default keywords are included in the generated DDL statements when you have not specified a corresponding setting. This option is useful if you want to see every keyword that will be used in the generated statements.
Include Logging in DDL: Controls whether logging information is included in the generated DDL statements.
Include Schema in DDL: Controls whether object names are prefixed with the schema name (for example, SCOTT.EMP as opposed to just EMP) in the generated DDL statements.
Include Storage in DDL: Controls whether storage information is included in the generated DDL statements.
Include Tablespace in DDL: Controls whether tablespace information is included in the generated DDL statements.
Include Redaction in DDL: Controls whether data redaction information is included in the generated DDL statements.(You should understand the concepts and techniques for redaction, as explained in the «Using Transparent Sensitive Data Protection» chapter in Oracle Database Security Guide.
Include Sensitive Data Protection in DDL: Controls whether information about sensitive data is included in the generated DDL statements. (You should understand the concepts and techniques for redaction and sensitive data protection, as explained in the «Using Transparent Sensitive Data Protection» chapter in Oracle Database Security Guide.
Include PROMPT Command (for Oracle Only): Controls whether a PROMPT command is included before each DDL statement in the generated DDL statements for an Oracle database. Each PROMPT command displays an informational message about the next statement, enabling someone viewing the output of script execution to follow the progress.
SQL Formatting: Use SQL Developer Formatter: Controls whether SQL formatting uses the SQL Developer defaults or the traditional Data Modeler defaults. (You can try DDL generation with the option on and off to see which DDL output better suits your personal preference.)
Default DDL Files Export Directory: Default directory in which generated DDL files are placed for export operations.
DDL: DDL/Comparison
Lets you specify things to be considered or ignored in comparisons.
Use ‘Data Type Kind’ Property in Compare Functionality: Controls whether the data type kind (such as domain, logical type, or distinct type) should be considered to prevent types of different kinds from generating the same native data type (for example, preventing a domain and a logical type from resulting in Number(7,2)).
Use ‘Schema’ Property in Compare Functionality: Controls whether the schema name associated with an object should be considered when comparing two objects.
Use ‘Columns Order’ Property in Compare Functionality: Controls whether the order of columns should be considered when comparing two tables.
Case Sensitive Names in Compare Functionality: Controls whether the letter case in object names should be considered when comparing two objects.
Include System Names in Compare Functionality: Controls whether system-generated constraint names (generated when a constraint name was not provided in the CREATE or ALTER statement) should be considered when comparing two constraint objects. (For a given constraint definition, the constraint names generated by two different systems will almost certainly be different.)
DDL: DDL/Storage
Lets you specify storage options to be included in DDL for import and export operations. These options affect which clauses and keywords are included.
Including storage options provides produces more detailed DDL statements; this makes it clear exactly what options are in effect, and enables you to edit them in the DDL if you want. Excluding storage options produces more concise DDL statements, which you may find more readable.
Related Topics
User Preferences for Data Modeler
1.5.2.2 Diagram
The Diagram pane contains general options that affect the appearance of model diagrams.
General: Synchronize with Tree: Controls whether the focus on an active diagram is automatically moved to reflect the selection of objects under that model in the object browser.
General: Grid Size: Controls the relative distance between grid points when the grid is shown. (The point units reflect an internal coordinate system used by Data Modeler.)
Diagram: Logical Model
Contains options that apply to the diagram of the logical model.
Notation Type: Notation type: Barker (sometimes called «crow’s foot») or Bachman.
Box-in-Box Presentation for Entity Inheritances: Displays subtypes in a box inside their supertype’s box.
Diagram: Relational Model
Contains options that apply to a diagram of a relational model.
Foreign Key Arrow Direction: Controls whether the arrowhead points toward the primary key or toward the foreign key in foreign key relationship arrows.
Related Topics
User Preferences for Data Modeler
1.5.2.3 Model
The Model pane contains options that apply to several types of models.
Default RDBMS Type: Default database type.
Default RDBMS Site: Default site within the default database type.
Columns and Attributes Defaults: Nulls Allowed: Controls whether new columns and attributes are allowed to have null values. If this option is disabled, new columns and attributes are by default mandatory (value required).
Data Type Compatibility for Foreign Keys: Allow Similar Data Types for Foreign Keys: Controls whether, in a foreign key link, the data types of the two columns must be the same (strict match) or must merely be compatible. If this option is enabled, the data types can be the same or compatible; if it is disabled, the data types must be the same. For example, if one column is Number and the other is Integer, they are compatible; and if character data columns have different maximum lengths, they are compatible.
Preferred Domains and Logical Types: Enables you to limit the values displayed in drop-down lists of domains and logical types. (You can use this feature to prevent such lists from being «cluttered» with domains and logical types that you never specify.) To have a domain or logical type appear in drop-down lists, move it from the Preferred side to the All side.
Model: Logical
Contains options that apply to the logical model.
Relation Cardinality: Source Optional: Controls whether the source entity in a relationship must, by default, contain one or more instances. If this option is enabled, source instances are not required for all relationship types; if this option is disabled, one or more source instances are required for all relationship types.
Relation Cardinality: Target Optional: Controls whether the target entity in a relationship must, by default, contain one or more instances. If this option is enabled, target instances are not required for all relationship types; if this option is disabled, one or more target instances are required for all relationship types.
Primary Key Option for Identifying Relationships: Use and Set First Unique Identifier as Primary Key: Controls whether, by default, the first unique identifier attribute is set as the primary unique identifier when you create an entity.
FK Attribute Name Synchronization: Keep as the Name of the Originating Attribute: Controls whether the supertype or referenced attribute must be used in unique identifier (foreign key) naming. To be able to specify some other name, deselect this option.
FK Attribute Name Synchronization: Comments, Notes — Automatically propagate from PK attribute: Controls whether to inherit comments and notes from the referenced primary key attribute in the definition of foreign key attributes.
Default Surrogate Key Settings: Entity Create Surrogate Key: Controls whether a surrogate primary key is created for entities. If this option is enabled, then by default when a new entity is created, a table will get a surrogate primary key when it is set to a related entity, when it is set to a relationship to use a surrogate key, or when the entity does not have a primary key and a relationship refers to that entity.
Default Surrogate Key Settings: Relationship Use Surrogate Key: If this option is enabled, then by default when a new relationship is created, it is set to use a surrogate key (and foreign key attributes are not maintained), rather than being bound to a specific unique identifier.
Model: Physical
Contains options that apply to a physical model. Different options apply to each supported type of database.
For Oracle, you can specify:
-
Defaults for User and Tablespace for the table
-
Whether to use a Table Template and/or Index Template; and if so, properties of the template to be used when generating tables and indexes.
-
Autoincrement column template options: Names for triggers and sequences (and optionally add variables in the names), and the DDL implementation methods for Auto Increment and IDENTITY.
For information about Oracle Database table and index properties, see the CREATE TABLE and CREATE INDEX statements in Oracle Database SQL Language Reference.
For DB2, you can specify a Naming Rule for several options, and can add a variable to any naming rule string that you enter. For example, for Create TableSpace for Each Table, you might type TBLS_ and then click Add Variable and select {model}, causing each creation or renaming of a table to create or rename a corresponding tablespace to TBLS_ plus the table name.
Model: Relational
Contains options that apply to a relational model.
Delete FK Columns Strategy: Specifies what Data Modeler should do when you attempt to delete a table that has one or more generated foreign key columns (columns in other tables) pointing to it: delete the foreign key columns, do not delete the foreign key columns, or ask to confirm the foreign key column deletions.
For example, using the relational model in Data Modeler Tutorial: Modeling for a Small Database, if you delete the Books table, the Transactions table contains the book_id foreign key column that refers to the primary key of the Books table. Your choice for this option determines what happens to the Transactions.book_id column if you delete the Books table.
Default Foreign Key Delete Rule: Specifies what happens if a user tries to delete a row containing data that is involved in a foreign key relationship:
-
No Action causes an error message to be displayed indicating that deletion is not allowed; the deletion is rolled back.
-
Cascade deletes all rows containing data that is involved in the foreign key relationship.
-
Set Null sets the value to null if all foreign key columns for the table can accept null values.
Allow Columns Reorder During Engineering: If this option is enabled, Data Modeler can reorder the attributes of the associated entity when the table is engineered to the relational model, for example, to place attributes considered more important first. (This behavior can be especially useful with tables that contain many columns.) If this option is not enabled, entity attributes are placed in the same order as their associated columns in the table definition.
Synchronize Remote Objects When Model Is Loaded: If this option is enabled, then when a remote object (object in another model) is dropped into the diagram of a current model, the representation of the remote object is changed (synchronized) whenever the model is loaded to reflect any changes that may have been made to the remote object. If this option is not enabled, the representation of the remote object is not changed in the diagram.
Surrogate Column Data Type: Data type for the surrogate column (unique key that is not the primary key), if a table has a surrogate key.
Database Synchronization: Use Source Connection: If this option is enabled, then if the source and destination connections have different names, the source connection by default is used as a filter for which objects to include in the synchronization. (You can specify differently for specific synchronization operations.)
Database Synchronization: Use Source Schema: If this option is enabled, then if the source and destination schemas have different names, the source schema by default is used as a filter for which objects to include in the synchronization. (You can specify differently for specific synchronization operations.)
Database Synchronization: Use Source Object: If this option is enabled, then if the source and destination objects have different names, the source object by default is used as a filter for which objects to include in the synchronization. (You can specify differently for specific synchronization operations.)
Database Synchronization: Synchronize the Whole Schema: If this option is enabled, then objects that exist in the database but not in the model will appear as new objects when the model is synchronized with database, and will appear as candidates to be deleted from the database when the database is synchronized with the model. If this option is not enabled, only objects that exist in the model are synchronized with database.
Model: Synchronization Physical
Contains options that apply to synchronizing a physical model of a specified database type with its associated relational model.
For each specified type of object, you can specify whether to synchronize it (that is, whether to have changes in the relational model to objects of the specified types be applied automatically in the associated physical models).
Related Topics
User Preferences for Data Modeler
1.5.2.4 Reports
The Reports pane contains options that apply when generating reports.
Company name: Name of the company to appear in the report.
Insert page break between objects: Inserts a page break between objects in the report.
Embed diagrams (HTML and PDF): Embeds all diagrams into the report. Click on an object in a diagram to view its details in the report.
Embed main diagram (HTML and PDF): Embeds only the main diagram into the report.
Generate HTML report TOC in separate file: Generates more than one file such that the table of contents is a separate file. This option is only available for reports in the HTML format.
Include select statement in views reports: Includes the SQL statement used for the query to generate a report based on views.
Group Objects by Schema: Displays the objects in groups based on the schema in the left pane. If this option is not enabled, the objects are displayed in alphabetical order.
Default Reports Directory: The default directory or folder in which to generate Data Modeler Reports. If you do not specify a directory, the default is in datamodeler/reports or datamodeler\reports under the location where you installed Data Modeler. For example, on a Windows system this might be C:\Program Files\datamodeler\datamodeler\reports.
Path to Saxon XSLT 2.0 Jar File: Path to the Saxon 2.0 XSLT processor, if you have downloaded the file and want Data Modeler to use it for generating reports (for example: C:\saxon9.3\saxon9he.jar). If you do not specify this option, Data Modeler uses XSLT 1.0 in report generation. In general, Saxon can handle the generation of much larger reports than XSLT 1.0, especially for PDF. (To read about and download the Saxon XSLT processor, go to http://saxon.sourceforge.net/.)
1.5.2.5 Search
The Search pane contains options that affect the behavior when you use the Find Object (Search) feature
Press Enter to Search: Returns matches (reflecting the search string that you have typed so far) when you press Enter.
Search as You Type: Returns matches after you type the first specified number of characters (symbols). If you continue typing, the matches are automatically updated for each additional character that you type.
Number of initial symbols to ignore: For Search as Your Type, specifies how many characters you can type before possible matches are displayed. (The higher the number, the shorter the list of initial possible matches will probably be for a search; you might find this more convenient and less distracting as you type.)
Search Profiles: You can add and edit search profiles, which let you limit the set of properties of relational and logical model objects to be considered when searching for objects, thus potentially resulting in a shorter, more meaningful set of matches. Clicking the Add icon or double-clicking an existing profile name displays the Search Profile dialog box.
Related Topics
Find Object (Search)
User Preferences for Data Modeler
1.5.2.6 Third Party JDBC Drivers
The Third Party JDBC Drivers pane specifies drivers to be used for connections to third-party (non-Oracle) databases. Data Modeler needs to use a JDBC driver for some operations, such as obtaining metadata from the third-party database.
Oracle does not supply non-Oracle drivers. To access any non-Oracle databases that require the use of drivers other than ODBC/JDBC (which are included in Java), you must download the files for the necessary drivers, and then add them using this pane. To download drivers, use the appropriate link at the third-party site. For example:
-
For Microsoft SQL Server:
http://msdn.microsoft.com/en-us/data/aa937724.aspx -
For IBM DB2/LUW, the IBM Data Server Driver for JDBC and SQLJ at:
http://www-01.ibm.com/software/data/db2/linux-unix-windows/downloads.html
For each driver to be added, click the Add (+) icon and select the path for the driver.
Related Topics
User Preferences for Data Modeler
1.5.3 Format
The Format pane controls how statements are formatted in SQL scripts that are generated. The options include whether to insert space characters or tab characters when you press the Tab key (and how many characters), uppercase or lowercase for keywords and identifiers, whether to preserve or eliminate empty lines, and whether comparable items should be placed on the same line or on separate lines.
The Advanced Format subpane lets you specify more detailed formatting options. It also includes these options:
-
Preview with Current Settings: You specify changes on the left side, and the preview area on the right side reflects the changes.
-
Auto-Detect Formatter Settings: You paste code with the desired formatting into the preview pane on the right side, and SQL Developer adjusts the settings on the left side to reflect what you pasted. (It automatically detects, or autodetects, your setting preferences.)
You can export these settings to a code style profile XML file, and can import settings from a previously exported code style profile file.
The Custom Format subpane lets you further customize your formatting settings. You can also export these settings to a custom formatter program XML file, and you can import settings from a previously exported custom formatter program file.
Related Topics
User Preferences for Data Modeler
1.5.4 Global Ignore List
The Global Ignore List pane specifies filters that determine which files and file types will not be used in any processing.
New Filter: A file name or file type that you want to add to the list of files and file types (in the Filter box) that Data Modeler will ignore during all processing (if the filter is enabled, or checked). You can exclude a particular file by entering its complete file name, such as mumble.txt, or you can exclude all files of the same type by entering a construct that describes the file type, such as *.txt.
Add: Adds the new filter to the list in the Filter box.
Remove: Deletes the selected filter from the list in the Filter box.
Restore Defaults: Restores the contents of the Filter box to the Data Modeler defaults.
Filter: Contains the list of files and file types. For each item, if it is enabled (checked), the filter is enforced and the file or file type is ignored by Data Modeler; but if it is disabled (unchecked), the filter is not enforced.
Related Topics
User Preferences for Data Modeler
1.5.5 Mouse Actions
The Mouse Actions pane specifies text to be displayed on hover-related mouse actions over relevant object names.
Popup Name: The type of information to be displayed: Data Values (value of the item under the mouse pointer, such as the value of a variable), Documentation (documentation on the item under the mouse pointer, such as Javadoc on a method call), or Source (source code of the item under the mouse pointer, such as the source code of a method).
Activate Via: Use action with the mouse cursor to activate the display: Hover, or Hover while pressing one or two specified modifier keys.
Description: Description of the associated Popup Name entry.
Smart Enabled: If this option is checked, then the text for the relevant type of information is displayed if Smart Popup is also checked.
Smart Popup: If this option is checked, the relevant text for the first smart-enabled popup is displayed for the item under the mouse pointer.
Related Topics
Data Modeler
1.5.6 Shortcut Keys (Accelerator Keys)
The Shortcut Keys pane enables you to view and customize the shortcut key (also called accelerator key) mappings for Data Modeler.
Hide Unmapped Commands: If this option is checked, only shortcut keys with mappings are displayed.
More Actions:
-
Export: Exports the shortcut key definitions to an XML file.
-
Import: Imports the shortcut key definitions from a previously exported XML file.
-
Load Keyboard Scheme: Drops all current shortcut key mappings and sets the mappings in the specified scheme. (This option was called Load Preset in previous releases.) If you have made changes to the mappings and want to restore the default settings, select Default.
Category: Lists commands and shortcuts grouped by specific categories (Code Editor, Compare, and so on), to control which actions are displayed.
Command: An action relevant to the specified category. When you select an action, any existing shortcut key mappings are displayed.
Shortcut: Any existing key mappings for the selected action. To remove an existing key mapping, select it and click Remove.
New Shortcut: The new shortcut key to be associated with the action. Press and hold the desired modifier key, then press the other key. For example, to associate Ctrl+J with an action, press and hold the Ctrl key, then press the j key. If any actions are currently associated with that shortcut key, they are listed in the Current Assignment box.
Conflicts: A read-only display of the current action, if any, that is mapped to the shortcut key that you specified in the New Shortcut box.
Related Topics
User Preferences for Data Modeler
1.5.7 SSH (Secure Shell)
SSH preferences are related to creating SSH (Secure Shell) connections.
Use Known Hosts File: If this option is checked, specify the file of known hosts to be used.
Related Topics
User Preferences for Data Modeler
1.5.8 Usage Reporting
In SQL Developer, Data Modeler, and some other applications, the Usage Reporting user preference and a related dialog box ask for your consent to Oracle usage reporting. If you consent, automated reports can occasionally be sent to Oracle describing the product features in use. No personally identifiable information will be sent and the report will not affect performance. You can review Oracle’s privacy policy by clicking the privacy policy link.
Allow automated usage reporting to Oracle: Determines whether you consent to usage reporting.
Related Topics
User Preferences for Data Modeler
1.5.9 Versioning
Versioning preferences affect the behavior of the version control and management systems that you can use with Data Modeler. For information about using versioning with Data Modeler, see Using Versioning.
Versioning: Subversion
The Subversion pane specifies the Subversion client to use with Data Modeler.
Versioning: Subversion: Comment Templates
The Subversion: Comment Templates pane specifies templates for comments to be used with commit operations. For example, a template might contain text like the following:
Problem Description (with bug ID if any): Fix Description:
You can add, edit, and remove comment templates, and you can export templates to an XML file or import templates that had previously been exported.
Versioning: Subversion: General
The Subversion: General pane specifies environment settings and the operation timeout.
Use Navigator State Overlay Icons: If this option is enabled, state overlay icons are used. State overlay icons are small symbols associated with object names in the navigators. They indicate the state of version-controlled files (for example, «up to date»).
Use Navigator State Overlay Labels: If this option is enabled, state overlay labels are used. State overlay labels are tooltips associated with object names in the navigators.
Automatically Add New Files on Committing Working Copy: If this option is enabled, any new files you have created in your working copy are automatically added to the Subversion repository whenever you commit any individual file. Otherwise, Subversion will not add new files when you commit changes; you must continue to add new files to Subversion explicitly.
Automatically Lock Files with svn:needs-lock Property After Checkout: If this option is enabled, files you check out from the repository are automatically locked, preventing other team members from checking them out until you release the files.
Use Merge Wizard for Subversion Merging: If this option is enabled, the Merge wizard rather than the Merge dialog box is invoked for merge requests.
Operation Timeout: Maximum number of seconds, minutes, or hours allowed for Subversion operations to complete.
Edit Subversion Configuration File: To modify the Subversion file directly, click Edit «server». You can make changes to server-specific protocol parameters such as proxy host, proxy port, timeout, compression, and other values. Lines beginning with # are interpreted as comments.
Versioning: Subversion: Version Tools
The Subversion: Version Tools pane specifies options for the pending changes window and the merge editor.
Use Outgoing Changes Commit Dialog: Enables you to make optimum use of limited screen space when the Pending Changes window is open. You can save screen space by not showing the Comments area of the Pending Changes window, but you might still want to add comments before a commit action. You can choose the circumstances under which the Commit dialog is opened: always, only when the Comments area of the Pending Changes window is hidden, or never.
Incoming Changes Timer Interval: The frequency at which the change status of files is checked.
Merge Editor: Specifies whether files are merged locally or at the server.
Related Topics
Using Versioning
Data Modeler
1.5.10 Web Browser and Proxy
The Web Browser and Proxy settings are relevant only when you use the Check for Updates feature (click Help, then Check for Updates), and only if your system is behind a firewall.
Web Browsers
Displays the available web browsers and the default browser for Check for Update operations. You can click under Default to change the default browser.
For each browser, you can determine whether it is the default, and you can see and optionally change its name , the path to the application’s executable file, application command parameters, and the icon.
Proxy Settings
You can choose no proxy, system default proxy settings, or manually specified proxy settings for Check for Update operations. For manually specified settings, check your Web browser options or preferences for the appropriate values for these fields.
Internet Files
You can choose whether to enable Internet cookies for Check for Update operations.
Clear All Cookies: Clears all existing cookies.
Related Topics
User Preferences for Data Modeler
1.6 Saving, Opening, Exporting, and Importing Designs
To store a design (or parts of a design) that you are working on, you can save or export it.
-
Saving a design enables you to save all elements of the design: the logical model, relational models, physical models, process model, and business information. An XML file and a directory structure (described in Database Design) are created for a new design or updated for the existing design, which is stored in Data Modeler format.
To save a design, click File, then Save. If the design was not previously saved, specify the location and XML file name. To save a design in a different file and directory structure. click File, then Save As.
-
Exporting a design enables you to save parts of the design (logical model, relational models but no physical models, and data types model) to a file. You can export in a variety of formats, both non-Oracle and Oracle. Thus, exporting provides flexibility in output formats, but saving enables you to save more design objects if you only need Data Modeler output.
To export a design, click File, then Export, then the output format.
To use a design that had been saved, you can open it by clicking File, then Open. Opening a design makes all models and objects in the saved design available for you to work on. Any saved physical models are not initially visible in the object browser; however, you can make a physical model visible by right-clicking Physical Models under the desired relational model, selecting Open, and then specifying the database type (such as Oracle 11g).
To use a design that had been saved by Data Modeler, or exported or saved by another data modeling tool, you can import it by clicking File, then Import, then the type of design to be imported. Usually, you specify a file, and then use a wizard that enables you to control what is imported.
Any text file that you open or import must be encoded in a format supported by the operating system locale setting. For information about character encoding and locales, see Oracle Database Globalization Support Guide.
The following topics contain information about importing from specific types of files and other sources.
Related Topics
Importing a DDL File
Importing Cube Views Metadata
Importing from Microsoft XMLA
Importing an ERwin File
Importing from a Data Dictionary
Importing an Oracle Designer Model
Importing a Data Modeler Design
Importing a Domain
Select Models/Subviews to Export (for Export > To Data Modeler Design)
1.6.1 Importing a DDL File
Importing a DDL files enables you to create a relational model based on an existing database implementation. DDL files can originate from any supported database type and version. The file to be imported usually has the extension .ddl or .sql.
The import process creates a new relational model with the name of the imported DDL file and opens a physical model reflecting the source site.
1.6.2 Importing Cube Views Metadata
Importing Cube Views metadata enables you to create a multidimensional model based on an existing implementation, as reflected in a specified XML file.
1.6.3 Importing from Microsoft XMLA
Importing from Microsoft XMLA enables you to create a multidimensional model stored in the Microsoft XMLA file format.
1.6.4 Importing an ERwin File
Importing an ERwin file enables you to capture models from the ERwin modeling tool. Specify the XML file containing definitions of the models to be imported.
1.6.5 Importing from a Data Dictionary
Importing from a data dictionary enables you to create a relational model and a physical model based on an existing database implementation. The data dictionary can be from any supported database type and version.
In the wizard for importing from a data dictionary, you must either select an existing database connection or create (add) a new one, and then follow the instructions to select the schema or database and the objects to be imported.
After you import from a data dictionary, you can edit the relational and physical models as needed, and you can reverse engineer the logical model from the relational model.
1.6.6 Importing an Oracle Designer Model
Importing an Oracle Designer model enables you to create a relational model and a physical model based on an existing Oracle Designer model. You can create a connection to an Oracle Designer repository and import the entities, tables, and domains from a workspace in Designer.
In the Import Oracle Designer Model wizard, you must either select an existing database connection or create (add) a new one, and then follow the instructions to select the work areas, application systems, and objects to be imported. (Note that you cannot import Oracle Designer dataflow diagrams.)
After you import the Oracle Designer model, you can edit the relational and physical models as needed, and you can reverse engineer the logical model from the relational model.
1.6.7 Importing a Data Modeler Design
Importing a Data Modeler design enables you to capture the logical model and any relational and data type models from a design previously exported from Data Modeler.
1.6.8 Importing a Domain
Importing a domain enables you to change and extend the existing domain definitions. In the Import Domains dialog box, select the domains to be imported and deselect (clear) the domains not to be imported.
1.7 Exporting and Importing Preferences and Other Settings
You can export and import the following Data Modeler information:
-
User preferences (see User Preferences for Data Modeler)
-
Connections, such as ones you create for importing from a data dictionary (see Data Dictionary Import (Metadata Extraction))
-
Recent designs (shown if you click File, then Recent Designs)
To export this information, click Tools, then Preferences, then Data Modeler, and click Export. Be sure to specify a directory or folder that is not under the location where you installed Data Modeler, because the file will be lost if you later delete the current installation.
To import information that was previously exported, click Tools, then Preferences, then Data Modeler, and click Import.
1.7.1 Restoring the Original Data Modeler Preferences
If you have made changes to Data Modeler preferences but want to restore all to their original default values, you can follow these steps:
- If you are running Data Modeler, exit.
- Delete the folder or directory where your Data Modeler user information is stored. The default location is a build-specific directory or folder under the following:
-
Windows: C:\Documents and Settings\<user-name>\Application Data\Oracle SQL Developer Data Modeler
-
Linux or Mac OS X: ~/.datamodeler
For example, if the current build-specific folder is named
system3.1.0.678, deleteC:\Documents and Settings\<user-name>\Application Data\Oracle SQL Developer Data Modeler\system3.1.0.678. -
- Start Data Modeler.
This creates a folder or directory where your user information is stored (explained in step 2), which has the same content as when Data Modeler was installed.
If you have made changes to the shortcut key (accelerator key) mappings, you can restore the mappings to the defaults for your system by clicking Tools, then Preferences, then Shortcut Keys, then More Actions, then Load Keyboard Scheme, and then selecting Default.
1.8 Data Modeler Reports
1.8.1 Generating Reports as RTF, HTML, or PDF Files
You can save individual reports as RTF (a Microsoft Word format), HTML, or PDF files, and view each report when it is opened automatically on creation and open the files for viewing later. For HTML, several separate files are generated. The files are stored in the location specified or defaulted for Default Reports Directory under Data Modeler preferences.
Data Modeler ensures unique names for each file; for example, if you generate a report on all tables and if AllTablesDetails_1.rtf already exists, AllTablesDetails_2.rtf is created. (If you generate report files from the reporting repository in the reporting schema, the file names include _rs, for example, AllTablesDetails_1_rs.rtf.)
You can generate report files using either of the following approaches:
-
Generate reports based on currently loaded designs. (This approach does not involve creating or using a reporting schema and reporting repository.)
-
Generate reports based on information in the reporting repository in the reporting schema (which are explained in Using the Reporting Repository and Reporting Schema).
To generate and view a report stored in RTF, HTML, PDF, XLS, or XLSX format, follow these steps:
-
Click File, then Reports.
-
In the General tab, for Available Reports, select one of the types of objects for which to report information: Tables, Entities, Domains, Glossaries, and so on.
-
In Output Format, select HTML, PDF, or RTF for standard templates and HTML, PDF, XLS, or XLSX for custom templates.
-
In JVM Options, specify the memory allocation for PDF reports. The default value is -Xmx768M.
-
For Report Title, enter a name for the report.
-
For Report File Name, enter a name for the report file.
-
For Options, see Reports.
-
Under Templates, optionally, select a report template to use. You can use a report template to customize the types of objects to be included in a report. The following tabs are available:
-
Standard: Leave blank to use the default standard report format for the report type, or select an available modified standard format (if any exist). To create and manage standard report types, click Manage to display the Report Templates Management dialog box.
-
Custom: Lets you specify highly customized report formats. To create a new customized report format or to edit a selected existing one, click Manage to display the Report Templates Management dialog box.
For Custom reports, Replace Boolean Values let you select nondefault True and False values.
-
-
Click the Objects tab.
-
Click one of the following tabs (if the desired tab is not already selected):
-
Loaded Designs, to generate a report based on one or more currently loaded Data Modeler designs
-
Reporting Schema, to generate a report based on designs in the reporting repository in the reporting schema
-
-
For Available Designs, select the desired Data Modeler design.
-
For Available Models, select the desired model. (The list of models reflects the type of objects for the report.)
-
For Report Configurations, you can select a configuration to limit the report to specific subviews or specific objects of the selected Available Report type, or you can leave it blank to select all subviews (if any) and all objects of the selected Available Report type.
You can add, delete, or modify configurations by clicking Manage to display the Standard Reports Configurations dialog box.
-
Click Generate Report.
A message is displayed with the location and name of the file for the report.
-
Go to the file and open it.
Related Topics
Data Modeler Reports
1.8.2 Using the Reporting Repository and Reporting Schema
The Data Modeler reporting repository is a collection of database schema objects for storing metadata and data about Data Modeler designs. The schema in which the reporting repository is stored is called the reporting schema.
To set up the Data Modeler reporting schema, perform these steps outside the Data Modeler interface:
-
Create or specify a database schema to hold the reporting repository.
It is recommended that you create a separate database user for the Data Modeler reporting repository, and use that schema only for the reporting repository. For example, create a user named DM_REPORT_REPOS, and grant that user at least CONNECT and RESOURCE privileges. (You can create the reporting repository in an existing schema that is also used for other purposes, but you might find that more confusing to keep track of.)
If you want to continue using a reporting repository from an earlier version of Data Modeler, see the
Reporting_Schema_Upgrade_readme.txtfile in thedatamodeler\datamodeler\reportsfolder. -
Edit and run the
Reporting_Schema_Permissions.sqlscript file, which is located in thedatamodeler\datamodeler\reportsfolder.Before running the script, edit the file to replace <USER> and <OS DIRECTORY> with desired values:
-
<USER> is the schema to hold the reporting repository.
-
<OS DIRECTORY> is a temporary file system folder (directory) on the computer where the database is running. The script will create the definition in the database, but you must create this folder after you run the script.
-
Then, start Data Modeler and perform these steps:
-
Click File, then Export, then To Reporting Schema.
-
In the Export to Reporting Schema dialog box, click the Add Connection (+) icon.
-
In the New/Update Database Connection dialog box, enter a name for the connection (for example,
dm_reporting_repos_conn), as well as the other information for the connection , including the user name and password for the database user associated with the reporting schema. -
Optionally, click Test to test the connection. (If the test is not successful, correct any errors.)
-
Click OK to create the connection and to close the New/Update Database Connection dialog box.
-
Select (click) the connection name in the list of connections near the top of the dialog box.
-
Click OK to create the reporting repository in the schema associated with the selected connection, and to have the information about the selected models exported to that repository.
To see the Data Modeler reports, use SQL Developer, as explained in Using SQL Developer to View Exported Reporting Schema Data.
To delete an existing reporting repository, follow these steps in Data Modeler:
-
Click File, then Export, then To Reporting Schema.
-
Select the connection for the schema associated with the reporting repository to be deleted.
-
In the Export to Reporting Schema dialog box, click the Maintenance tab.
-
Click Drop Repository, then confirm that you want to drop the reporting repository.
If you only want to deleted selected designs within the repository and not the entire repository, click Delete Designs and select the designs to be deleted.
For glossaries, you can perform the following operations using the Glossary tab of the Export to Reporting Schema dialog box:
-
Export Glossary: Enables you to specify a Data Modeler glossary file, to have its information exported to the reporting repository.
-
Delete Glossary: Enables you to select a glossary in the reporting repository, to have its information deleted from the repository.
Note:
datamodeler\datamodeler\reports\Reports_Info.txt for additional technical details about Data Modeler reports.
Related Topics
Data Modeler Reports
1.8.3 Using SQL Developer to View Exported Reporting Schema Data
You can use the reports feature in Oracle SQL Developer to view information that has been exported to the Data Modeler reporting repository. To export the information about a design to the reporting repository, follow the instructions in Using the Reporting Repository and Reporting Schema.
To view the reports in SQL Developer, you must do the following:
-
In SQL Developer, check to see if the Reports navigator already includes a child node named Data Modeler Reports. If it does include that node, go to the next step; if it does not include that node, install the Data Modeler Reports extension, as follows:
Click Help, then Check for Updates. In the Check for Updates wizard, specify Install From Local File, and specify the following local file in the location where you installed Data Modeler: datamodeler\reports\oracle.sqldeveloper.datamodeler_reports.nn.nn.zip (Windows systems) or datamodeler/reports/oracle.sqldeveloper.datamodeler_reports.nn.nn.zip (Linux systems), where nn.nn reflects a build number.
-
In SQL Developer, open the Reports navigator, expand the Data Modeler Reports node, plus nodes under it as desired.
For each report that you want to view:
-
Double-click the node for the report name.
-
Select the database connection that you used for the reporting repository.
-
Complete the Bind Variables dialog information, and click OK. For the bind variables, the default values represent the most typical case: display all available information for the most recent version of the design.
The bind variables enable you to restrict the output. The default value for most bind variables is null, which implies no further restrictions. To specify a bind variable, select the variable name and type an entry in the Value field. Any bind variable values that you enter are case insensitive. Bind variable values can contain the special characters
%(percent sign) to mean any string and_(underscore) to mean any character.
Data Modeler reports are grouped in the following categories:
Design Content reports list information about the design content (objects in the design).
Design Rules reports list information about the design rules as they apply to the logical and relational models.
1.8.3.1 Design Content reports
1.8.3.2 Design Rules reports
Design Rules reports list information about the design rules as they apply to the logical and relational models. (See the information about the Design Rules dialog box.)
Logical Model: Contains reports related to the Logical Model.
Relational Model: Contains reports related to the Relational Models.
Related Topics
Data Modeler Reports
1.9 Using Versioning
Data Modeler provides integrated support for using the Subversion versioning and source control system with Data Modeler designs. You can store designs in a Subversion repository to achieve the usual version control benefits, including:
-
Storing the «official» versions of designs in a central repository instead of in various folders or directories.
-
Enabling multiple developers to work on the same design, coordinating their changes through the traditional Subversion checkout and commit processes.
The Data Modeler documentation does not provide detailed information about SVN concepts and operations; it assumes that you know them or can read about them. For information about Subversion, see http://subversion.tigris.org/. For Subversion documentation, see http://svnbook.red-bean.com/.
To access the versioning features of Data Modeler, use the Team menu.
If you create any versioning repositories or connect to any existing repositories, you can use the hierarchical display of repositories and their contents in the Versions navigator. (If that navigator is not visible, click Team, then Versions.)
Related Topics
About Subversion and Data Modeler
Basic Workflow: Using Subversion with a Design
Data Modeler Concepts and Usage
1.9.1 About Subversion and Data Modeler
Before you can work with a Subversion repository through Data Modeler, you must create a connection to it. When you create a local Subversion repository, a connection to it is automatically created, and this can be seen in the Versions navigator. You can subsequently edit the connection details.
Existing files must be imported into the Subversion repository to bring them under version control. Files are then checked out from the Subversion repository to a local folder known as the «Subversion working copy». Files created in Data Modeler must be stored in the Subversion working copy.
Files newly created within Data Modeler must be added to version control. Changed and new files are made available to other users by committing them to the Subversion repository. The Subversion working copy can be updated with the contents of the Subversion repository to incorporate changes made by other users.
1.9.1.1 Pending Changes
The Pending Changes window is displayed if you click View, then Pending Changes, or when you initiate an action that changes the local source control status of a file. This window shows files that have been added, modified or removed (locally or remotely), files whose content conflicts with other versions of the same file files that have not been added to source control files that are being watched, and files for which editors have been obtained. You can use this information to detect conflicts and to resolve them where possible.
The Outgoing Changes pane shows changes made locally, the Incoming Changes pane shows changes made remotely, and the Candidates pane shows files that have been created locally but not yet added to source control. You can double-click file names to edit them, and you can use the context menu to perform available operations.
1.9.2 Basic Workflow: Using Subversion with a Design
To use Subversion with a Data Modeler design, you must have the following:
-
A folder or directory on your local system to serve as the working directory for the design. You create the design in this working directory, save the design to this working directory, and open the design from this working directory.
-
A Subversion repository to which you can connect, and in which you can create under
branchesa branch for the initial version of the design (and later any subsequent versions).
The following are suggested basic steps. They are not the only possible steps or necessarily the «best» steps for a given project. These steps reflect the use of the Versions navigator and the Import wizard within Data Modeler to perform many actions; however, many actions can alternatively be performed using a separate SVN repository browser (such as the TortoiseSVN browser) and using SVN commands on your local system.
-
On your local system, create a directory or folder to serve as the parent for design-specific working directories. For example, on a Windows PC create:
C:\designs
-
On your local system, create a directory or folder under the one in the preceding step to serve as the working directory for the design you plan to create. For example, for a design to be named
library, create:C:\designs\library
-
In Data Modeler, create the design (for example, the library design in Data Modeler Tutorial: Modeling for a Small Database), and save the design to the working directory that you created. For example, save the design to:
C:\designs\library
Saving the design causes the
.dmdfile and the related directory structure to be created in the working directory. (The.dmdfile and the directory structure are explained in Database Design.) -
Close the design. (Do not exit Data Modeler.)
-
Create an SVN connection to the repository that you want to use.
-
In the Versions navigator, right-click the top-level node (Subversion) and select New Repository Connection.
-
In the Subversion: Create/Edit Subversion Connection dialog box, complete the information. Example repository URL:
https://example.com/svn/designs/
-
-
Create a
branchesdirectory under the repository path.-
In the Versions navigator, right-click the repository path and select New Remote Directory.
-
In the Subversion: Create Remote Directory dialog box, complete the information, specifying the Directory Name as
branches.
-
-
Create a project-specific branch under the
branchesdirectory.-
In the Versions navigator, right-click the
branchesdirectory and select New Remote Directory. -
In the Subversion: Create Remote Directory dialog box, complete the information. Example Directory Name:
libraryFor example, if you plan to create the library design in Data Modeler Tutorial: Modeling for a Small Database, the URL in the repository for this branch might be:
https://example.com/svn/designs/branches/library
-
-
Use the Subversion: Import to Subversion wizard to import the design files into the repository. Click Team, then Import Files, and complete the wizard pages as follows.
-
Destination: Specify the SVN connection and the repository path into which to import the files. Example:
root/branches/library -
Source: Specify the source directory from which to import the files (that is, the directory containing the .dmd file and the design-specific folder hierarchy). Example:
C:\designs\library -
Filters: Accept the defaults and click Next.
-
Options: Accept the defaults and click Next.
-
Summary: View the information and click Finish.
The SVN Console Log shows the progress as files are added. After the files are added, the Handle New Files dialog box is displayed.
-
In the Handle New Files dialog box, select Do Not Open Files and click OK.
-
To see the files that have been added, click the Refresh icon in the Versions navigator tab.
-
For subsequent work on the design, follow the usual workflow for Subversion-based projects (SVN Update, SVN Lock, modify files, SVN Commit).
1.10 For More Information About Data Modeling
See the following for more information, including advanced materials, about data modeling:
-
Data Modeler Start Page, which contains links for tutorials, online demonstrations, documentation, and other resources. This page has two tabs: Get Started and Community. (If the Start Page tab is not visible, click Help, then Start Page).
-
SQL Developer home page (OTN), which includes links for white papers, viewlets (screen demonstrations), Oracle by Example (OBE) tutorials, and other materials:
http://www.oracle.com/technetwork/developer-tools/sql-developer/ -
Object Management Group (OMG) site (
http://www.omg.org/), especially the MetaObject Facility (MOF,http://www.omg.org/mof/) and Common Warehouse Metamodel (CWM,http://www.omg.org/spec/CWM/) specifications -
United States Coast Guard Data Element Naming Standards Guidebook (
http://coastguardinstructions.tpub.com/CI_5230_42A/), especially concepts and recommendations relating to naming standards
Related Topics
Data Modeler Concepts and Usage
In this post you’ll learn:
- how to create a new Entity Relationship Diagram in Oracle SQL Developer
- how to add tables and columns
- how to relate two tables together
Let’s get started.
Oracle SQL Developer includes a tool called Data Modeler that you can use to create and work with ERDs.
You can open this tool by showing the panel with the Data Modeler Objects, which is done by going to View > Data Modeler > Browser.
A Browser panel appears in SQL Developer, which has a range of entry types.

There is a lot of functionality here, but we’ll just cover the basics of creating an ERD.
To do this, we need to create a new Relational Model.
Right-click on the Relational Models type and select New Relational Model.
A new tab is shown with an empty screen.

This looks different to the SQL Editor and includes some toolbar buttons for working with this relational model.
The next step is to add our first table.
Add a Table
To add a table, click on the New Table button on the toolbar, then click anywhere inside the diagram window.
A new window appears that will let you enter data about the new table.

There is a lot of information you can enter here, which makes this tool pretty flexible.
The table has a default name of TABLE_1 but you can (and should) change that.
Change the table name, and click OK.
You’ll be returned to the diagram and the table will be shown as a yellow box on the diagram.

Next, we’ll add some columns.
Double-click on the table and the Table window will open again.
Click on the Columns panel on the left so you can add columns to the table.

Click the green plus button to add a column. Specify the details of the column on the right, such as the name and data type.
You’ll need to change the Data Type to Logical so you’ll get SQL data types in the dropdown.
Once you make changes to the column on the right, you can click on the list of columns to see that your changes have been made.

Click OK, and you’ll see your columns inside the yellow table box on the diagram.

Relate a Second Table
Your ERD will likely need more than one table, so let’s add a second table.
You can do this in the same way as the first table: click the New Table button and click anywhere on the diagram.
We’ll add a second table called car_model, add some columns, and click OK.
The second table is added to the diagram.

How can we link these two tables together?
We can do this by adding a Foreign Key to one of our tables.
Double-click on the table that you want to add the foreign key to. In this example, it’s car_models.
Go to the Foreign Keys tab.

Click on the green plus button to add a new foreign key. A new foreign key is added and named automatically.
Select the referenced table, which in this example is the other table we created.
In the columns list on the left, select the referenced column (the primary key from the other table), as well as the column in this table.
Here’s what it looks like in our example:

Click OK, and the diagram will be updated to show the foreign key on the table, and a line between the two tables to indicate the relationship.

The diagram now has two tables on it and they are related to each other.
Save the ERD File
At any point during your design, you can and should save your file.
To save the file, right-click on the root entry under the Designs folder. In this example, it’s called Untitled_1.

Click Save Design.
Enter a filename for the file and choose a location. Then click Save.
The model file is saved to your computer. The name is also updated in the Browser: in this example, I’ve called the file “SQL Developer model – cars”.

Conclusion
The SQL Developer Data Modeler is a powerful tool, and in this guide, we looked at some of the basics of creating a new ERD.
Hopefully, you found this useful and can use it to create diagrams for your Oracle database.